 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIRI-Bench: Challenging VLMs' Spatial Intelligence through Complex Reasoning Tasks
Jun 17, 2025Large Language Models (LLMs) are experiencing rapid advancements in complex reasoning, exhibiting remarkable generalization in mathematics and programming. In contrast, while spatial intelligence is fundamental for Vision-Language Models (VLMs) in real-world interaction, the systematic evaluation of their complex reasoning ability within spatial contexts remains underexplored. To bridge this gap, we introduce SIRI-Bench, a benchmark designed to evaluate VLMs' spatial intelligence through video-based reasoning tasks. SIRI-Bench comprises nearly 1K video-question-answer triplets, where each problem is embedded in a realistic 3D scene and captured by video. By carefully designing questions and corresponding 3D scenes, our benchmark ensures that solving the questions requires both spatial comprehension for extracting information and high-level reasoning for deriving solutions, making it a challenging benchmark for evaluating VLMs. To facilitate large-scale data synthesis, we develop an Automatic Scene Creation Engine. This engine, leveraging multiple specialized LLM agents, can generate realistic 3D scenes from abstract math problems, ensuring faithfulness to the original descriptions. Experimental results reveal that state-of-the-art VLMs struggle significantly on SIRI-Bench, underscoring the challenge of spatial reasoning. We hope that our study will bring researchers' attention to spatially grounded reasoning and advance VLMs in visual problem-solving.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
Enhancing Pre-Trained Model-Based Class-Incremental Learning through Neural Collapse
Apr 25, 2025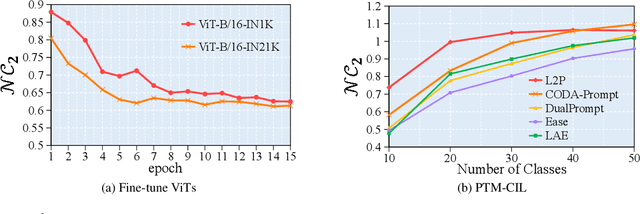
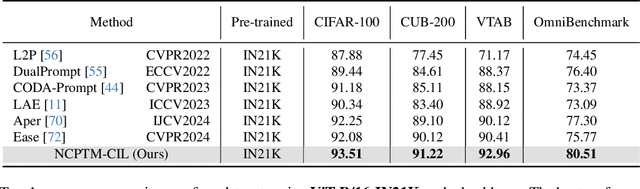
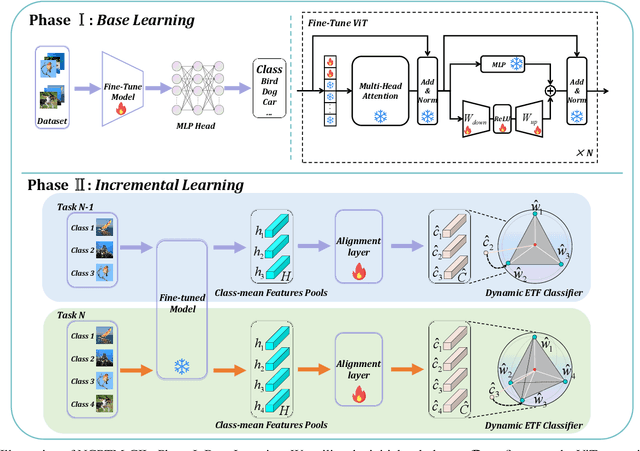

Class-Incremental Learning (CIL) is a critical capability for real-world applications, enabling learning systems to adapt to new tasks while retaining knowledge from previous ones. Recent advancements in pre-trained models (PTMs) have significantly advanced the field of CIL, demonstrating superior performance over traditional methods. However, understanding how features evolve and are distributed across incremental tasks remains an open challenge. In this paper, we propose a novel approach to modeling feature evolution in PTM-based CIL through the lens of neural collapse (NC), a striking phenomenon observed in the final phase of training, which leads to a well-separated, equiangular feature space. We explore the connection between NC and CIL effectiveness, showing that aligning feature distributions with the NC geometry enhances the ability to capture the dynamic behavior of continual learning. Based on this insight, we introduce Neural Collapse-inspired Pre-Trained Model-based CIL (NCPTM-CIL), a method that dynamically adjusts the feature space to conform to the elegant NC structure, thereby enhancing the continual learning process. Extensive experiments demonstrate that NCPTM-CIL outperforms state-of-the-art methods across four benchmark datasets. Notably, when initialized with ViT-B/16-IN1K, NCPTM-CIL surpasses the runner-up method by 6.73% on VTAB, 1.25% on CIFAR-100, and 2.5% on OmniBenchmark.
Neural Collapse Inspired Knowledge Distillation
Dec 16, 2024
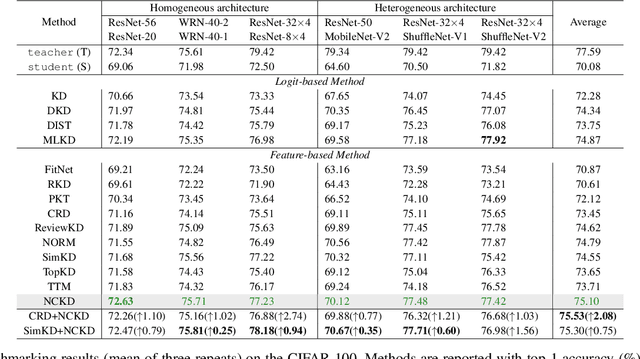


Existing knowledge distillation (KD) methods have demonstrated their ability in achieving student network performance on par with their teachers. However, the knowledge gap between the teacher and student remains significant and may hinder the effectiveness of the distillation process. In this work, we introduce the structure of Neural Collapse (NC) into the KD framework. NC typically occurs in the final phase of training, resulting in a graceful geometric structure where the last-layer features form a simplex equiangular tight frame. Such phenomenon has improved the generalization of deep network training. We hypothesize that NC can also alleviate the knowledge gap in distillation, thereby enhancing student performance. This paper begins with an empirical analysis to bridge the connection between knowledge distillation and neural collapse. Through this analysis, we establish that transferring the teacher's NC structure to the student benefits the distillation process. Therefore, instead of merely transferring instance-level logits or features, as done by existing distillation methods, we encourage students to learn the teacher's NC structure. Thereby, we propose a new distillation paradigm termed Neural Collapse-inspired Knowledge Distillation (NCKD). Comprehensive experiments demonstrate that NCKD is simple yet effective, improving the generalization of all distilled student models and achieving state-of-the-art accuracy performance.
XVTP3D: Cross-view Trajectory Prediction Using Shared 3D Queries for Autonomous Driving
Aug 17, 2023Trajectory prediction with uncertainty is a critical and challenging task for autonomous driving. Nowadays, we can easily access sensor data represented in multiple views. However, cross-view consistency has not been evaluated by the existing models, which might lead to divergences between the multimodal predictions from different views. It is not practical and effective when the network does not comprehend the 3D scene, which could cause the downstream module in a dilemma. Instead, we predicts multimodal trajectories while maintaining cross-view consistency. We presented a cross-view trajectory prediction method using shared 3D Queries (XVTP3D). We employ a set of 3D queries shared across views to generate multi-goals that are cross-view consistent. We also proposed a random mask method and coarse-to-fine cross-attention to capture robust cross-view features. As far as we know, this is the first work that introduces the outstanding top-down paradigm in BEV detection field to a trajectory prediction problem. The results of experiments on two publicly available datasets show that XVTP3D achieved state-of-the-art performance with consistent cross-view predictions.