 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Secure Code Watermarking for Large Language Models via ML/Crypto Codesign
Feb 04, 2025



This paper introduces RoSe, the first-of-its-kind ML/Crypto codesign watermarking framework that regulates LLM-generated code to avoid intellectual property rights violations and inappropriate misuse in software development. High-quality watermarks adhering to the detectability-fidelity-robustness tri-objective are limited due to codes' low-entropy nature. Watermark verification, however, often needs to reveal the signature and requires re-encoding new ones for code reuse, which potentially compromising the system's usability. To overcome these challenges, RoSe obtains high-quality watermarks by training the watermark insertion and extraction modules end-to-end to ensure (i) unaltered watermarked code functionality and (ii) enhanced detectability and robustness leveraging pre-trained CodeT5 as the insertion backbone to enlarge the code syntactic and variable rename transformation search space. In the deployment, RoSe uses zero-knowledge proofs for secure verification without revealing the underlying signatures. Extensive evaluations demonstrated RoSe achieves high detection accuracy while preserving the code functionality. RoSe is also robust against attacks and provides efficient secure watermark verification.
LiveTune: Dynamic Parameter Tuning for Training Deep Neural Networks
Nov 28, 2023



Traditional machine learning training is a static process that lacks real-time adaptability of hyperparameters. Popular tuning solutions during runtime involve checkpoints and schedulers. Adjusting hyper-parameters usually require the program to be restarted, wasting utilization and time, while placing unnecessary strain on memory and processors. We present LiveTune, a new framework allowing real-time parameter tuning during training through LiveVariables. Live Variables allow for a continuous training session by storing parameters on designated ports on the system, allowing them to be dynamically adjusted. Extensive evaluations of our framework show saving up to 60 seconds and 5.4 Kilojoules of energy per hyperparameter change.
NetFlick: Adversarial Flickering Attacks on Deep Learning Based Video Compression
Apr 04, 2023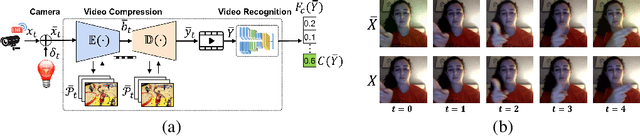
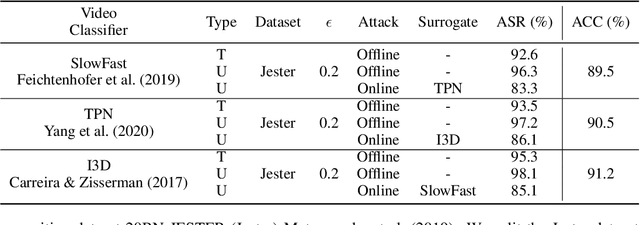
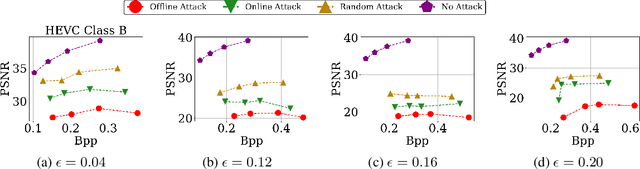
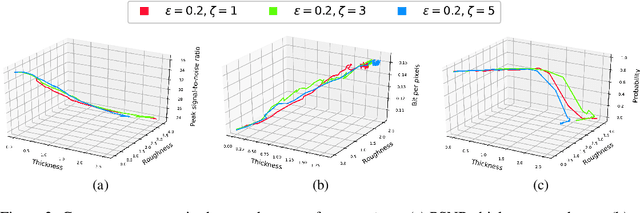
Video compression plays a significant role in IoT devices for the efficient transport of visual data while satisfying all underlying bandwidth constraints. Deep learning-based video compression methods are rapidly replacing traditional algorithms and providing state-of-the-art results on edge devices. However, recently developed adversarial attacks demonstrate that digitally crafted perturbations can break the Rate-Distortion relationship of video compression. In this work, we present a real-world LED attack to target video compression frameworks. Our physically realizable attack, dubbed NetFlick, can degrade the spatio-temporal correlation between successive frames by injecting flickering temporal perturbations. In addition, we propose universal perturbations that can downgrade performance of incoming video without prior knowledge of the contents. Experimental results demonstrate that NetFlick can successfully deteriorate the performance of video compression frameworks in both digital- and physical-settings and can be further extended to attack downstream video classification networks.
Tailor: Altering Skip Connections for Resource-Efficient Inference
Jan 18, 2023



Deep neural networks use skip connections to improve training convergence. However, these skip connections are costly in hardware, requiring extra buffers and increasing on- and off-chip memory utilization and bandwidth requirements. In this paper, we show that skip connections can be optimized for hardware when tackled with a hardware-software codesign approach. We argue that while a network's skip connections are needed for the network to learn, they can later be removed or shortened to provide a more hardware efficient implementation with minimal to no accuracy loss. We introduce Tailor, a codesign tool whose hardware-aware training algorithm gradually removes or shortens a fully trained network's skip connections to lower their hardware cost. The optimized hardware designs improve resource utilization by up to 34% for BRAMs, 13% for FFs, and 16% for LUTs.
FastStamp: Accelerating Neural Steganography and Digital Watermarking of Images on FPGAs
Sep 26, 2022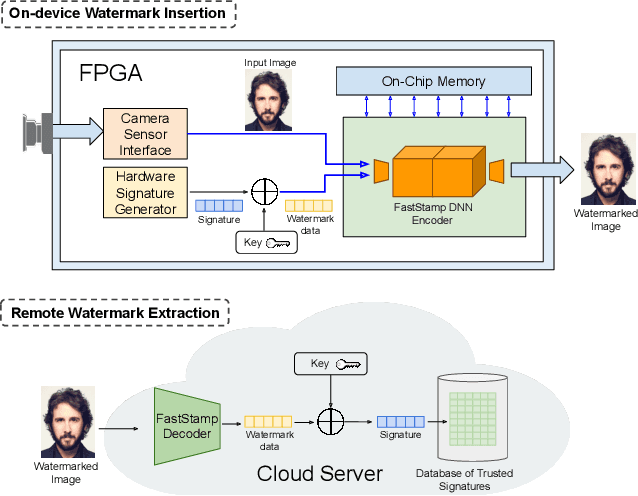
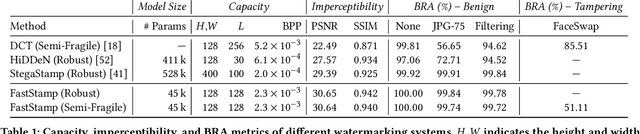
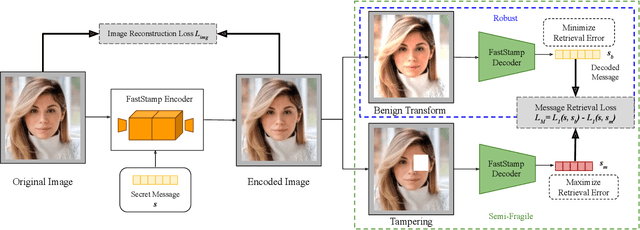

Steganography and digital watermarking are the tasks of hiding recoverable data in image pixels. Deep neural network (DNN) based image steganography and watermarking techniques are quickly replacing traditional hand-engineered pipelines. DNN based watermarking techniques have drastically improved the message capacity, imperceptibility and robustness of the embedded watermarks. However, this improvement comes at the cost of increased computational overhead of the watermark encoder neural network. In this work, we design the first accelerator platform FastStamp to perform DNN based steganography and digital watermarking of images on hardware. We first propose a parameter efficient DNN model for embedding recoverable bit-strings in image pixels. Our proposed model can match the success metrics of prior state-of-the-art DNN based watermarking methods while being significantly faster and lighter in terms of memory footprint. We then design an FPGA based accelerator framework to further improve the model throughput and power consumption by leveraging data parallelism and customized computation paths. FastStamp allows embedding hardware signatures into images to establish media authenticity and ownership of digital media. Our best design achieves 68 times faster inference as compared to GPU implementations of prior DNN based watermark encoder while consuming less power.
zPROBE: Zero Peek Robustness Checks for Federated Learning
Jun 24, 2022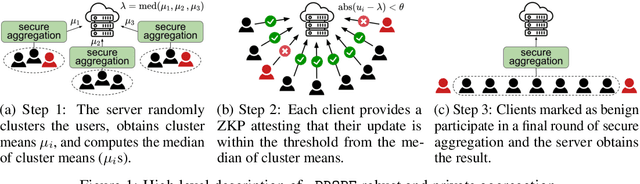
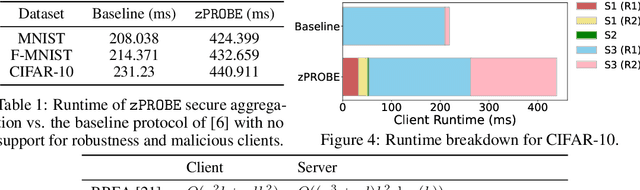
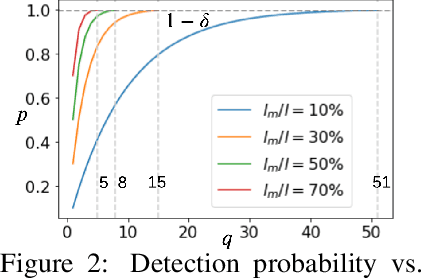
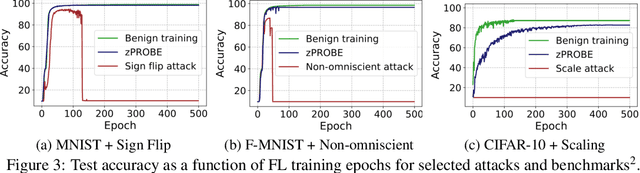
Privacy-preserving federated learning allows multiple users to jointly train a model with coordination of a central server. The server only learns the final aggregation result, thereby preventing leakage of the users' (private) training data from the individual model updates. However, keeping the individual updates private allows malicious users to perform Byzantine attacks and degrade the model accuracy without being detected. Best existing defenses against Byzantine workers rely on robust rank-based statistics, e.g., the median, to find malicious updates. However, implementing privacy-preserving rank-based statistics is nontrivial and unscalable in the secure domain, as it requires sorting of all individual updates. We establish the first private robustness check that uses high break point rank-based statistics on aggregated model updates. By exploiting randomized clustering, we significantly improve the scalability of our defense without compromising privacy. We leverage the derived statistical bounds in zero-knowledge proofs to detect and remove malicious updates without revealing the private user updates. Our novel framework, zPROBE, enables Byzantine resilient and secure federated learning. Empirical evaluations demonstrate that zPROBE provides a low overhead solution to defend against state-of-the-art Byzantine attacks while preserving privacy.