 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Security Map: Holistic Organization of AI Security Technologies and Impacts on Stakeholders
Aug 12, 2025



As the social implementation of AI has been steadily progressing, research and development related to AI security has also been increasing. However, existing studies have been limited to organizing related techniques, attacks, defenses, and risks in terms of specific domains or AI elements. Thus, it extremely difficult to understand the relationships among them and how negative impacts on stakeholders are brought about. In this paper, we argue that the knowledge, technologies, and social impacts related to AI security should be holistically organized to help understand relationships among them. To this end, we first develop an AI security map that holistically organizes interrelationships among elements related to AI security as well as negative impacts on information systems and stakeholders. This map consists of the two aspects, namely the information system aspect (ISA) and the external influence aspect (EIA). The elements that AI should fulfill within information systems are classified under the ISA. The EIA includes elements that affect stakeholders as a result of AI being attacked or misused. For each element, corresponding negative impacts are identified. By referring to the AI security map, one can understand the potential negative impacts, along with their causes and countermeasures. Additionally, our map helps clarify how the negative impacts on AI-based systems relate to those on stakeholders. We show some findings newly obtained by referring to our map. We also provide several recommendations and open problems to guide future AI security communities.
EdgePruner: Poisoned Edge Pruning in Graph Contrastive Learning
Dec 12, 2023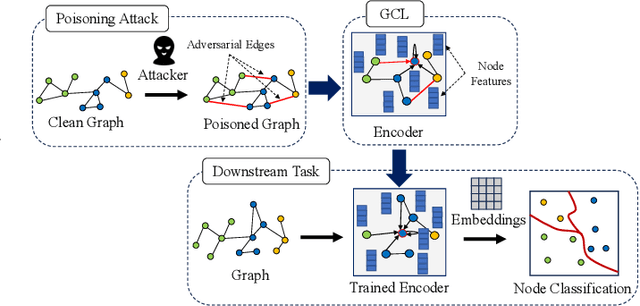
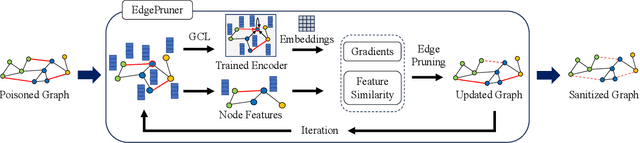
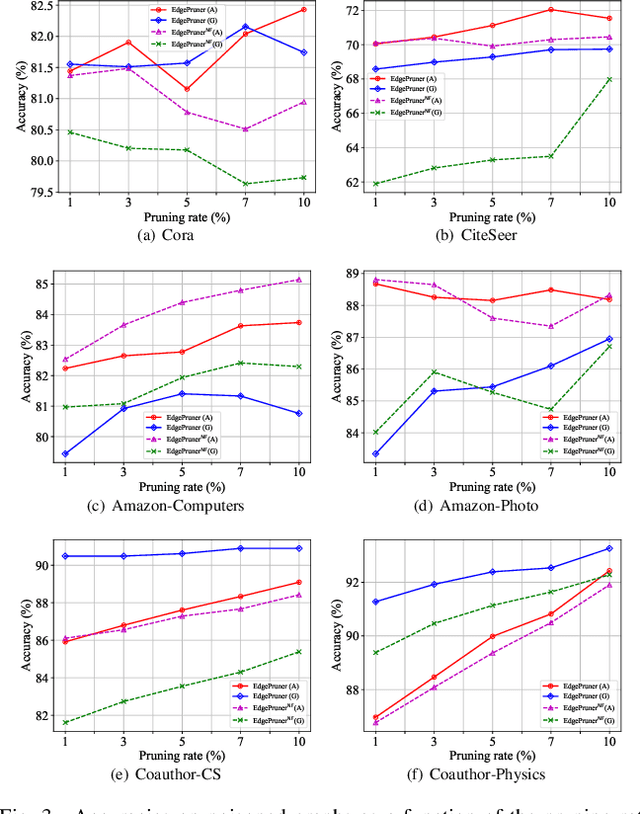
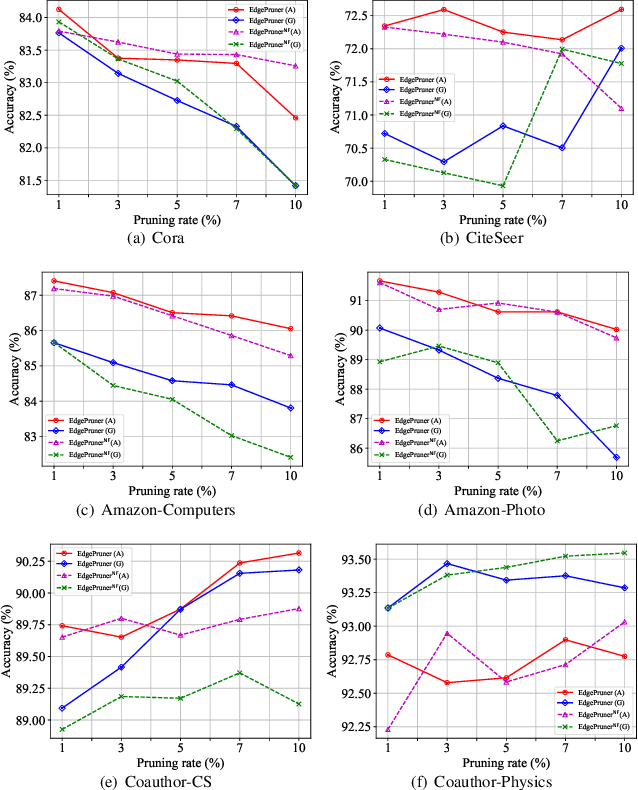
Graph Contrastive Learning (GCL) is unsupervised graph representation learning that can obtain useful representation of unknown nodes. The node representation can be utilized as features of downstream tasks. However, GCL is vulnerable to poisoning attacks as with existing learning models. A state-of-the-art defense cannot sufficiently negate adverse effects by poisoned graphs although such a defense introduces adversarial training in the GCL. To achieve further improvement, pruning adversarial edges is important. To the best of our knowledge, the feasibility remains unexplored in the GCL domain. In this paper, we propose a simple defense for GCL, EdgePruner. We focus on the fact that the state-of-the-art poisoning attack on GCL tends to mainly add adversarial edges to create poisoned graphs, which means that pruning edges is important to sanitize the graphs. Thus, EdgePruner prunes edges that contribute to minimizing the contrastive loss based on the node representation obtained after training on poisoned graphs by GCL. Furthermore, we focus on the fact that nodes with distinct features are connected by adversarial edges in poisoned graphs. Thus, we introduce feature similarity between neighboring nodes to help more appropriately determine adversarial edges. This similarity is helpful in further eliminating adverse effects from poisoned graphs on various datasets. Finally, EdgePruner outputs a graph that yields the minimum contrastive loss as the sanitized graph. Our results demonstrate that pruning adversarial edges is feasible on six datasets. EdgePruner can improve the accuracy of node classification under the attack by up to 5.55% compared with that of the state-of-the-art defense. Moreover, we show that EdgePruner is immune to an adaptive attack.
Magmaw: Modality-Agnostic Adversarial Attacks on Machine Learning-Based Wireless Communication Systems
Nov 01, 2023



Machine Learning (ML) has been instrumental in enabling joint transceiver optimization by merging all physical layer blocks of the end-to-end wireless communication systems. Although there have been a number of adversarial attacks on ML-based wireless systems, the existing methods do not provide a comprehensive view including multi-modality of the source data, common physical layer components, and wireless domain constraints. This paper proposes Magmaw, the first black-box attack methodology capable of generating universal adversarial perturbations for any multimodal signal transmitted over a wireless channel. We further introduce new objectives for adversarial attacks on ML-based downstream applications. The resilience of the attack to the existing widely used defense methods of adversarial training and perturbation signal subtraction is experimentally verified. For proof-of-concept evaluation, we build a real-time wireless attack platform using a software-defined radio system. Experimental results demonstrate that Magmaw causes significant performance degradation even in the presence of the defense mechanisms. Surprisingly, Magmaw is also effective against encrypted communication channels and conventional communications.
VoteTRANS: Detecting Adversarial Text without Training by Voting on Hard Labels of Transformations
Jun 02, 2023
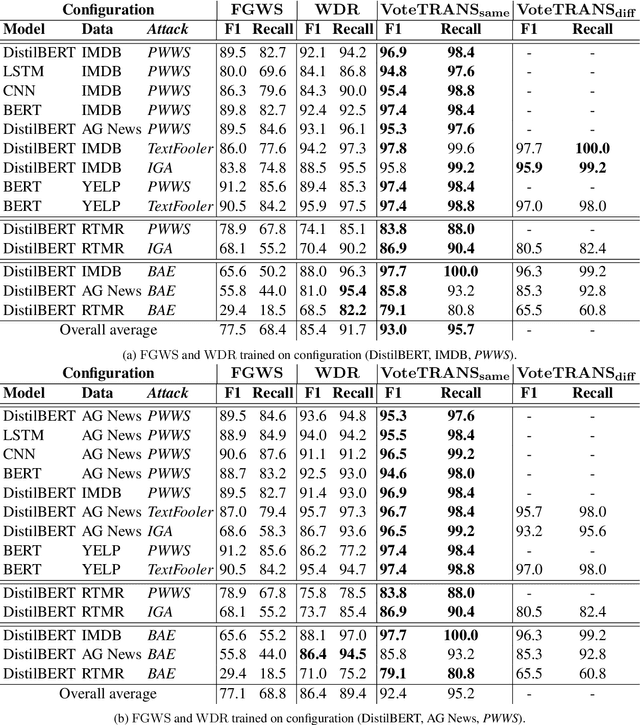
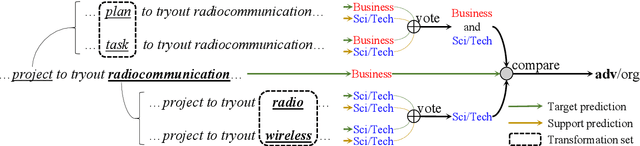

Adversarial attacks reveal serious flaws in deep learning models. More dangerously, these attacks preserve the original meaning and escape human recognition. Existing methods for detecting these attacks need to be trained using original/adversarial data. In this paper, we propose detection without training by voting on hard labels from predictions of transformations, namely, VoteTRANS. Specifically, VoteTRANS detects adversarial text by comparing the hard labels of input text and its transformation. The evaluation demonstrates that VoteTRANS effectively detects adversarial text across various state-of-the-art attacks, models, and datasets.
NetFlick: Adversarial Flickering Attacks on Deep Learning Based Video Compression
Apr 04, 2023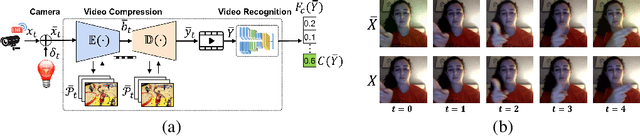
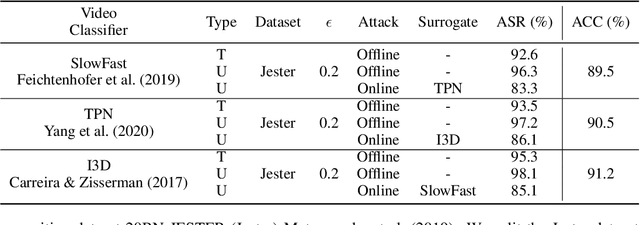
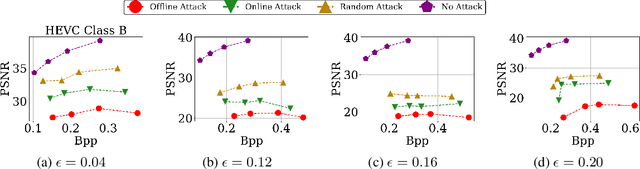
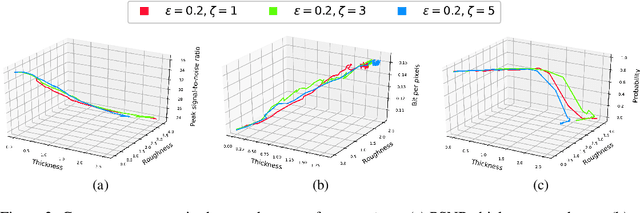
Video compression plays a significant role in IoT devices for the efficient transport of visual data while satisfying all underlying bandwidth constraints. Deep learning-based video compression methods are rapidly replacing traditional algorithms and providing state-of-the-art results on edge devices. However, recently developed adversarial attacks demonstrate that digitally crafted perturbations can break the Rate-Distortion relationship of video compression. In this work, we present a real-world LED attack to target video compression frameworks. Our physically realizable attack, dubbed NetFlick, can degrade the spatio-temporal correlation between successive frames by injecting flickering temporal perturbations. In addition, we propose universal perturbations that can downgrade performance of incoming video without prior knowledge of the contents. Experimental results demonstrate that NetFlick can successfully deteriorate the performance of video compression frameworks in both digital- and physical-settings and can be further extended to attack downstream video classification networks.
Text Revealer: Private Text Reconstruction via Model Inversion Attacks against Transformers
Sep 21, 2022



Text classification has become widely used in various natural language processing applications like sentiment analysis. Current applications often use large transformer-based language models to classify input texts. However, there is a lack of systematic study on how much private information can be inverted when publishing models. In this paper, we formulate \emph{Text Revealer} -- the first model inversion attack for text reconstruction against text classification with transformers. Our attacks faithfully reconstruct private texts included in training data with access to the target model. We leverage an external dataset and GPT-2 to generate the target domain-like fluent text, and then perturb its hidden state optimally with the feedback from the target model. Our extensive experiments demonstrate that our attacks are effective for datasets with different text lengths and can reconstruct private texts with accuracy.
Adversarial Attacks on Deep Learning-based Video Compression and Classification Systems
Mar 18, 2022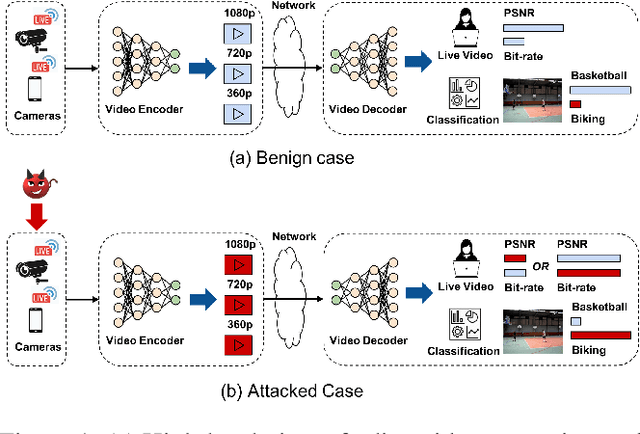
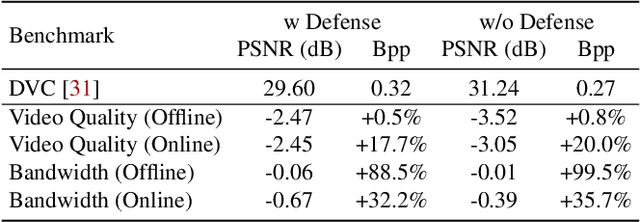
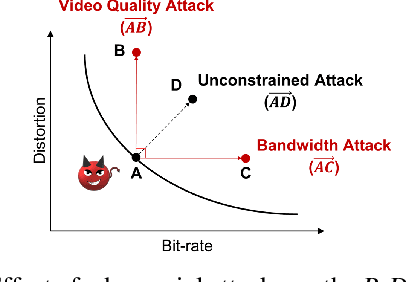
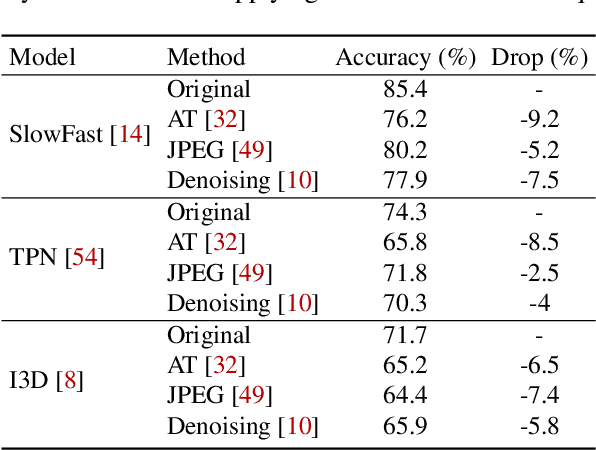
Video compression plays a crucial role in enabling video streaming and classification systems and maximizing the end-user quality of experience (QoE) at a given bandwidth budget. In this paper, we conduct the first systematic study for adversarial attacks on deep learning based video compression and downstream classification systems. We propose an adaptive adversarial attack that can manipulate the Rate-Distortion (R-D) relationship of a video compression model to achieve two adversarial goals: (1) increasing the network bandwidth or (2) degrading the video quality for end-users. We further devise novel objectives for targeted and untargeted attacks to a downstream video classification service. Finally, we design an input-invariant perturbation that universally disrupts video compression and classification systems in real time. Unlike previously proposed attacks on video classification, our adversarial perturbations are the first to withstand compression. We empirically show the resilience of our attacks against various defenses, i.e., adversarial training, video denoising, and JPEG compression. Our extensive experimental results on various video datasets demonstrate the effectiveness of our attacks. Our video quality and bandwidth attacks deteriorate peak signal-to-noise ratio by up to 5.4dB and the bit-rate by up to 2.4 times on the standard video compression datasets while achieving over 90% attack success rate on a downstream classifier.
Degree-Preserving Randomized Response for Graph Neural Networks under Local Differential Privacy
Feb 21, 2022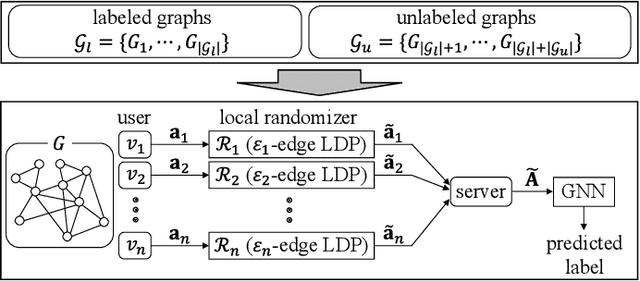
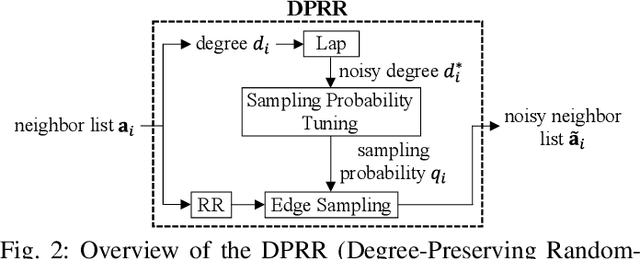
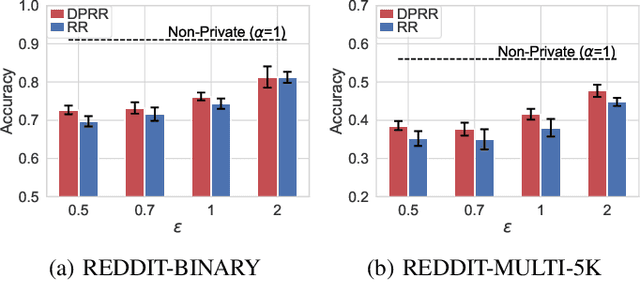
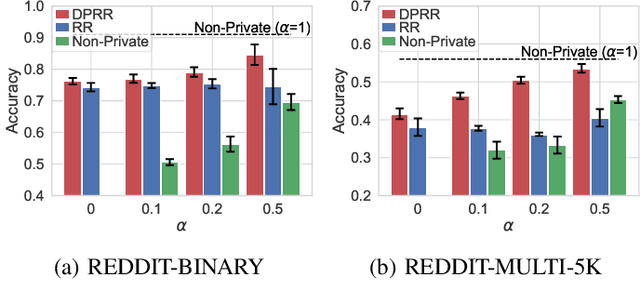
Differentially private GNNs (Graph Neural Networks) have been recently studied to provide high accuracy in various tasks on graph data while strongly protecting user privacy. In particular, a recent study proposes an algorithm to protect each user's feature vector in an attributed graph with LDP (Local Differential Privacy), a strong privacy notion without a trusted third party. However, this algorithm does not protect edges (friendships) in a social graph or protect user privacy in unattributed graphs. It remains open how to strongly protect edges with LDP while keeping high accuracy in GNNs. In this paper, we propose a novel LDP algorithm called the DPRR (Degree-Preserving Randomized Response) to provide LDP for edges in GNNs. Our DPRR preserves each user's degree hence a graph structure while providing edge LDP. Technically, we use Warner's RR (Randomized Response) and strategic edge sampling, where each user's sampling probability is automatically tuned to preserve the degree information. We prove that the DPRR approximately preserves the degree information under edge LDP. We focus on graph classification as a task of GNNs and evaluate the DPRR using two social graph datasets. Our experimental results show that the DPRR significantly outperforms Warner's RR and provides accuracy close to a non-private algorithm with a reasonable privacy budget, e.g., epsilon=1.
SEPP: Similarity Estimation of Predicted Probabilities for Defending and Detecting Adversarial Text
Oct 13, 2021
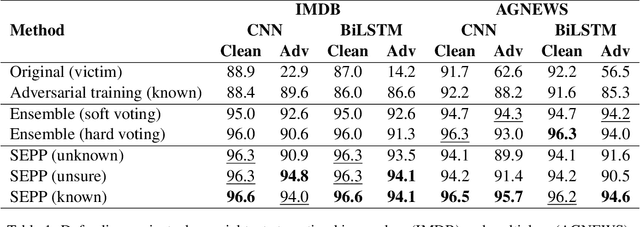
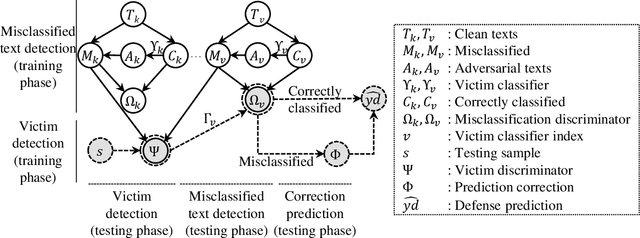
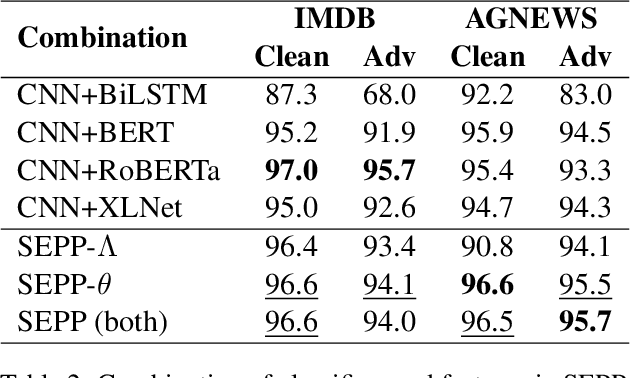
There are two cases describing how a classifier processes input text, namely, misclassification and correct classification. In terms of misclassified texts, a classifier handles the texts with both incorrect predictions and adversarial texts, which are generated to fool the classifier, which is called a victim. Both types are misunderstood by the victim, but they can still be recognized by other classifiers. This induces large gaps in predicted probabilities between the victim and the other classifiers. In contrast, text correctly classified by the victim is often successfully predicted by the others and induces small gaps. In this paper, we propose an ensemble model based on similarity estimation of predicted probabilities (SEPP) to exploit the large gaps in the misclassified predictions in contrast to small gaps in the correct classification. SEPP then corrects the incorrect predictions of the misclassified texts. We demonstrate the resilience of SEPP in defending and detecting adversarial texts through different types of victim classifiers, classification tasks, and adversarial attacks.
TransMIA: Membership Inference Attacks Using Transfer Shadow Training
Nov 30, 2020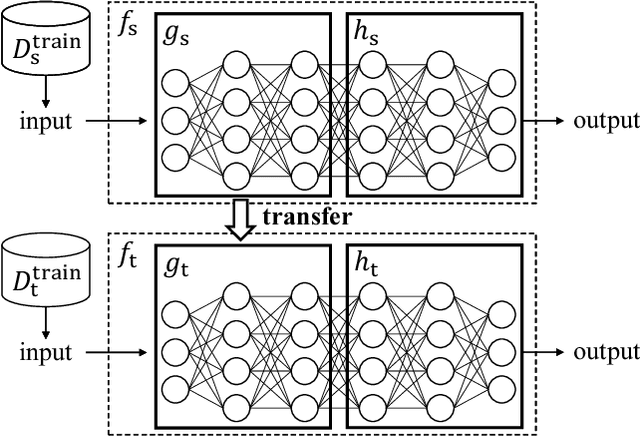
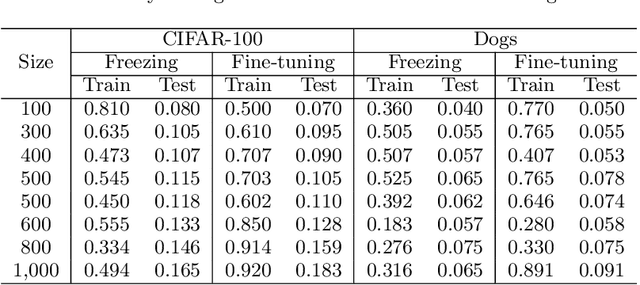
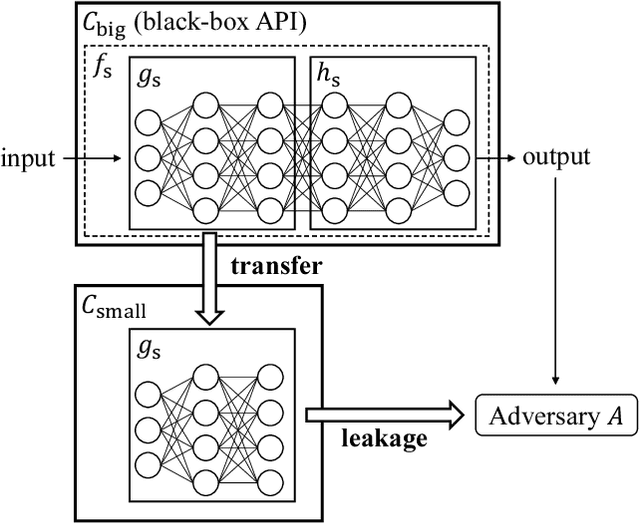
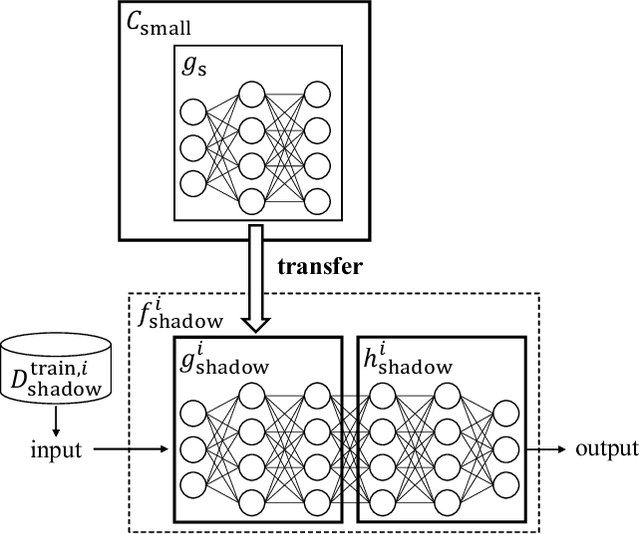
Transfer learning has been widely studied and gained increasing popularity to improve the accuracy of machine learning models by transferring some knowledge acquired in different training. However, no prior work has pointed out that transfer learning can strengthen privacy attacks on machine learning models. In this paper, we propose TransMIA (Transfer Learning-based Membership Inference Attacks), which use transfer learning to perform membership inference attacks on the source model when the adversary is able to access the parameters of the transferred model. In particular, we propose a transfer shadow training technique, where an adversary employs the parameters of the transferred model to construct shadow models, to significantly improve the performance of membership inference when a limited amount of shadow training data is available to the adversary. We evaluate our attacks using two real datasets, and show that our attacks outperform the state-of-the-art that does not use our transfer shadow training technique. We also compare four combinations of the learning-based/entropy-based approach and the fine-tuning/freezing approach, all of which employ our transfer shadow training technique. Then we examine the performance of these four approaches based on the distributions of confidence values, and discuss possible countermeasures against our attacks.