 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Implicit Memory for Video World Models
Jun 01, 2026Video world models aim to simulate controllable visual environments, but long-horizon rollouts depend on what the model remembers after observations leave its native context window. Explicit memories retain frames or online 3D reconstructions, which can suffer from heuristic retrieval errors, redundant appearance storage, or reconstruction artifacts. Implicit memories compress history into a compact state, but existing designs are not explicitly constrained to encode cross-view scene geometry. We propose GIM-World, a geometry-aware implicit memory framework for video world models. A lightweight transformer encoder compresses variable-length history into fixed-size memory tokens, a camera-queryable geometry head distills 3D scene structure from a frozen foundation model into the memory during training, and an information-guided pruning rule keeps encoding cost bounded as history grows. The geometry teacher is discarded at inference, leaving a lightweight memory module. Experiments on MIND show that GIM-World better preserves long-horizon geometric and visual consistency than both explicit- and implicit-memory baselines.
Voxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
A Reconstruction System for Industrial Pipeline Inner Walls Using Panoramic Image Stitching with Endoscopic Imaging
Feb 28, 2026Visual analysis and reconstruction of pipeline inner walls remain challenging in industrial inspection scenarios. This paper presents a dedicated reconstruction system for pipeline inner walls via industrial endoscopes, which is built on panoramic image stitching technology. Equipped with a custom graphical user interface (GUI), the system extracts key frames from endoscope video footage, and integrates polar coordinate transformation with image stitching techniques to unwrap annular video frames of pipeline inner walls into planar panoramic images. Experimental results demonstrate that the proposed method enables efficient processing of industrial endoscope videos, and the generated panoramic stitched images preserve all detailed features of pipeline inner walls in their entirety. This provides intuitive and accurate visual support for defect detection and condition assessment of pipeline inner walls. In comparison with the traditional frame-by-frame video review method, the proposed approach significantly elevates the efficiency of pipeline inner wall reconstruction and exhibits considerable engineering application value.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
OmniTransfer: All-in-one Framework for Spatio-temporal Video Transfer
Jan 20, 2026Videos convey richer information than images or text, capturing both spatial and temporal dynamics. However, most existing video customization methods rely on reference images or task-specific temporal priors, failing to fully exploit the rich spatio-temporal information inherent in videos, thereby limiting flexibility and generalization in video generation. To address these limitations, we propose OmniTransfer, a unified framework for spatio-temporal video transfer. It leverages multi-view information across frames to enhance appearance consistency and exploits temporal cues to enable fine-grained temporal control. To unify various video transfer tasks, OmniTransfer incorporates three key designs: Task-aware Positional Bias that adaptively leverages reference video information to improve temporal alignment or appearance consistency; Reference-decoupled Causal Learning separating reference and target branches to enable precise reference transfer while improving efficiency; and Task-adaptive Multimodal Alignment using multimodal semantic guidance to dynamically distinguish and tackle different tasks. Extensive experiments show that OmniTransfer outperforms existing methods in appearance (ID and style) and temporal transfer (camera movement and video effects), while matching pose-guided methods in motion transfer without using pose, establishing a new paradigm for flexible, high-fidelity video generation.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
DreamID-V:Bridging the Image-to-Video Gap for High-Fidelity Face Swapping via Diffusion Transformer
Jan 04, 2026Video Face Swapping (VFS) requires seamlessly injecting a source identity into a target video while meticulously preserving the original pose, expression, lighting, background, and dynamic information. Existing methods struggle to maintain identity similarity and attribute preservation while preserving temporal consistency. To address the challenge, we propose a comprehensive framework to seamlessly transfer the superiority of Image Face Swapping (IFS) to the video domain. We first introduce a novel data pipeline SyncID-Pipe that pre-trains an Identity-Anchored Video Synthesizer and combines it with IFS models to construct bidirectional ID quadruplets for explicit supervision. Building upon paired data, we propose the first Diffusion Transformer-based framework DreamID-V, employing a core Modality-Aware Conditioning module to discriminatively inject multi-model conditions. Meanwhile, we propose a Synthetic-to-Real Curriculum mechanism and an Identity-Coherence Reinforcement Learning strategy to enhance visual realism and identity consistency under challenging scenarios. To address the issue of limited benchmarks, we introduce IDBench-V, a comprehensive benchmark encompassing diverse scenes. Extensive experiments demonstrate DreamID-V outperforms state-of-the-art methods and further exhibits exceptional versatility, which can be seamlessly adapted to various swap-related tasks.
Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset
Jun 23, 2025Subject-to-video generation has witnessed substantial progress in recent years. However, existing models still face significant challenges in faithfully following textual instructions. This limitation, commonly known as the copy-paste problem, arises from the widely used in-pair training paradigm. This approach inherently entangles subject identity with background and contextual attributes by sampling reference images from the same scene as the target video. To address this issue, we introduce \textbf{Phantom-Data, the first general-purpose cross-pair subject-to-video consistency dataset}, containing approximately one million identity-consistent pairs across diverse categories. Our dataset is constructed via a three-stage pipeline: (1) a general and input-aligned subject detection module, (2) large-scale cross-context subject retrieval from more than 53 million videos and 3 billion images, and (3) prior-guided identity verification to ensure visual consistency under contextual variation. Comprehensive experiments show that training with Phantom-Data significantly improves prompt alignment and visual quality while preserving identity consistency on par with in-pair baselines.
Seeing in the Dark: Benchmarking Egocentric 3D Vision with the Oxford Day-and-Night Dataset
Jun 04, 2025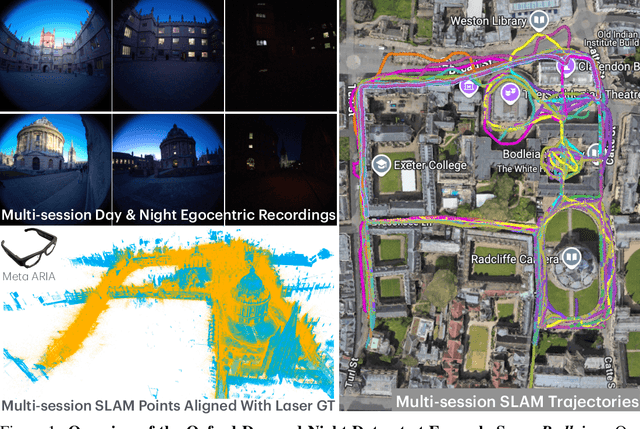


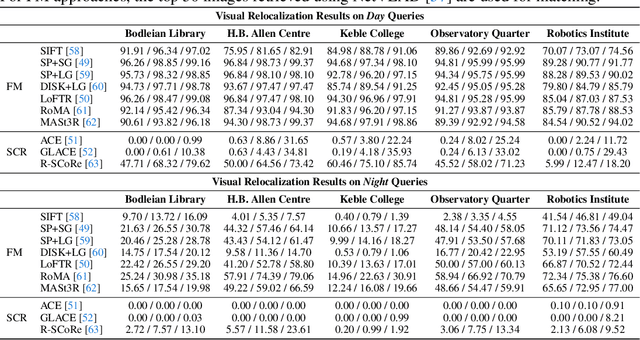
We introduce Oxford Day-and-Night, a large-scale, egocentric dataset for novel view synthesis (NVS) and visual relocalisation under challenging lighting conditions. Existing datasets often lack crucial combinations of features such as ground-truth 3D geometry, wide-ranging lighting variation, and full 6DoF motion. Oxford Day-and-Night addresses these gaps by leveraging Meta ARIA glasses to capture egocentric video and applying multi-session SLAM to estimate camera poses, reconstruct 3D point clouds, and align sequences captured under varying lighting conditions, including both day and night. The dataset spans over 30 $\mathrm{km}$ of recorded trajectories and covers an area of 40,000 $\mathrm{m}^2$, offering a rich foundation for egocentric 3D vision research. It supports two core benchmarks, NVS and relocalisation, providing a unique platform for evaluating models in realistic and diverse environments.
Semantic Correspondence: Unified Benchmarking and a Strong Baseline
May 26, 2025Establishing semantic correspondence is a challenging task in computer vision, aiming to match keypoints with the same semantic information across different images. Benefiting from the rapid development of deep learning, remarkable progress has been made over the past decade. However, a comprehensive review and analysis of this task remains absent. In this paper, we present the first extensive survey of semantic correspondence methods. We first propose a taxonomy to classify existing methods based on the type of their method designs. These methods are then categorized accordingly, and we provide a detailed analysis of each approach. Furthermore, we aggregate and summarize the results of methods in literature across various benchmarks into a unified comparative table, with detailed configurations to highlight performance variations. Additionally, to provide a detailed understanding on existing methods for semantic matching, we thoroughly conduct controlled experiments to analyse the effectiveness of the components of different methods. Finally, we propose a simple yet effective baseline that achieves state-of-the-art performance on multiple benchmarks, providing a solid foundation for future research in this field. We hope this survey serves as a comprehensive reference and consolidated baseline for future development. Code is publicly available at: https://github.com/Visual-AI/Semantic-Correspondence.