 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Spatial-Temporal Coherent Correlations for Speech-Preserving Facial Expression Manipulation
Apr 22, 2026Speech-preserving facial expression manipulation (SPFEM) aims to modify facial emotions while meticulously maintaining the mouth animation associated with spoken content. Current works depend on inaccessible paired training samples for the person, where two aligned frames exhibit the same speech content yet differ in emotional expression, limiting the SPFEM applications in real-world scenarios. In this work, we discover that speakers who convey the same content with different emotions exhibit highly correlated local facial animations in both spatial and temporal spaces, providing valuable supervision for SPFEM. To capitalize on this insight, we propose a novel spatial-temporal coherent correlation learning (STCCL) algorithm, which models the aforementioned correlations as explicit metrics and integrates the metrics to supervise manipulating facial expression and meanwhile better preserving the facial animation of spoken content. To this end, it first learns a spatial coherent correlation metric, ensuring that the visual correlations of adjacent local regions within an image linked to a specific emotion closely resemble those of corresponding regions in an image linked to a different emotion. Simultaneously, it develops a temporal coherent correlation metric, ensuring that the visual correlations of specific regions across adjacent image frames associated with one emotion are similar to those in the corresponding regions of frames associated with another emotion. Recognizing that visual correlations are not uniform across all regions, we have also crafted a correlation-aware adaptive strategy that prioritizes regions that present greater challenges. During SPFEM model training, we construct the spatial-temporal coherent correlation metric between corresponding local regions of the input and output image frames as an additional loss to supervise the generation process.
Robotic Manipulation is Vision-to-Geometry Mapping ($f(v) \rightarrow G$): Vision-Geometry Backbones over Language and Video Models
Apr 14, 2026At its core, robotic manipulation is a problem of vision-to-geometry mapping ($f(v) \rightarrow G$). Physical actions are fundamentally defined by geometric properties like 3D positions and spatial relationships. Consequently, we argue that the foundation for generalizable robotic control should be a vision-geometry backbone, rather than the widely adopted vision-language or video models. Conventional VLA and video-predictive models rely on backbones pretrained on large-scale 2D image-text or temporal pixel data. While effective, their representations are largely shaped by semantic concepts or 2D priors, which do not intrinsically align with the precise 3D geometric nature required for physical manipulation. Driven by this insight, we propose the Vision-Geometry-Action (VGA) model, which directly conditions action generation on pretrained native 3D representations. Specifically, VGA replaces conventional language or video backbones with a pretrained 3D world model, establishing a seamless vision-to-geometry mapping that translates visual inputs directly into physical actions. To further enhance geometric consistency, we introduce a Progressive Volumetric Modulation module and adopt a joint training strategy. Extensive experiments validate the effectiveness of our approach. In simulation benchmarks, VGA outperforms top-tier VLA baselines including $π_{0.5}$ and GeoVLA, demonstrating its superiority in precise manipulation. More importantly, VGA exhibits remarkable zero-shot generalization to unseen viewpoints in real-world deployments, consistently outperforming $π_{0.5}$. These results highlight that operating on native 3D representations-rather than translating through language or 2D video priors-is a highly promising direction for achieving generalizable physical intelligence.
SceneExpander: Expanding 3D Scenes with Free-Form Inserted Views
Mar 31, 2026World building with 3D scene representations is increasingly important for content creation, simulation, and interactive experiences, yet real workflows are inherently iterative: creators must repeatedly extend an existing scene under user control. Motivated by this research gap, we study 3D scene expansion in a user-centric workflow: starting from a real scene captured by multi-view images, we extend its coverage by inserting an additional view synthesized by a generative model. Unlike simple object editing or style transfer in a fixed scene, the inserted view is often 3D-misaligned with the original reconstruction, introducing geometry shifts, hallucinated content, or view-dependent artifacts that break global multi-view consistency. To address the challenge, we propose SceneExpander, which applies test-time adaptation to a parametric feed-forward 3D reconstruction model with two complementary distillation signals: anchor distillation stabilizes the original scene by distilling geometric cues from the captured views, while inserted-view self-distillation preserves observation-supported predictions yet adapts latent geometry and appearance to accommodate the misaligned inserted view. Experiments on ETH scenes and online data demonstrate improved expansion behavior and reconstruction quality under misalignment.
TAG: Target-Agnostic Guidance for Stable Object-Centric Inference in Vision-Language-Action Models
Mar 25, 2026Vision--Language--Action (VLA) policies have shown strong progress in mapping language instructions and visual observations to robotic actions, yet their reliability degrades in cluttered scenes with distractors. By analyzing failure cases, we find that many errors do not arise from infeasible motions, but from instance-level grounding failures: the policy often produces a plausible grasp trajectory that lands slightly off-target or even on the wrong object instance. To address this issue, we propose TAG (Target-Agnostic Guidance), a simple inference-time guidance mechanism that explicitly reduces distractor- and appearance-induced bias in VLA policies. Inspired by classifier-free guidance (CFG), TAG contrasts policy predictions under the original observation and an object-erased observation, and uses their difference as a residual steering signal that strengthens the influence of object evidence in the decision process. TAG does not require modifying the policy architecture and can be integrated with existing VLA policies with minimal training and inference changes. We evaluate TAG on standard manipulation benchmarks, including LIBERO, LIBERO-Plus, and VLABench, where it consistently improves robustness under clutter and reduces near-miss and wrong-object executions.
RADAR: Benchmarking Vision-Language-Action Generalization via Real-World Dynamics, Spatial-Physical Intelligence, and Autonomous Evaluation
Feb 11, 2026VLA models have achieved remarkable progress in embodied intelligence; however, their evaluation remains largely confined to simulations or highly constrained real-world settings. This mismatch creates a substantial reality gap, where strong benchmark performance often masks poor generalization in diverse physical environments. We identify three systemic shortcomings in current benchmarking practices that hinder fair and reliable model comparison. (1) Existing benchmarks fail to model real-world dynamics, overlooking critical factors such as dynamic object configurations, robot initial states, lighting changes, and sensor noise. (2) Current protocols neglect spatial--physical intelligence, reducing evaluation to rote manipulation tasks that do not probe geometric reasoning. (3) The field lacks scalable fully autonomous evaluation, instead relying on simplistic 2D metrics that miss 3D spatial structure or on human-in-the-loop systems that are costly, biased, and unscalable. To address these limitations, we introduce RADAR (Real-world Autonomous Dynamics And Reasoning), a benchmark designed to systematically evaluate VLA generalization under realistic conditions. RADAR integrates three core components: (1) a principled suite of physical dynamics; (2) dedicated tasks that explicitly test spatial reasoning and physical understanding; and (3) a fully autonomous evaluation pipeline based on 3D metrics, eliminating the need for human supervision. We apply RADAR to audit multiple state-of-the-art VLA models and uncover severe fragility beneath their apparent competence. Performance drops precipitously under modest physical dynamics, with the expectation of 3D IoU declining from 0.261 to 0.068 under sensor noise. Moreover, models exhibit limited spatial reasoning capability. These findings position RADAR as a necessary bench toward reliable and generalizable real-world evaluation of VLA models.
Bridging the Discrete-Continuous Gap: Unified Multimodal Generation via Coupled Manifold Discrete Absorbing Diffusion
Jan 07, 2026The bifurcation of generative modeling into autoregressive approaches for discrete data (text) and diffusion approaches for continuous data (images) hinders the development of truly unified multimodal systems. While Masked Language Models (MLMs) offer efficient bidirectional context, they traditionally lack the generative fidelity of autoregressive models and the semantic continuity of diffusion models. Furthermore, extending masked generation to multimodal settings introduces severe alignment challenges and training instability. In this work, we propose \textbf{CoM-DAD} (\textbf{Co}upled \textbf{M}anifold \textbf{D}iscrete \textbf{A}bsorbing \textbf{D}iffusion), a novel probabilistic framework that reformulates multimodal generation as a hierarchical dual-process. CoM-DAD decouples high-level semantic planning from low-level token synthesis. First, we model the semantic manifold via a continuous latent diffusion process; second, we treat token generation as a discrete absorbing diffusion process, regulated by a \textbf{Variable-Rate Noise Schedule}, conditioned on these evolving semantic priors. Crucially, we introduce a \textbf{Stochastic Mixed-Modal Transport} strategy that aligns disparate modalities without requiring heavy contrastive dual-encoders. Our method demonstrates superior stability over standard masked modeling, establishing a new paradigm for scalable, unified text-image generation.
Stable Language Guidance for Vision-Language-Action Models
Jan 07, 2026Vision-Language-Action (VLA) models have demonstrated impressive capabilities in generalized robotic control; however, they remain notoriously brittle to linguistic perturbations. We identify a critical ``modality collapse'' phenomenon where strong visual priors overwhelm sparse linguistic signals, causing agents to overfit to specific instruction phrasings while ignoring the underlying semantic intent. To address this, we propose \textbf{Residual Semantic Steering (RSS)}, a probabilistic framework that disentangles physical affordance from semantic execution. RSS introduces two theoretical innovations: (1) \textbf{Monte Carlo Syntactic Integration}, which approximates the true semantic posterior via dense, LLM-driven distributional expansion, and (2) \textbf{Residual Affordance Steering}, a dual-stream decoding mechanism that explicitly isolates the causal influence of language by subtracting the visual affordance prior. Theoretical analysis suggests that RSS effectively maximizes the mutual information between action and intent while suppressing visual distractors. Empirical results across diverse manipulation benchmarks demonstrate that RSS achieves state-of-the-art robustness, maintaining performance even under adversarial linguistic perturbations.
ACD: Direct Conditional Control for Video Diffusion Models via Attention Supervision
Dec 24, 2025Controllability is a fundamental requirement in video synthesis, where accurate alignment with conditioning signals is essential. Existing classifier-free guidance methods typically achieve conditioning indirectly by modeling the joint distribution of data and conditions, which often results in limited controllability over the specified conditions. Classifier-based guidance enforces conditions through an external classifier, but the model may exploit this mechanism to raise the classifier score without genuinely satisfying the intended condition, resulting in adversarial artifacts and limited effective controllability. In this paper, we propose Attention-Conditional Diffusion (ACD), a novel framework for direct conditional control in video diffusion models via attention supervision. By aligning the model's attention maps with external control signals, ACD achieves better controllability. To support this, we introduce a sparse 3D-aware object layout as an efficient conditioning signal, along with a dedicated Layout ControlNet and an automated annotation pipeline for scalable layout integration. Extensive experiments on benchmark video generation datasets demonstrate that ACD delivers superior alignment with conditioning inputs while preserving temporal coherence and visual fidelity, establishing an effective paradigm for conditional video synthesis.
UML-CoT: Structured Reasoning and Planning with Unified Modeling Language for Robotic Room Cleaning
Sep 26, 2025



Chain-of-Thought (CoT) prompting improves reasoning in large language models (LLMs), but its reliance on unstructured text limits interpretability and executability in embodied tasks. Prior work has explored structured CoTs using scene or logic graphs, yet these remain fundamentally limited: they model only low-order relations, lack constructs like inheritance or behavioral abstraction, and provide no standardized semantics for sequential or conditional planning. We propose UML-CoT, a structured reasoning and planning framework that leverages Unified Modeling Language (UML) to generate symbolic CoTs and executable action plans. UML class diagrams capture compositional object semantics, while activity diagrams model procedural control flow. Our three-stage training pipeline combines supervised fine-tuning with Group Relative Policy Optimization (GRPO), including reward learning from answer-only data. We evaluate UML-CoT on MRoom-30k, a new benchmark of cluttered room-cleaning scenarios. UML-CoT outperforms unstructured CoTs in interpretability, planning coherence, and execution success, highlighting UML as a more expressive and actionable structured reasoning formalism.
GS: Generative Segmentation via Label Diffusion
Aug 27, 2025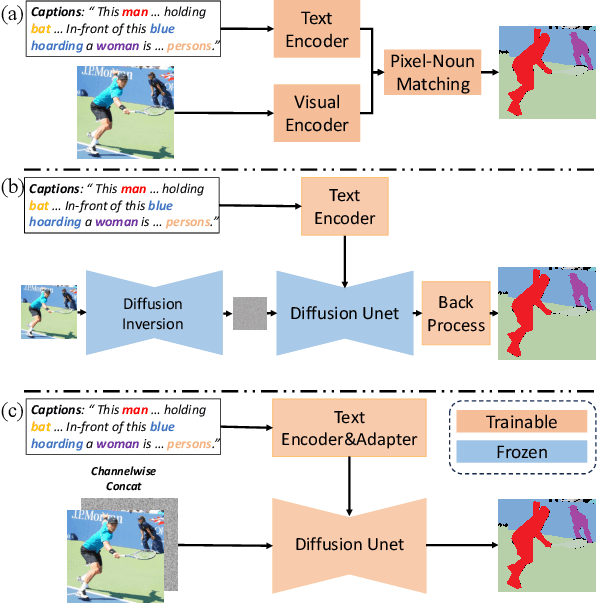
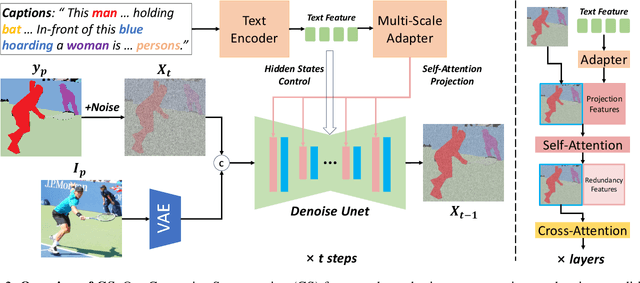
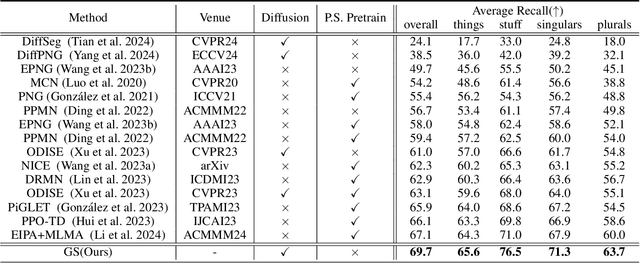
Language-driven image segmentation is a fundamental task in vision-language understanding, requiring models to segment regions of an image corresponding to natural language expressions. Traditional methods approach this as a discriminative problem, assigning each pixel to foreground or background based on semantic alignment. Recently, diffusion models have been introduced to this domain, but existing approaches remain image-centric: they either (i) use image diffusion models as visual feature extractors, (ii) synthesize segmentation data via image generation to train discriminative models, or (iii) perform diffusion inversion to extract attention cues from pre-trained image diffusion models-thereby treating segmentation as an auxiliary process. In this paper, we propose GS (Generative Segmentation), a novel framework that formulates segmentation itself as a generative task via label diffusion. Instead of generating images conditioned on label maps and text, GS reverses the generative process: it directly generates segmentation masks from noise, conditioned on both the input image and the accompanying language description. This paradigm makes label generation the primary modeling target, enabling end-to-end training with explicit control over spatial and semantic fidelity. To demonstrate the effectiveness of our approach, we evaluate GS on Panoptic Narrative Grounding (PNG), a representative and challenging benchmark for multimodal segmentation that requires panoptic-level reasoning guided by narrative captions. Experimental results show that GS significantly outperforms existing discriminative and diffusion-based methods, setting a new state-of-the-art for language-driven segmentation.