 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWaRL: Safeguard Code Watermarking via Reinforcement Learning
Jan 05, 2026We present SWaRL, a robust and fidelity-preserving watermarking framework designed to protect the intellectual property of code LLM owners by embedding unique and verifiable signatures in the generated output. Existing approaches rely on manually crafted transformation rules to preserve watermarked code functionality or manipulate token-generation probabilities at inference time, which are prone to compilation errors. To address these challenges, SWaRL employs a reinforcement learning-based co-training framework that uses compiler feedback for functional correctness and a jointly trained confidential verifier as a reward signal to maintain watermark detectability. Furthermore, SWaRL employs low-rank adaptation (LoRA) during fine-tuning, allowing the learned watermark information to be transferable across model updates. Extensive experiments show that SWaRL achieves higher watermark detection accuracy compared to prior methods while fully maintaining watermarked code functionality. The LoRA-based signature embedding steers the base model to generate and solve code in a watermark-specific manner without significant computational overhead. Moreover, SWaRL exhibits strong resilience against refactoring and adversarial transformation attacks.
MienCap: Realtime Performance-Based Facial Animation with Live Mood Dynamics
Aug 06, 2025



Our purpose is to improve performance-based animation which can drive believable 3D stylized characters that are truly perceptual. By combining traditional blendshape animation techniques with multiple machine learning models, we present both non-real time and real time solutions which drive character expressions in a geometrically consistent and perceptually valid way. For the non-real time system, we propose a 3D emotion transfer network makes use of a 2D human image to generate a stylized 3D rig parameters. For the real time system, we propose a blendshape adaption network which generates the character rig parameter motions with geometric consistency and temporally stability. We demonstrate the effectiveness of our system by comparing to a commercial product Faceware. Results reveal that ratings of the recognition, intensity, and attractiveness of expressions depicted for animated characters via our systems are statistically higher than Faceware. Our results may be implemented into the animation pipeline, and provide animators with a system for creating the expressions they wish to use more quickly and accurately.
Robust and Secure Code Watermarking for Large Language Models via ML/Crypto Codesign
Feb 04, 2025



This paper introduces RoSe, the first-of-its-kind ML/Crypto codesign watermarking framework that regulates LLM-generated code to avoid intellectual property rights violations and inappropriate misuse in software development. High-quality watermarks adhering to the detectability-fidelity-robustness tri-objective are limited due to codes' low-entropy nature. Watermark verification, however, often needs to reveal the signature and requires re-encoding new ones for code reuse, which potentially compromising the system's usability. To overcome these challenges, RoSe obtains high-quality watermarks by training the watermark insertion and extraction modules end-to-end to ensure (i) unaltered watermarked code functionality and (ii) enhanced detectability and robustness leveraging pre-trained CodeT5 as the insertion backbone to enlarge the code syntactic and variable rename transformation search space. In the deployment, RoSe uses zero-knowledge proofs for secure verification without revealing the underlying signatures. Extensive evaluations demonstrated RoSe achieves high detection accuracy while preserving the code functionality. RoSe is also robust against attacks and provides efficient secure watermark verification.
SimpleFSDP: Simpler Fully Sharded Data Parallel with torch.compile
Nov 01, 2024


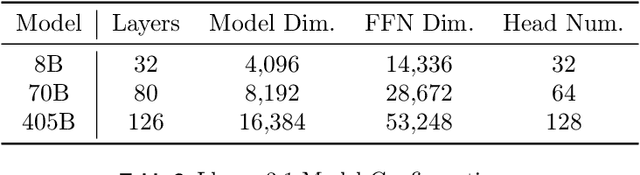
Distributed training of large models consumes enormous computation resources and requires substantial engineering efforts to compose various training techniques. This paper presents SimpleFSDP, a PyTorch-native compiler-based Fully Sharded Data Parallel (FSDP) framework, which has a simple implementation for maintenance and composability, allows full computation-communication graph tracing, and brings performance enhancement via compiler backend optimizations. SimpleFSDP's novelty lies in its unique torch.compile-friendly implementation of collective communications using existing PyTorch primitives, namely parametrizations, selective activation checkpointing, and DTensor. It also features the first-of-its-kind intermediate representation (IR) nodes bucketing and reordering in the TorchInductor backend for effective computation-communication overlapping. As a result, users can employ the aforementioned optimizations to automatically or manually wrap model components for minimal communication exposure. Extensive evaluations of SimpleFSDP on Llama 3 models (including the ultra-large 405B) using TorchTitan demonstrate up to 28.54% memory reduction and 68.67% throughput improvement compared to the most widely adopted FSDP2 eager framework, when composed with other distributed training techniques.
Watermarking Large Language Models and the Generated Content: Opportunities and Challenges
Oct 24, 2024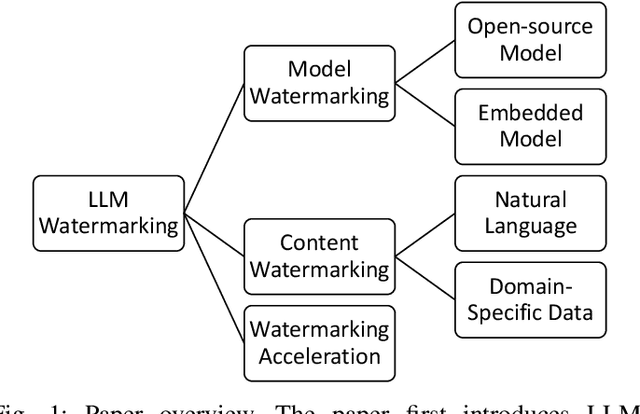



The widely adopted and powerful generative large language models (LLMs) have raised concerns about intellectual property rights violations and the spread of machine-generated misinformation. Watermarking serves as a promising approch to establish ownership, prevent unauthorized use, and trace the origins of LLM-generated content. This paper summarizes and shares the challenges and opportunities we found when watermarking LLMs. We begin by introducing techniques for watermarking LLMs themselves under different threat models and scenarios. Next, we investigate watermarking methods designed for the content generated by LLMs, assessing their effectiveness and resilience against various attacks. We also highlight the importance of watermarking domain-specific models and data, such as those used in code generation, chip design, and medical applications. Furthermore, we explore methods like hardware acceleration to improve the efficiency of the watermarking process. Finally, we discuss the limitations of current approaches and outline future research directions for the responsible use and protection of these generative AI tools.
Transformer-Based Local Feature Matching for Multimodal Image Registration
Apr 25, 2024Ultrasound imaging is a cost-effective and radiation-free modality for visualizing anatomical structures in real-time, making it ideal for guiding surgical interventions. However, its limited field-of-view, speckle noise, and imaging artifacts make it difficult to interpret the images for inexperienced users. In this paper, we propose a new 2D ultrasound to 3D CT registration method to improve surgical guidance during ultrasound-guided interventions. Our approach adopts a dense feature matching method called LoFTR to our multimodal registration problem. We learn to predict dense coarse-to-fine correspondences using a Transformer-based architecture to estimate a robust rigid transformation between a 2D ultrasound frame and a CT scan. Additionally, a fully differentiable pose estimation method is introduced, optimizing LoFTR on pose estimation error during training. Experiments conducted on a multimodal dataset of ex vivo porcine kidneys demonstrate the method's promising results for intraoperative, trackerless ultrasound pose estimation. By mapping 2D ultrasound frames into the 3D CT volume space, the method provides intraoperative guidance, potentially improving surgical workflows and image interpretation.
Token-Specific Watermarking with Enhanced Detectability and Semantic Coherence for Large Language Models
Mar 07, 2024



Large language models generate high-quality responses with potential misinformation, underscoring the need for regulation by distinguishing AI-generated and human-written texts. Watermarking is pivotal in this context, which involves embedding hidden markers in texts during the LLM inference phase, which is imperceptible to humans. Current watermarking algorithms, however, face the challenge of achieving both the detectability of inserted watermarks and the semantic integrity of generated texts, where enhancing one aspect often undermines the other. To overcome this, we introduce a novel multi-objective optimization (MOO) approach for watermarking that utilizes lightweight networks to generate token-specific watermarking logits and splitting ratios. By leveraging MOO to optimize for both detection and semantic objective functions, our method simultaneously achieves detectability and semantic integrity. Experimental results show that our method outperforms current watermarking techniques in enhancing the detectability of texts generated by LLMs while maintaining their semantic coherence. Our code is available at https://github.com/mignonjia/TS_watermark.
EmMark: Robust Watermarks for IP Protection of Embedded Quantized Large Language Models
Feb 27, 2024This paper introduces EmMark,a novel watermarking framework for protecting the intellectual property (IP) of embedded large language models deployed on resource-constrained edge devices. To address the IP theft risks posed by malicious end-users, EmMark enables proprietors to authenticate ownership by querying the watermarked model weights and matching the inserted signatures. EmMark's novelty lies in its strategic watermark weight parameters selection, nsuring robustness and maintaining model quality. Extensive proof-of-concept evaluations of models from OPT and LLaMA-2 families demonstrate EmMark's fidelity, achieving 100% success in watermark extraction with model performance preservation. EmMark also showcased its resilience against watermark removal and forging attacks.
REMARK-LLM: A Robust and Efficient Watermarking Framework for Generative Large Language Models
Oct 18, 2023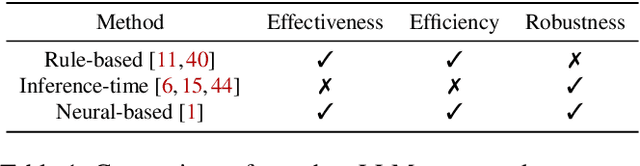
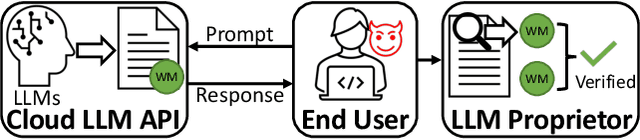
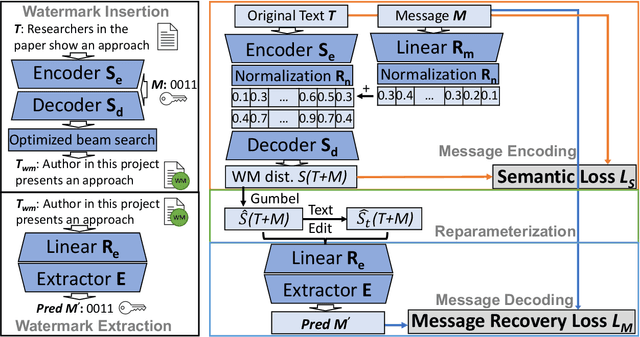
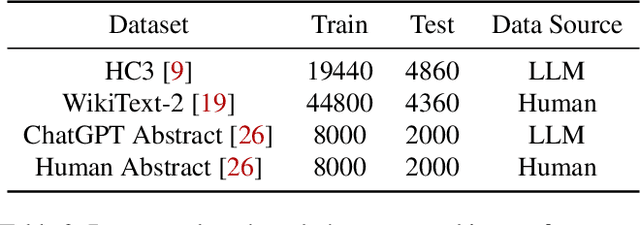
We present REMARK-LLM, a novel efficient, and robust watermarking framework designed for texts generated by large language models (LLMs). Synthesizing human-like content using LLMs necessitates vast computational resources and extensive datasets, encapsulating critical intellectual property (IP). However, the generated content is prone to malicious exploitation, including spamming and plagiarism. To address the challenges, REMARK-LLM proposes three new components: (i) a learning-based message encoding module to infuse binary signatures into LLM-generated texts; (ii) a reparameterization module to transform the dense distributions from the message encoding to the sparse distribution of the watermarked textual tokens; (iii) a decoding module dedicated for signature extraction; Furthermore, we introduce an optimized beam search algorithm to guarantee the coherence and consistency of the generated content. REMARK-LLM is rigorously trained to encourage the preservation of semantic integrity in watermarked content, while ensuring effective watermark retrieval. Extensive evaluations on multiple unseen datasets highlight REMARK-LLM proficiency and transferability in inserting 2 times more signature bits into the same texts when compared to prior art, all while maintaining semantic integrity. Furthermore, REMARK-LLM exhibits better resilience against a spectrum of watermark detection and removal attacks.
XVTP3D: Cross-view Trajectory Prediction Using Shared 3D Queries for Autonomous Driving
Aug 17, 2023Trajectory prediction with uncertainty is a critical and challenging task for autonomous driving. Nowadays, we can easily access sensor data represented in multiple views. However, cross-view consistency has not been evaluated by the existing models, which might lead to divergences between the multimodal predictions from different views. It is not practical and effective when the network does not comprehend the 3D scene, which could cause the downstream module in a dilemma. Instead, we predicts multimodal trajectories while maintaining cross-view consistency. We presented a cross-view trajectory prediction method using shared 3D Queries (XVTP3D). We employ a set of 3D queries shared across views to generate multi-goals that are cross-view consistent. We also proposed a random mask method and coarse-to-fine cross-attention to capture robust cross-view features. As far as we know, this is the first work that introduces the outstanding top-down paradigm in BEV detection field to a trajectory prediction problem. The results of experiments on two publicly available datasets show that XVTP3D achieved state-of-the-art performance with consistent cross-view predictions.