 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne RNG to Rule Them All: How Randomness Becomes an Attack Vector in Machine Learning
Feb 09, 2026Machine learning relies on randomness as a fundamental component in various steps such as data sampling, data augmentation, weight initialization, and optimization. Most machine learning frameworks use pseudorandom number generators as the source of randomness. However, variations in design choices and implementations across different frameworks, software dependencies, and hardware backends along with the lack of statistical validation can lead to previously unexplored attack vectors on machine learning systems. Such attacks on randomness sources can be extremely covert, and have a history of exploitation in real-world systems. In this work, we examine the role of randomness in the machine learning development pipeline from an adversarial point of view, and analyze the implementations of PRNGs in major machine learning frameworks. We present RNGGuard to help machine learning engineers secure their systems with low effort. RNGGuard statically analyzes a target library's source code and identifies instances of random functions and modules that use them. At runtime, RNGGuard enforces secure execution of random functions by replacing insecure function calls with RNGGuard's implementations that meet security specifications. Our evaluations show that RNGGuard presents a practical approach to close existing gaps in securing randomness sources in machine learning systems.
AnoFel: Supporting Anonymity for Privacy-Preserving Federated Learning
Jun 12, 2023



Federated learning enables users to collaboratively train a machine learning model over their private datasets. Secure aggregation protocols are employed to mitigate information leakage about the local datasets. This setup, however, still leaks the participation of a user in a training iteration, which can also be sensitive. Protecting user anonymity is even more challenging in dynamic environments where users may (re)join or leave the training process at any point of time. In this paper, we introduce AnoFel, the first framework to support private and anonymous dynamic participation in federated learning. AnoFel leverages several cryptographic primitives, the concept of anonymity sets, differential privacy, and a public bulletin board to support anonymous user registration, as well as unlinkable and confidential model updates submission. Additionally, our system allows dynamic participation, where users can join or leave at any time, without needing any recovery protocol or interaction. To assess security, we formalize a notion for privacy and anonymity in federated learning, and formally prove that AnoFel satisfies this notion. To the best of our knowledge, our system is the first solution with provable anonymity guarantees. To assess efficiency, we provide a concrete implementation of AnoFel, and conduct experiments showing its ability to support learning applications scaling to a large number of clients. For an MNIST classification task with 512 clients, the client setup takes less than 3 sec, and a training iteration can be finished in 3.2 sec. We also compare our system with prior work and demonstrate its practicality for contemporary learning tasks.
zPROBE: Zero Peek Robustness Checks for Federated Learning
Jun 24, 2022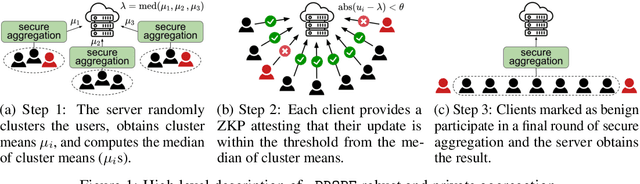
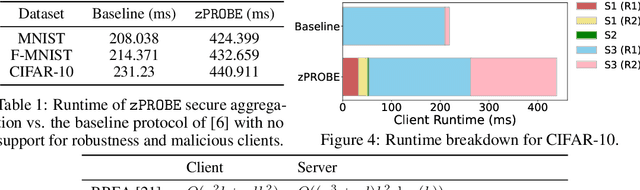
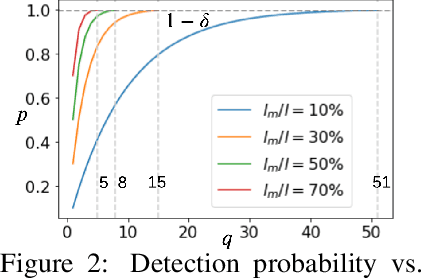
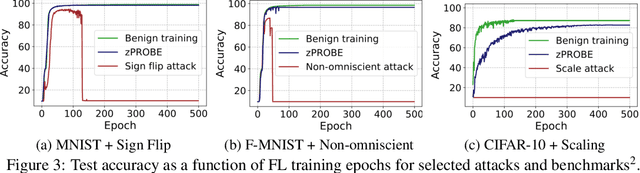
Privacy-preserving federated learning allows multiple users to jointly train a model with coordination of a central server. The server only learns the final aggregation result, thereby preventing leakage of the users' (private) training data from the individual model updates. However, keeping the individual updates private allows malicious users to perform Byzantine attacks and degrade the model accuracy without being detected. Best existing defenses against Byzantine workers rely on robust rank-based statistics, e.g., the median, to find malicious updates. However, implementing privacy-preserving rank-based statistics is nontrivial and unscalable in the secure domain, as it requires sorting of all individual updates. We establish the first private robustness check that uses high break point rank-based statistics on aggregated model updates. By exploiting randomized clustering, we significantly improve the scalability of our defense without compromising privacy. We leverage the derived statistical bounds in zero-knowledge proofs to detect and remove malicious updates without revealing the private user updates. Our novel framework, zPROBE, enables Byzantine resilient and secure federated learning. Empirical evaluations demonstrate that zPROBE provides a low overhead solution to defend against state-of-the-art Byzantine attacks while preserving privacy.
Sphynx: ReLU-Efficient Network Design for Private Inference
Jun 17, 2021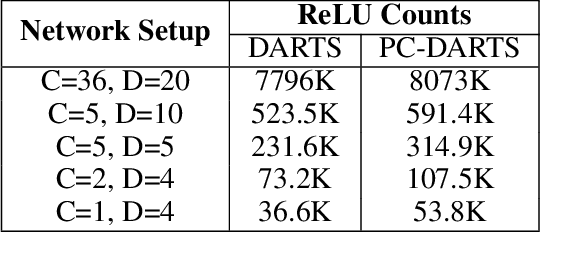


The emergence of deep learning has been accompanied by privacy concerns surrounding users' data and service providers' models. We focus on private inference (PI), where the goal is to perform inference on a user's data sample using a service provider's model. Existing PI methods for deep networks enable cryptographically secure inference with little drop in functionality; however, they incur severe latency costs, primarily caused by non-linear network operations (such as ReLUs). This paper presents Sphynx, a ReLU-efficient network design method based on micro-search strategies for convolutional cell design. Sphynx achieves Pareto dominance over all existing private inference methods on CIFAR-100. We also design large-scale networks that support cryptographically private inference on Tiny-ImageNet and ImageNet.
Circa: Stochastic ReLUs for Private Deep Learning
Jun 15, 2021
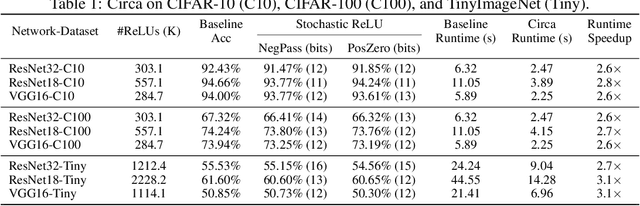
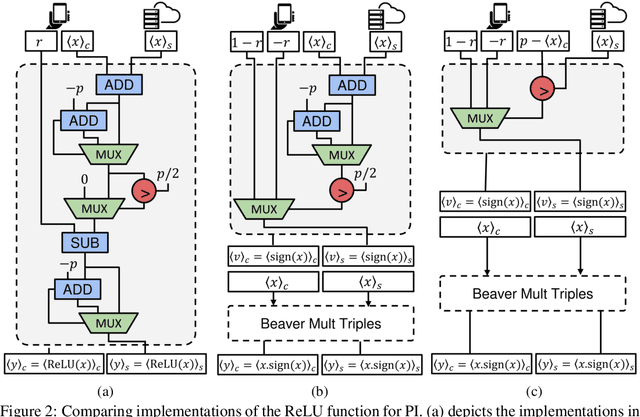
The simultaneous rise of machine learning as a service and concerns over user privacy have increasingly motivated the need for private inference (PI). While recent work demonstrates PI is possible using cryptographic primitives, the computational overheads render it impractical. The community is largely unprepared to address these overheads, as the source of slowdown in PI stems from the ReLU operator whereas optimizations for plaintext inference focus on optimizing FLOPs. In this paper we re-think the ReLU computation and propose optimizations for PI tailored to properties of neural networks. Specifically, we reformulate ReLU as an approximate sign test and introduce a novel truncation method for the sign test that significantly reduces the cost per ReLU. These optimizations result in a specific type of stochastic ReLU. The key observation is that the stochastic fault behavior is well suited for the fault-tolerant properties of neural network inference. Thus, we provide significant savings without impacting accuracy. We collectively call the optimizations Circa and demonstrate improvements of up to 4.7x storage and 3x runtime over baseline implementations; we further show that Circa can be used on top of recent PI optimizations to obtain 1.8x additional speedup.
Generating and Characterizing Scenarios for Safety Testing of Autonomous Vehicles
Mar 12, 2021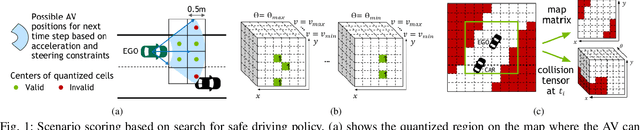
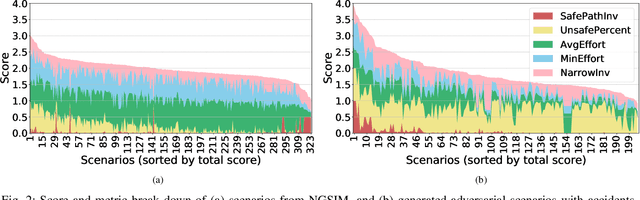
Extracting interesting scenarios from real-world data as well as generating failure cases is important for the development and testing of autonomous systems. We propose efficient mechanisms to both characterize and generate testing scenarios using a state-of-the-art driving simulator. For any scenario, our method generates a set of possible driving paths and identifies all the possible safe driving trajectories that can be taken starting at different times, to compute metrics that quantify the complexity of the scenario. We use our method to characterize real driving data from the Next Generation Simulation (NGSIM) project, as well as adversarial scenarios generated in simulation. We rank the scenarios by defining metrics based on the complexity of avoiding accidents and provide insights into how the AV could have minimized the probability of incurring an accident. We demonstrate a strong correlation between the proposed metrics and human intuition.
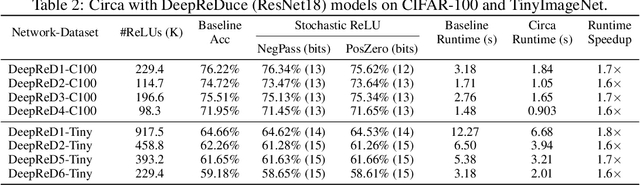
DeepReDuce: ReLU Reduction for Fast Private Inference
Mar 02, 2021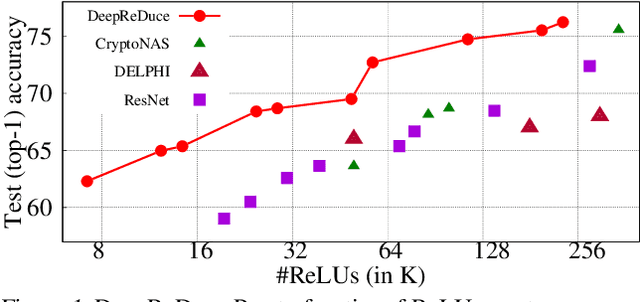
The recent rise of privacy concerns has led researchers to devise methods for private neural inference -- where inferences are made directly on encrypted data, never seeing inputs. The primary challenge facing private inference is that computing on encrypted data levies an impractically-high latency penalty, stemming mostly from non-linear operators like ReLU. Enabling practical and private inference requires new optimization methods that minimize network ReLU counts while preserving accuracy. This paper proposes DeepReDuce: a set of optimizations for the judicious removal of ReLUs to reduce private inference latency. The key insight is that not all ReLUs contribute equally to accuracy. We leverage this insight to drop, or remove, ReLUs from classic networks to significantly reduce inference latency and maintain high accuracy. Given a target network, DeepReDuce outputs a Pareto frontier of networks that tradeoff the number of ReLUs and accuracy. Compared to the state-of-the-art for private inference DeepReDuce improves accuracy and reduces ReLU count by up to 3.5% (iso-ReLU count) and 3.5$\times$ (iso-accuracy), respectively.
CryptoNAS: Private Inference on a ReLU Budget
Jun 15, 2020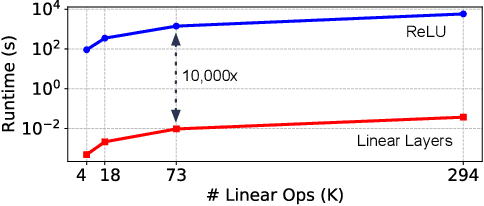

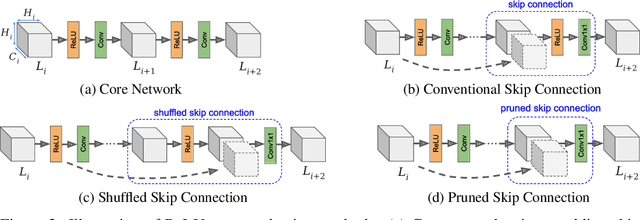

Machine learning as a service has given raise to privacy concerns surrounding clients' data and providers' models and has catalyzed research in private inference (PI): methods to process inferences without disclosing inputs. Recently, researchers have adapted cryptographic techniques to show PI is possible, however all solutions increase inference latency beyond practical limits. This paper makes the observation that existing models are ill-suited for PI and proposes a novel NAS method, named CryptoNAS, for finding and tailoring models to the needs of PI. The key insight is that in PI operator latency cost are non-linear operations (e.g., ReLU) dominate latency, while linear layers become effectively free. We develop the idea of a ReLU budget as a proxy for inference latency and use CryptoNAS to build models that maximize accuracy within a given budget. CryptoNAS improves accuracy by 3.4% and latency by 2.4x over the state-of-the-art.
ThUnderVolt: Enabling Aggressive Voltage Underscaling and Timing Error Resilience for Energy Efficient Deep Neural Network Accelerators
Mar 13, 2018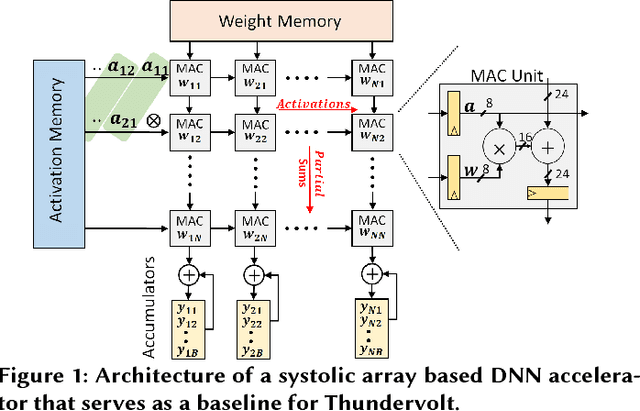
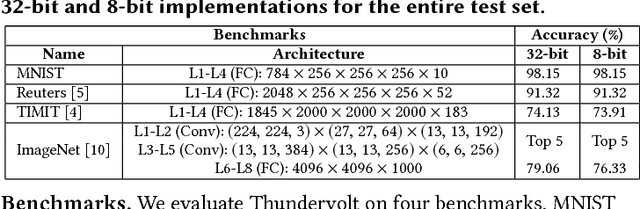
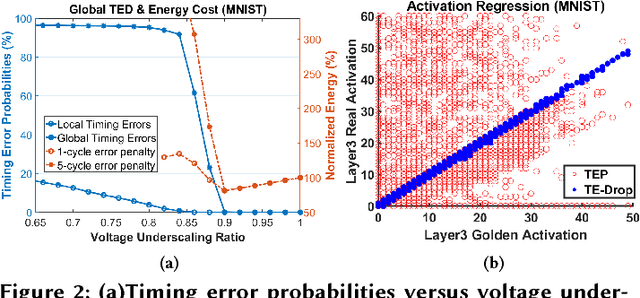
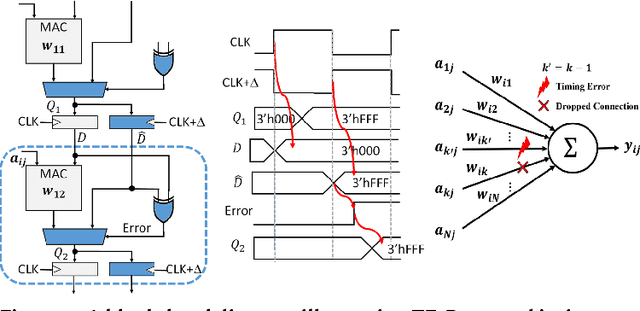
Hardware accelerators are being increasingly deployed to boost the performance and energy efficiency of deep neural network (DNN) inference. In this paper we propose Thundervolt, a new framework that enables aggressive voltage underscaling of high-performance DNN accelerators without compromising classification accuracy even in the presence of high timing error rates. Using post-synthesis timing simulations of a DNN accelerator modeled on the Google TPU, we show that Thundervolt enables between 34%-57% energy savings on state-of-the-art speech and image recognition benchmarks with less than 1% loss in classification accuracy and no performance loss. Further, we show that Thundervolt is synergistic with and can further increase the energy efficiency of commonly used run-time DNN pruning techniques like Zero-Skip.
SafetyNets: Verifiable Execution of Deep Neural Networks on an Untrusted Cloud
Jun 30, 2017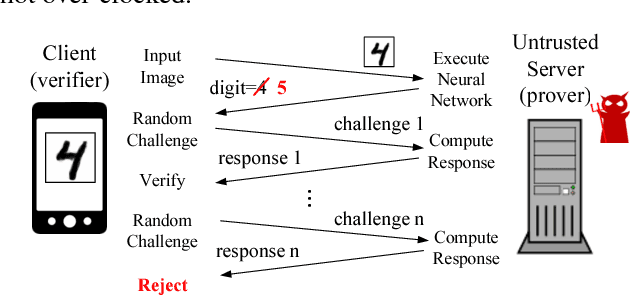
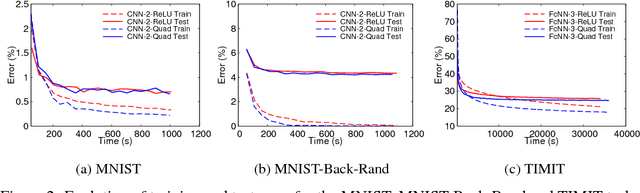

Inference using deep neural networks is often outsourced to the cloud since it is a computationally demanding task. However, this raises a fundamental issue of trust. How can a client be sure that the cloud has performed inference correctly? A lazy cloud provider might use a simpler but less accurate model to reduce its own computational load, or worse, maliciously modify the inference results sent to the client. We propose SafetyNets, a framework that enables an untrusted server (the cloud) to provide a client with a short mathematical proof of the correctness of inference tasks that they perform on behalf of the client. Specifically, SafetyNets develops and implements a specialized interactive proof (IP) protocol for verifiable execution of a class of deep neural networks, i.e., those that can be represented as arithmetic circuits. Our empirical results on three- and four-layer deep neural networks demonstrate the run-time costs of SafetyNets for both the client and server are low. SafetyNets detects any incorrect computations of the neural network by the untrusted server with high probability, while achieving state-of-the-art accuracy on the MNIST digit recognition (99.4%) and TIMIT speech recognition tasks (75.22%).