 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianJi-Environ: An Autonomous AI Scientist for Atmospheric Environmental Research
Jun 05, 2026As atmospheric environmental prediction continues to improve, interpretable validation of pollution mechanisms and feedback processes has become a main challenge in atmospheric chemistry. Yet mechanism validation based on complex numerical models still relies heavily on expert knowledge: mechanistic hypotheses must be operationalized into executable experiments, and model outputs must be organized into traceable evidence. We present TianJi-Environ, an auditable AI Scientist for atmospheric-chemistry mechanism validation. TianJi-Environ establishes the first WRF-Chem-based multi-agent framework that autonomously drives complex atmospheric-chemistry simulations, converting mechanistic hypotheses into executable configurations, testing experiments, and evidence criteria. Using ozone response and particulate-matter feedback as two representative examples, we demonstrate TianJi-Environ's capability for mechanism validation. In a summertime ozone case over the North China Plain, the system detects directionally consistent aerosol-radiation-interaction signals in shortwave radiation and boundary-layer height, but judges the evidence for ozone response to NOx control to be incomplete. In a wintertime PM2.5 case over the Guanzhong Basin, it localizes the unsupported link to insufficient propagation from black-carbon perturbation to particulate response and missing diagnostics of vertical absorptive heating. These results show that TianJi-Environ makes expert-driven mechanism validation explicit, structured, and auditable, offering a reproducible paradigm for multi-agent systems coupled with complex atmospheric-chemistry models.
3D Primitives are a Spatial Language for VLMs
May 12, 2026Vision-language models (VLMs) exhibit a striking paradox: they can generate executable code that reconstructs a 3D scene from geometric primitives with correct object counts, classes, and approximate positions, yet the same models fail at simpler spatial questions on the same image. We show that 3D geometric primitives (cubes, spheres, cylinders, expressed in executable code) serve as a powerful intermediate representation for spatial understanding, and exploit this through three contributions. First, we introduce \textbf{\textsc{SpatialBabel}}, a benchmark evaluating fourteen VLMs on primitive-based 3D scene reconstruction across six \emph{scene-code languages} (programming languages and declarative formats for 3D primitive scenes), revealing that a single model's object-detection F1 can vary by up to $5.7\times$ across languages. Second, we propose \textbf{Code-CoT} (Code Chain-of-Thought), a training-free inference strategy that routes spatial reasoning through primitive-based code generation. Code-CoT lifts the SpatialBabel-QA-Score by up to $+6.4$\% on primitive scenes and real-photo CV-Bench-3D accuracy by $+5.0$\% for VLMs with strong coding capabilities. Third, we propose \textbf{S$^{3}$-FT} (Self-Supervised Spatial Fine-Tuning), which self-supervisedly distills primitive spatial knowledge into general visual reasoning by parsing the model's own Three.js primitive-reconstructions into structured annotations and fine-tuning on the result, with \emph{no human labels and no teacher model}. Training on primitive images alone, S$^3$-FT improves Qwen3-VL-8B by $+4.6$ to $+8.6$\% on SpatialBabel-Primitive-QA, $+9.7$\% on CV-Bench-2D, and $+17$\% on HallusionBench; the recipe transfers across model families. These results establish geometric primitives in code as both a diagnostic and a transferable spatial vocabulary for VLMs. We will release all artifacts upon publication.
A Continuous-Time Ensemble Kalman-Bucy Smoother for Causal Inference and Model Discovery
Apr 28, 2026Data assimilation (DA) integrates observational information with model predictions to improve state estimation in complex systems. While filtering provides the basis for online forecasts by using only past and present observations, it can exhibit delays and biases when the underlying dynamics evolve rapidly or undergo regime transitions. Smoothing, which additionally incorporates future observations, provides a natural pipeline for hindcasting and reanalysis that yields an uncertainty reduction beyond the filter. This paper introduces an ensemble Kalman-Bucy smoother (EnKBS) for continuous-time DA of nonlinear dynamical systems, where the smoother's conditional distributions are reconstructed using ensemble moments. The result is a derivative-free framework that does not require explicit computation of tangent-linear or adjoint models, which converges to the exact smoother solution at the infinite-ensemble limit for a wide class of complex systems. Incorporating standard regularization techniques for high-dimensional systems, such as covariance localization and inflation, the skill of the EnKBS is demonstrated in various important scientific problems. By integrating future observations, which reveal the underlying causal mechanisms for retrospective state updates, the EnKBS is used for Bayesian-based inference of causal relationships and their temporal influence range in a dyadic trigger-feedback model and the development of a causality-driven iterative learning algorithm that identifies the structure and recovers the hidden parameters of a nonlinear reduced-order model mimicking midlatitude atmospheric circulation. Notably, both tasks remain effective with an ensemble size of $O(10)$ under partial observations, suggesting that EnKBS can support the instantaneous discovery of high-dimensional complex systems over time.
TianJi:An autonomous AI meteorologist for discovering physical mechanisms in atmospheric science
Mar 29, 2026Artificial intelligence (AI) has achieved breakthroughs comparable to traditional numerical models in data-driven weather forecasting, yet it remains essentially statistical fitting and struggles to uncover the physical causal mechanisms of the atmosphere. Physics-oriented mechanism research still heavily relies on domain knowledge and cumbersome engineering operations of human scientists, becoming a bottleneck restricting the efficiency of Earth system science exploration. Here, we propose TianJi - the first "AI meteorologist" system capable of autonomously driving complex numerical models to verify physical mechanisms. Powered by a large language model-driven multi-agent architecture, TianJi can autonomously conduct literature research and generate scientific hypotheses. We further decouple scientific research into cognitive planning and engineering execution: the meta-planner interprets hypotheses and devises experimental roadmaps, while a cohort of specialized worker agents collaboratively complete data preparation, model configuration, and multi-dimensional result analysis. In two classic atmospheric dynamic scenarios (squall-line cold pools and typhoon track deflections), TianJi accomplishes expert-level end-to-end experimental operations with zero human intervention, compressing the research cycle to a few hours. It also delivers detailed result analyses and autonomously judges and explains the validity of the hypotheses from outputs. TianJi reveals that the role of AI in Earth system science is transitioning from a "black-box predictor" to an "interpretable scientific collaborator", offering a new paradigm for high-throughput exploration of scientific mechanisms.
$μ$pscaling small models: Principled warm starts and hyperparameter transfer
Feb 11, 2026Modern large-scale neural networks are often trained and released in multiple sizes to accommodate diverse inference budgets. To improve efficiency, recent work has explored model upscaling: initializing larger models from trained smaller ones in order to transfer knowledge and accelerate convergence. However, this method can be sensitive to hyperparameters that need to be tuned at the target upscaled model size, which is prohibitively costly to do directly. It remains unclear whether the most common workaround -- tuning on smaller models and extrapolating via hyperparameter scaling laws -- is still sound when using upscaling. We address this with principled approaches to upscaling with respect to model widths and efficiently tuning hyperparameters in this setting. First, motivated by $μ$P and any-dimensional architectures, we introduce a general upscaling method applicable to a broad range of architectures and optimizers, backed by theory guaranteeing that models are equivalent to their widened versions and allowing for rigorous analysis of infinite-width limits. Second, we extend the theory of $μ$Transfer to a hyperparameter transfer technique for models upscaled using our method and empirically demonstrate that this method is effective on realistic datasets and architectures.
Learning Rate Scaling across LoRA Ranks and Transfer to Full Finetuning
Feb 05, 2026Low-Rank Adaptation (LoRA) is a standard tool for parameter-efficient finetuning of large models. While it induces a small memory footprint, its training dynamics can be surprisingly complex as they depend on several hyperparameters such as initialization, adapter rank, and learning rate. In particular, it is unclear how the optimal learning rate scales with adapter rank, which forces practitioners to re-tune the learning rate whenever the rank is changed. In this paper, we introduce Maximal-Update Adaptation ($μ$A), a theoretical framework that characterizes how the "optimal" learning rate should scale with model width and adapter rank to produce stable, non-vanishing feature updates under standard configurations. $μ$A is inspired from the Maximal-Update Parametrization ($μ$P) in pretraining. Our analysis leverages techniques from hyperparameter transfer and reveals that the optimal learning rate exhibits different scaling patterns depending on initialization and LoRA scaling factor. Specifically, we identify two regimes: one where the optimal learning rate remains roughly invariant across ranks, and another where it scales inversely with rank. We further identify a configuration that allows learning rate transfer from LoRA to full finetuning, drastically reducing the cost of learning rate tuning for full finetuning. Experiments across language, vision, vision--language, image generation, and reinforcement learning tasks validate our scaling rules and show that learning rates tuned on LoRA transfer reliably to full finetuning.
LongAnimation: Long Animation Generation with Dynamic Global-Local Memory
Jul 02, 2025



Animation colorization is a crucial part of real animation industry production. Long animation colorization has high labor costs. Therefore, automated long animation colorization based on the video generation model has significant research value. Existing studies are limited to short-term colorization. These studies adopt a local paradigm, fusing overlapping features to achieve smooth transitions between local segments. However, the local paradigm neglects global information, failing to maintain long-term color consistency. In this study, we argue that ideal long-term color consistency can be achieved through a dynamic global-local paradigm, i.e., dynamically extracting global color-consistent features relevant to the current generation. Specifically, we propose LongAnimation, a novel framework, which mainly includes a SketchDiT, a Dynamic Global-Local Memory (DGLM), and a Color Consistency Reward. The SketchDiT captures hybrid reference features to support the DGLM module. The DGLM module employs a long video understanding model to dynamically compress global historical features and adaptively fuse them with the current generation features. To refine the color consistency, we introduce a Color Consistency Reward. During inference, we propose a color consistency fusion to smooth the video segment transition. Extensive experiments on both short-term (14 frames) and long-term (average 500 frames) animations show the effectiveness of LongAnimation in maintaining short-term and long-term color consistency for open-domain animation colorization task. The code can be found at https://cn-makers.github.io/long_animation_web/.
Assimilative Causal Inference
May 20, 2025Causal inference determines cause-and-effect relationships between variables and has broad applications across disciplines. Traditional time-series methods often reveal causal links only in a time-averaged sense, while ensemble-based information transfer approaches detect the time evolution of short-term causal relationships but are typically limited to low-dimensional systems. In this paper, a new causal inference framework, called assimilative causal inference (ACI), is developed. Fundamentally different from the state-of-the-art methods, ACI uses a dynamical system and a single realization of a subset of the state variables to identify instantaneous causal relationships and the dynamic evolution of the associated causal influence range (CIR). Instead of quantifying how causes influence effects as done traditionally, ACI solves an inverse problem via Bayesian data assimilation, thus tracing causes backward from observed effects with an implicit Bayesian hypothesis. Causality is determined by assessing whether incorporating the information of the effect variables reduces the uncertainty in recovering the potential cause variables. ACI has several desirable features. First, it captures the dynamic interplay of variables, where their roles as causes and effects can shift repeatedly over time. Second, a mathematically justified objective criterion determines the CIR without empirical thresholds. Third, ACI is scalable to high-dimensional problems by leveraging computationally efficient Bayesian data assimilation techniques. Finally, ACI applies to short time series and incomplete datasets. Notably, ACI does not require observations of candidate causes, which is a key advantage since potential drivers are often unknown or unmeasured. The effectiveness of ACI is demonstrated by complex dynamical systems showcasing intermittency and extreme events.
HDGlyph: A Hierarchical Disentangled Glyph-Based Framework for Long-Tail Text Rendering in Diffusion Models
May 10, 2025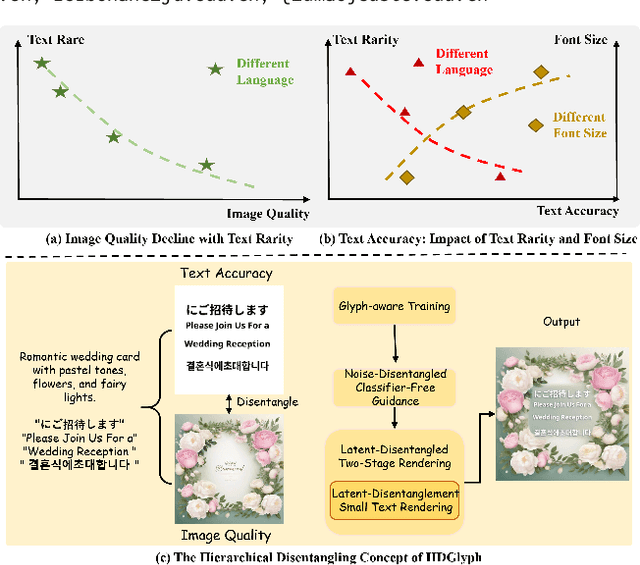
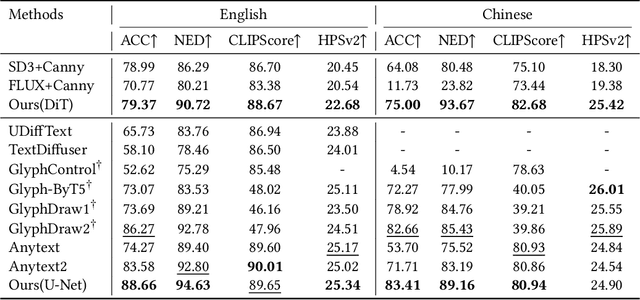
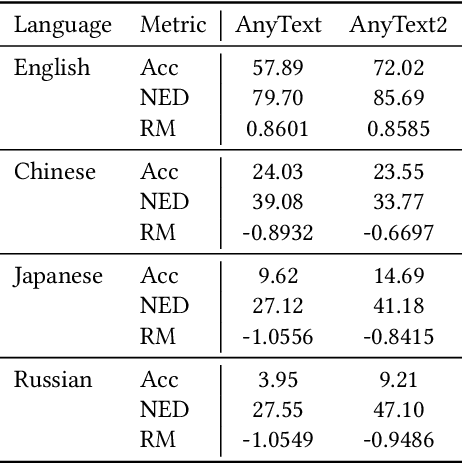
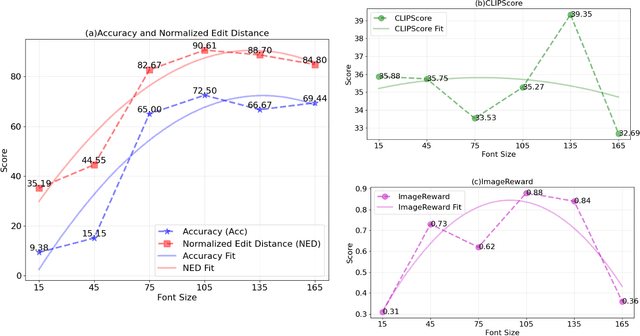
Visual text rendering, which aims to accurately integrate specified textual content within generated images, is critical for various applications such as commercial design. Despite recent advances, current methods struggle with long-tail text cases, particularly when handling unseen or small-sized text. In this work, we propose a novel Hierarchical Disentangled Glyph-Based framework (HDGlyph) that hierarchically decouples text generation from non-text visual synthesis, enabling joint optimization of both common and long-tail text rendering. At the training stage, HDGlyph disentangles pixel-level representations via the Multi-Linguistic GlyphNet and the Glyph-Aware Perceptual Loss, ensuring robust rendering even for unseen characters. At inference time, HDGlyph applies Noise-Disentangled Classifier-Free Guidance and Latent-Disentangled Two-Stage Rendering (LD-TSR) scheme, which refines both background and small-sized text. Extensive evaluations show our model consistently outperforms others, with 5.08% and 11.7% accuracy gains in English and Chinese text rendering while maintaining high image quality. It also excels in long-tail scenarios with strong accuracy and visual performance.
RL-DAUNCE: Reinforcement Learning-Driven Data Assimilation with Uncertainty-Aware Constrained Ensembles
May 08, 2025



Machine learning has become a powerful tool for enhancing data assimilation. While supervised learning remains the standard method, reinforcement learning (RL) offers unique advantages through its sequential decision-making framework, which naturally fits the iterative nature of data assimilation by dynamically balancing model forecasts with observations. We develop RL-DAUNCE, a new RL-based method that enhances data assimilation with physical constraints through three key aspects. First, RL-DAUNCE inherits the computational efficiency of machine learning while it uniquely structures its agents to mirror ensemble members in conventional data assimilation methods. Second, RL-DAUNCE emphasizes uncertainty quantification by advancing multiple ensemble members, moving beyond simple mean-state optimization. Third, RL-DAUNCE's ensemble-as-agents design facilitates the enforcement of physical constraints during the assimilation process, which is crucial to improving the state estimation and subsequent forecasting. A primal-dual optimization strategy is developed to enforce constraints, which dynamically penalizes the reward function to ensure constraint satisfaction throughout the learning process. Also, state variable bounds are respected by constraining the RL action space. Together, these features ensure physical consistency without sacrificing efficiency. RL-DAUNCE is applied to the Madden-Julian Oscillation, an intermittent atmospheric phenomenon characterized by strongly non-Gaussian features and multiple physical constraints. RL-DAUNCE outperforms the standard ensemble Kalman filter (EnKF), which fails catastrophically due to the violation of physical constraints. Notably, RL-DAUNCE matches the performance of constrained EnKF, particularly in recovering intermittent signals, capturing extreme events, and quantifying uncertainties, while requiring substantially less computational effort.