 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
LibraGen: Playing a Balance Game in Subject-Driven Video Generation
Mar 17, 2026With the advancement of video generation foundation models (VGFMs), customized generation, particularly subject-to-video (S2V), has attracted growing attention. However, a key challenge lies in balancing the intrinsic priors of a VGFM, such as motion coherence, visual aesthetics, and prompt alignment, with its newly derived S2V capability. Existing methods often neglect this balance by enhancing one aspect at the expense of others. To address this, we propose LibraGen, a novel framework that views extending foundation models for S2V generation as a balance game between intrinsic VGFM strengths and S2V capability. Specifically, guided by the core philosophy of "Raising the Fulcrum, Tuning to Balance," we identify data quality as the fulcrum and advocate a quality-over-quantity approach. We construct a hybrid pipeline that combines automated and manual data filtering to improve overall data quality. To further harmonize the VGFM's native capabilities with its S2V extension, we introduce a Tune-to-Balance post-training paradigm. During supervised fine-tuning, both cross-pair and in-pair data are incorporated, and model merging is employed to achieve an effective trade-off. Subsequently, two tailored direct preference optimization (DPO) pipelines, namely Consis-DPO and Real-Fake DPO, are designed and merged to consolidate this balance. During inference, we introduce a time-dependent dynamic classifier-free guidance scheme to enable flexible and fine-grained control. Experimental results demonstrate that LibraGen outperforms both open-source and commercial S2V models using only thousand-scale training data.
OmniTransfer: All-in-one Framework for Spatio-temporal Video Transfer
Jan 20, 2026Videos convey richer information than images or text, capturing both spatial and temporal dynamics. However, most existing video customization methods rely on reference images or task-specific temporal priors, failing to fully exploit the rich spatio-temporal information inherent in videos, thereby limiting flexibility and generalization in video generation. To address these limitations, we propose OmniTransfer, a unified framework for spatio-temporal video transfer. It leverages multi-view information across frames to enhance appearance consistency and exploits temporal cues to enable fine-grained temporal control. To unify various video transfer tasks, OmniTransfer incorporates three key designs: Task-aware Positional Bias that adaptively leverages reference video information to improve temporal alignment or appearance consistency; Reference-decoupled Causal Learning separating reference and target branches to enable precise reference transfer while improving efficiency; and Task-adaptive Multimodal Alignment using multimodal semantic guidance to dynamically distinguish and tackle different tasks. Extensive experiments show that OmniTransfer outperforms existing methods in appearance (ID and style) and temporal transfer (camera movement and video effects), while matching pose-guided methods in motion transfer without using pose, establishing a new paradigm for flexible, high-fidelity video generation.
HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
Sep 10, 2025Human-Centric Video Generation (HCVG) methods seek to synthesize human videos from multimodal inputs, including text, image, and audio. Existing methods struggle to effectively coordinate these heterogeneous modalities due to two challenges: the scarcity of training data with paired triplet conditions and the difficulty of collaborating the sub-tasks of subject preservation and audio-visual sync with multimodal inputs. In this work, we present HuMo, a unified HCVG framework for collaborative multimodal control. For the first challenge, we construct a high-quality dataset with diverse and paired text, reference images, and audio. For the second challenge, we propose a two-stage progressive multimodal training paradigm with task-specific strategies. For the subject preservation task, to maintain the prompt following and visual generation abilities of the foundation model, we adopt the minimal-invasive image injection strategy. For the audio-visual sync task, besides the commonly adopted audio cross-attention layer, we propose a focus-by-predicting strategy that implicitly guides the model to associate audio with facial regions. For joint learning of controllabilities across multimodal inputs, building on previously acquired capabilities, we progressively incorporate the audio-visual sync task. During inference, for flexible and fine-grained multimodal control, we design a time-adaptive Classifier-Free Guidance strategy that dynamically adjusts guidance weights across denoising steps. Extensive experimental results demonstrate that HuMo surpasses specialized state-of-the-art methods in sub-tasks, establishing a unified framework for collaborative multimodal-conditioned HCVG. Project Page: https://phantom-video.github.io/HuMo.
OTESGN:Optimal Transport Enhanced Syntactic-Semantic Graph Networks for Aspect-Based Sentiment Analysis
Sep 10, 2025Aspect-based sentiment analysis (ABSA) aims to identify aspect terms and determine their sentiment polarity. While dependency trees combined with contextual semantics effectively identify aspect sentiment, existing methods relying on syntax trees and aspect-aware attention struggle to model complex semantic relationships. Their dependence on linear dot-product features fails to capture nonlinear associations, allowing noisy similarity from irrelevant words to obscure key opinion terms. Motivated by Differentiable Optimal Matching, we propose the Optimal Transport Enhanced Syntactic-Semantic Graph Network (OTESGN), which introduces a Syntactic-Semantic Collaborative Attention. It comprises a Syntactic Graph-Aware Attention for mining latent syntactic dependencies and modeling global syntactic topology, as well as a Semantic Optimal Transport Attention designed to uncover fine-grained semantic alignments amidst textual noise, thereby accurately capturing sentiment signals obscured by irrelevant tokens. A Adaptive Attention Fusion module integrates these heterogeneous features, and contrastive regularization further improves robustness. Experiments demonstrate that OTESGN achieves state-of-the-art results, outperforming previous best models by +1.01% F1 on Twitter and +1.30% F1 on Laptop14 benchmarks. Ablative studies and visual analyses corroborate its efficacy in precise localization of opinion words and noise resistance.
Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset
Jun 23, 2025Subject-to-video generation has witnessed substantial progress in recent years. However, existing models still face significant challenges in faithfully following textual instructions. This limitation, commonly known as the copy-paste problem, arises from the widely used in-pair training paradigm. This approach inherently entangles subject identity with background and contextual attributes by sampling reference images from the same scene as the target video. To address this issue, we introduce \textbf{Phantom-Data, the first general-purpose cross-pair subject-to-video consistency dataset}, containing approximately one million identity-consistent pairs across diverse categories. Our dataset is constructed via a three-stage pipeline: (1) a general and input-aligned subject detection module, (2) large-scale cross-context subject retrieval from more than 53 million videos and 3 billion images, and (3) prior-guided identity verification to ensure visual consistency under contextual variation. Comprehensive experiments show that training with Phantom-Data significantly improves prompt alignment and visual quality while preserving identity consistency on par with in-pair baselines.
CustomContrast: A Multilevel Contrastive Perspective For Subject-Driven Text-to-Image Customization
Sep 11, 2024



Subject-driven text-to-image (T2I) customization has drawn significant interest in academia and industry. This task enables pre-trained models to generate novel images based on unique subjects. Existing studies adopt a self-reconstructive perspective, focusing on capturing all details of a single image, which will misconstrue the specific image's irrelevant attributes (e.g., view, pose, and background) as the subject intrinsic attributes. This misconstruction leads to both overfitting or underfitting of irrelevant and intrinsic attributes of the subject, i.e., these attributes are over-represented or under-represented simultaneously, causing a trade-off between similarity and controllability. In this study, we argue an ideal subject representation can be achieved by a cross-differential perspective, i.e., decoupling subject intrinsic attributes from irrelevant attributes via contrastive learning, which allows the model to focus more on intrinsic attributes through intra-consistency (features of the same subject are spatially closer) and inter-distinctiveness (features of different subjects have distinguished differences). Specifically, we propose CustomContrast, a novel framework, which includes a Multilevel Contrastive Learning (MCL) paradigm and a Multimodal Feature Injection (MFI) Encoder. The MCL paradigm is used to extract intrinsic features of subjects from high-level semantics to low-level appearance through crossmodal semantic contrastive learning and multiscale appearance contrastive learning. To facilitate contrastive learning, we introduce the MFI encoder to capture cross-modal representations. Extensive experiments show the effectiveness of CustomContrast in subject similarity and text controllability.
An Effective Deployment of Diffusion LM for Data Augmentation in Low-Resource Sentiment Classification
Sep 05, 2024



Sentiment classification (SC) often suffers from low-resource challenges such as domain-specific contexts, imbalanced label distributions, and few-shot scenarios. The potential of the diffusion language model (LM) for textual data augmentation (DA) remains unexplored, moreover, textual DA methods struggle to balance the diversity and consistency of new samples. Most DA methods either perform logical modifications or rephrase less important tokens in the original sequence with the language model. In the context of SC, strong emotional tokens could act critically on the sentiment of the whole sequence. Therefore, contrary to rephrasing less important context, we propose DiffusionCLS to leverage a diffusion LM to capture in-domain knowledge and generate pseudo samples by reconstructing strong label-related tokens. This approach ensures a balance between consistency and diversity, avoiding the introduction of noise and augmenting crucial features of datasets. DiffusionCLS also comprises a Noise-Resistant Training objective to help the model generalize. Experiments demonstrate the effectiveness of our method in various low-resource scenarios including domain-specific and domain-general problems. Ablation studies confirm the effectiveness of our framework's modules, and visualization studies highlight optimal deployment conditions, reinforcing our conclusions.
PuLID: Pure and Lightning ID Customization via Contrastive Alignment
Apr 24, 2024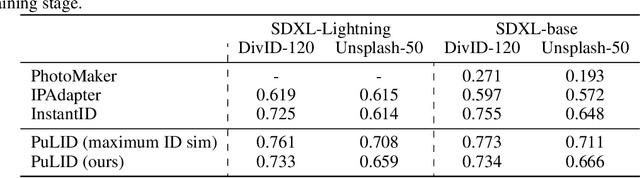
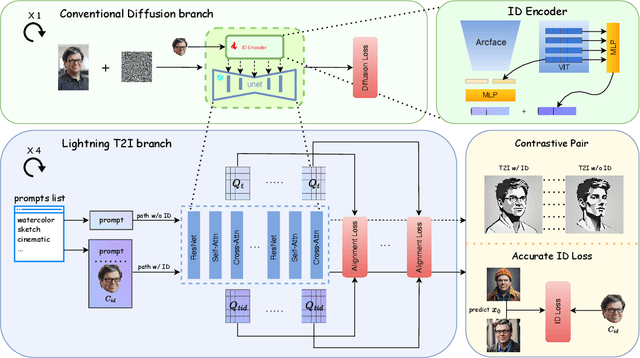
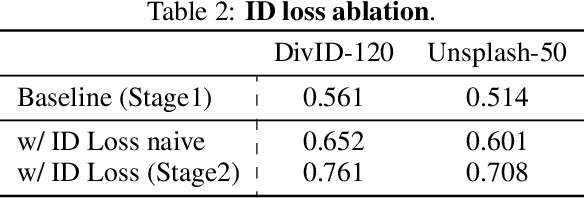

We propose Pure and Lightning ID customization (PuLID), a novel tuning-free ID customization method for text-to-image generation. By incorporating a Lightning T2I branch with a standard diffusion one, PuLID introduces both contrastive alignment loss and accurate ID loss, minimizing disruption to the original model and ensuring high ID fidelity. Experiments show that PuLID achieves superior performance in both ID fidelity and editability. Another attractive property of PuLID is that the image elements (e.g., background, lighting, composition, and style) before and after the ID insertion are kept as consistent as possible. Codes and models will be available at https://github.com/ToTheBeginning/PuLID
DreamIdentity: Improved Editability for Efficient Face-identity Preserved Image Generation
Jul 01, 2023While large-scale pre-trained text-to-image models can synthesize diverse and high-quality human-centric images, an intractable problem is how to preserve the face identity for conditioned face images. Existing methods either require time-consuming optimization for each face-identity or learning an efficient encoder at the cost of harming the editability of models. In this work, we present an optimization-free method for each face identity, meanwhile keeping the editability for text-to-image models. Specifically, we propose a novel face-identity encoder to learn an accurate representation of human faces, which applies multi-scale face features followed by a multi-embedding projector to directly generate the pseudo words in the text embedding space. Besides, we propose self-augmented editability learning to enhance the editability of models, which is achieved by constructing paired generated face and edited face images using celebrity names, aiming at transferring mature ability of off-the-shelf text-to-image models in celebrity faces to unseen faces. Extensive experiments show that our methods can generate identity-preserved images under different scenes at a much faster speed.