 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Twin Buildings: 3D Modeling, GIS Integration, and Visual Descriptions Using Gaussian Splatting, ChatGPT/Deepseek, and Google Maps Platforms
Feb 09, 2025Urban digital twins are virtual replicas of cities that use multi-source data and data analytics to optimize urban planning, infrastructure management, and decision-making. Towards this, we propose a framework focused on the single-building scale. By connecting to cloud mapping platforms such as Google Map Platforms APIs, by leveraging state-of-the-art multi-agent Large Language Models data analysis using ChatGPT(4o) and Deepseek-V3/R1, and by using our Gaussian Splatting-based mesh extraction pipeline, our Digital Twin Buildings framework can retrieve a building's 3D model, visual descriptions, and achieve cloud-based mapping integration with large language model-based data analytics using a building's address, postal code, or geographic coordinates.
Gaussian Building Mesh (GBM): Extract a Building's 3D Mesh with Google Earth and Gaussian Splatting
Jan 07, 2025



Recently released open-source pre-trained foundational image segmentation and object detection models (SAM2+GroundingDINO) allow for geometrically consistent segmentation of objects of interest in multi-view 2D images. Users can use text-based or click-based prompts to segment objects of interest without requiring labeled training datasets. Gaussian Splatting allows for the learning of the 3D representation of a scene's geometry and radiance based on 2D images. Combining Google Earth Studio, SAM2+GroundingDINO, 2D Gaussian Splatting, and our improvements in mask refinement based on morphological operations and contour simplification, we created a pipeline to extract the 3D mesh of any building based on its name, address, or geographic coordinates.
Efficient Point Transformer with Dynamic Token Aggregating for Point Cloud Processing
May 23, 2024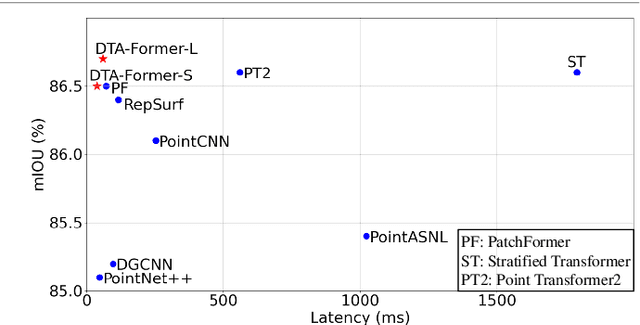
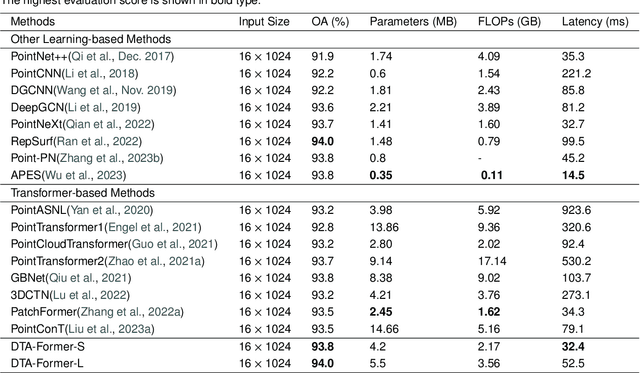
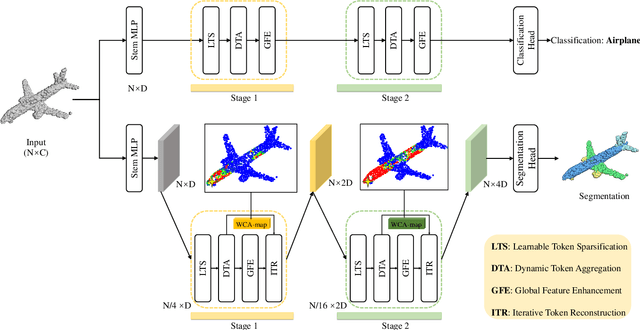
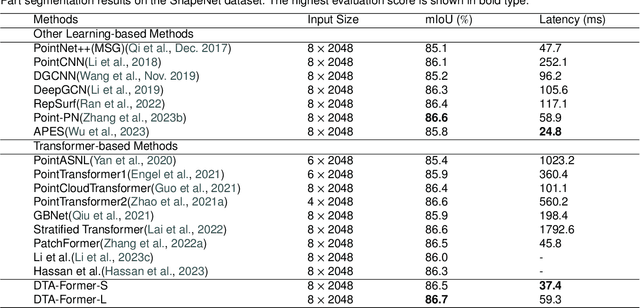
Recently, point cloud processing and analysis have made great progress due to the development of 3D Transformers. However, existing 3D Transformer methods usually are computationally expensive and inefficient due to their huge and redundant attention maps. They also tend to be slow due to requiring time-consuming point cloud sampling and grouping processes. To address these issues, we propose an efficient point TransFormer with Dynamic Token Aggregating (DTA-Former) for point cloud representation and processing. Firstly, we propose an efficient Learnable Token Sparsification (LTS) block, which considers both local and global semantic information for the adaptive selection of key tokens. Secondly, to achieve the feature aggregation for sparsified tokens, we present the first Dynamic Token Aggregating (DTA) block in the 3D Transformer paradigm, providing our model with strong aggregated features while preventing information loss. After that, a dual-attention Transformer-based Global Feature Enhancement (GFE) block is used to improve the representation capability of the model. Equipped with LTS, DTA, and GFE blocks, DTA-Former achieves excellent classification results via hierarchical feature learning. Lastly, a novel Iterative Token Reconstruction (ITR) block is introduced for dense prediction whereby the semantic features of tokens and their semantic relationships are gradually optimized during iterative reconstruction. Based on ITR, we propose a new W-net architecture, which is more suitable for Transformer-based feature learning than the common U-net design. Extensive experiments demonstrate the superiority of our method. It achieves SOTA performance with up to 30$\times$ faster than prior point Transformers on ModelNet40, ShapeNet, and airborne MultiSpectral LiDAR (MS-LiDAR) datasets.
3D Learnable Supertoken Transformer for LiDAR Point Cloud Scene Segmentation
May 23, 2024



3D Transformers have achieved great success in point cloud understanding and representation. However, there is still considerable scope for further development in effective and efficient Transformers for large-scale LiDAR point cloud scene segmentation. This paper proposes a novel 3D Transformer framework, named 3D Learnable Supertoken Transformer (3DLST). The key contributions are summarized as follows. Firstly, we introduce the first Dynamic Supertoken Optimization (DSO) block for efficient token clustering and aggregating, where the learnable supertoken definition avoids the time-consuming pre-processing of traditional superpoint generation. Since the learnable supertokens can be dynamically optimized by multi-level deep features during network learning, they are tailored to the semantic homogeneity-aware token clustering. Secondly, an efficient Cross-Attention-guided Upsampling (CAU) block is proposed for token reconstruction from optimized supertokens. Thirdly, the 3DLST is equipped with a novel W-net architecture instead of the common U-net design, which is more suitable for Transformer-based feature learning. The SOTA performance on three challenging LiDAR datasets (airborne MultiSpectral LiDAR (MS-LiDAR) (89.3% of the average F1 score), DALES (80.2% of mIoU), and Toronto-3D dataset (80.4% of mIoU)) demonstrate the superiority of 3DLST and its strong adaptability to various LiDAR point cloud data (airborne MS-LiDAR, aerial LiDAR, and vehicle-mounted LiDAR data). Furthermore, 3DLST also achieves satisfactory results in terms of algorithm efficiency, which is up to 5x faster than previous best-performing methods.
Photorealistic 3D Urban Scene Reconstruction and Point Cloud Extraction using Google Earth Imagery and Gaussian Splatting
May 17, 20243D urban scene reconstruction and modelling is a crucial research area in remote sensing with numerous applications in academia, commerce, industry, and administration. Recent advancements in view synthesis models have facilitated photorealistic 3D reconstruction solely from 2D images. Leveraging Google Earth imagery, we construct a 3D Gaussian Splatting model of the Waterloo region centered on the University of Waterloo and are able to achieve view-synthesis results far exceeding previous 3D view-synthesis results based on neural radiance fields which we demonstrate in our benchmark. Additionally, we retrieved the 3D geometry of the scene using the 3D point cloud extracted from the 3D Gaussian Splatting model which we benchmarked against our Multi- View-Stereo dense reconstruction of the scene, thereby reconstructing both the 3D geometry and photorealistic lighting of the large-scale urban scene through 3D Gaussian Splatting
Dynamic Clustering Transformer Network for Point Cloud Segmentation
May 30, 2023



Point cloud segmentation is one of the most important tasks in computer vision with widespread scientific, industrial, and commercial applications. The research thereof has resulted in many breakthroughs in 3D object and scene understanding. Previous methods typically utilized hierarchical architectures for feature representation. However, the commonly used sampling and grouping methods in hierarchical networks are only based on point-wise three-dimensional coordinates, ignoring local semantic homogeneity of point clusters. Additionally, the prevalent Farthest Point Sampling (FPS) method is often a computational bottleneck. To address these issues, we propose a novel 3D point cloud representation network, called Dynamic Clustering Transformer Network (DCTNet). It has an encoder-decoder architecture, allowing for both local and global feature learning. Specifically, we propose novel semantic feature-based dynamic sampling and clustering methods in the encoder, which enables the model to be aware of local semantic homogeneity for local feature aggregation. Furthermore, in the decoder, we propose an efficient semantic feature-guided upsampling method. Our method was evaluated on an object-based dataset (ShapeNet), an urban navigation dataset (Toronto-3D), and a multispectral LiDAR dataset, verifying the performance of DCTNet across a wide variety of practical engineering applications. The inference speed of DCTNet is 3.8-16.8$\times$ faster than existing State-of-the-Art (SOTA) models on the ShapeNet dataset, while achieving an instance-wise mIoU of $86.6\%$, the current top score. Our method similarly outperforms previous methods on the other datasets, verifying it as the new State-of-the-Art in point cloud segmentation.
3DPCT: 3D Point Cloud Transformer with Dual Self-attention
Sep 21, 2022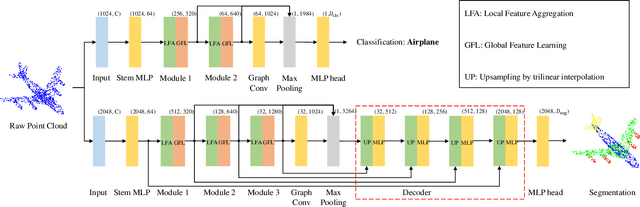
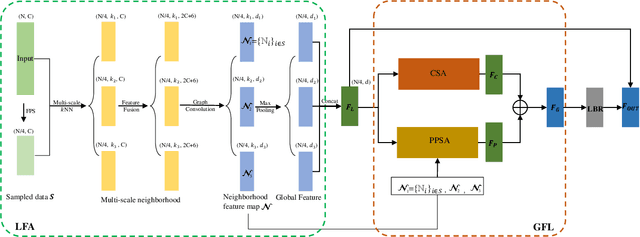
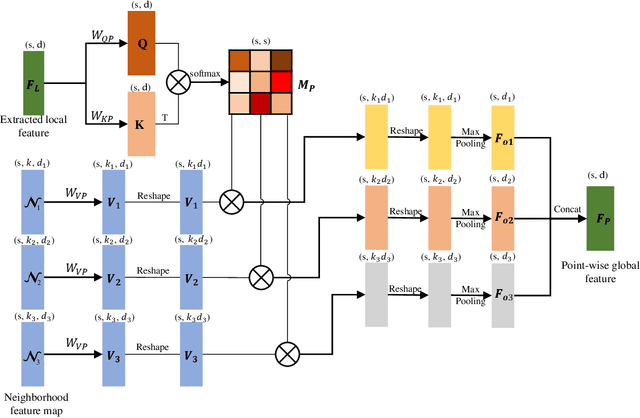
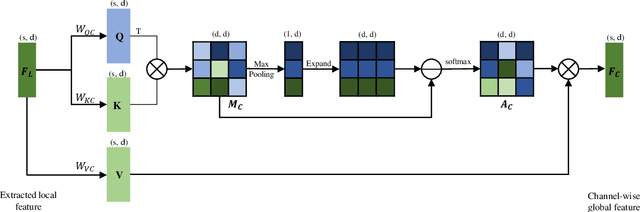
Transformers have resulted in remarkable achievements in the field of image processing. Inspired by this great success, the application of Transformers to 3D point cloud processing has drawn more and more attention. This paper presents a novel point cloud representational learning network, 3D Point Cloud Transformer with Dual Self-attention (3DPCT) and an encoder-decoder structure. Specifically, 3DPCT has a hierarchical encoder, which contains two local-global dual-attention modules for the classification task (three modules for the segmentation task), with each module consisting of a Local Feature Aggregation (LFA) block and a Global Feature Learning (GFL) block. The GFL block is dual self-attention, with both point-wise and channel-wise self-attention to improve feature extraction. Moreover, in LFA, to better leverage the local information extracted, a novel point-wise self-attention model, named as Point-Patch Self-Attention (PPSA), is designed. The performance is evaluated on both classification and segmentation datasets, containing both synthetic and real-world data. Extensive experiments demonstrate that the proposed method achieved state-of-the-art results on both classification and segmentation tasks.
MODNet: Multi-offset Point Cloud Denoising Network Customized for Multi-scale Patches
Sep 01, 2022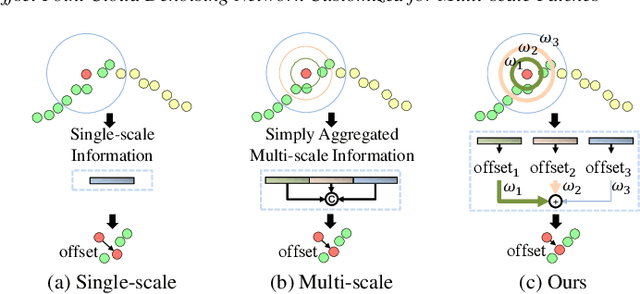
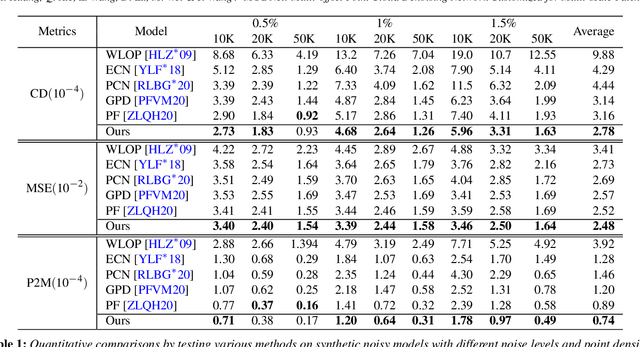
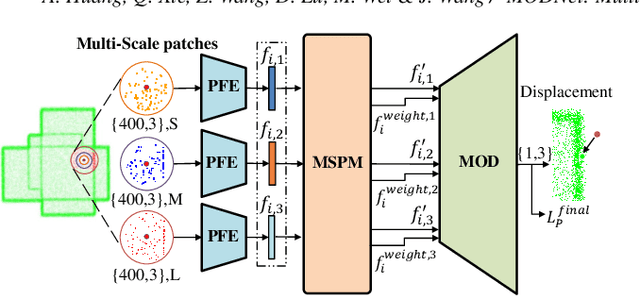
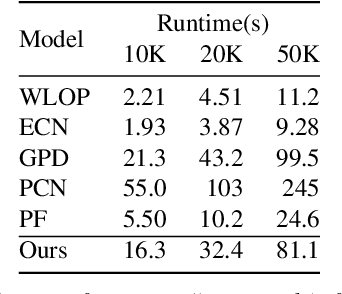
The intricacy of 3D surfaces often results cutting-edge point cloud denoising (PCD) models in surface degradation including remnant noise, wrongly-removed geometric details. Although using multi-scale patches to encode the geometry of a point has become the common wisdom in PCD, we find that simple aggregation of extracted multi-scale features can not adaptively utilize the appropriate scale information according to the geometric information around noisy points. It leads to surface degradation, especially for points close to edges and points on complex curved surfaces. We raise an intriguing question -- if employing multi-scale geometric perception information to guide the network to utilize multi-scale information, can eliminate the severe surface degradation problem? To answer it, we propose a Multi-offset Denoising Network (MODNet) customized for multi-scale patches. First, we extract the low-level feature of three scales patches by patch feature encoders. Second, a multi-scale perception module is designed to embed multi-scale geometric information for each scale feature and regress multi-scale weights to guide a multi-offset denoising displacement. Third, a multi-offset decoder regresses three scale offsets, which are guided by the multi-scale weights to predict the final displacement by weighting them adaptively. Experiments demonstrate that our method achieves new state-of-the-art performance on both synthetic and real-scanned datasets.
3DLG-Detector: 3D Object Detection via Simultaneous Local-Global Feature Learning
Aug 31, 2022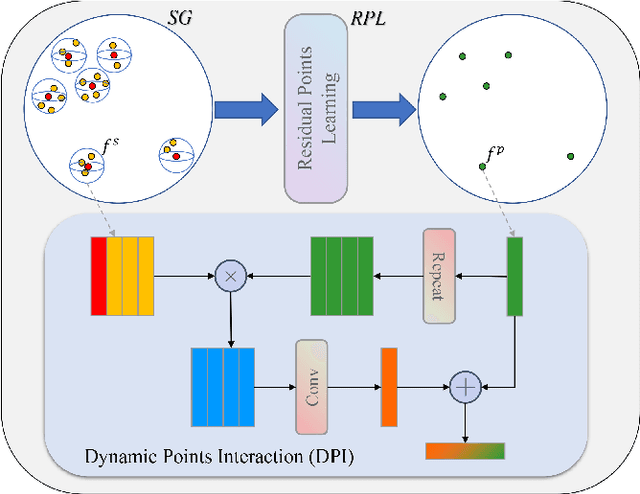
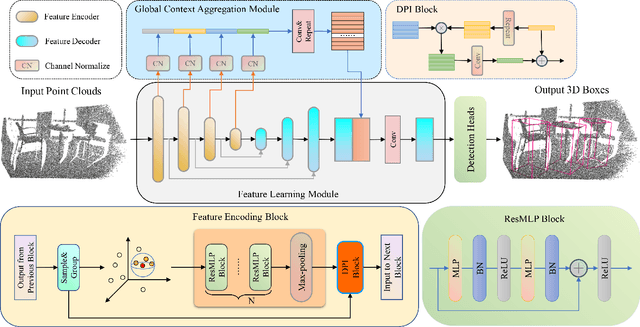
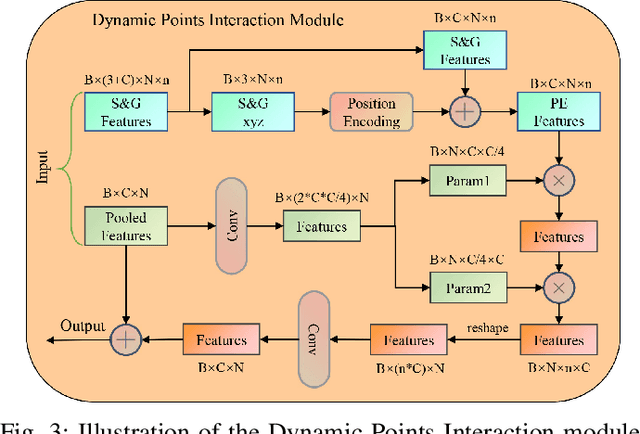

Capturing both local and global features of irregular point clouds is essential to 3D object detection (3OD). However, mainstream 3D detectors, e.g., VoteNet and its variants, either abandon considerable local features during pooling operations or ignore many global features in the whole scene context. This paper explores new modules to simultaneously learn local-global features of scene point clouds that serve 3OD positively. To this end, we propose an effective 3OD network via simultaneous local-global feature learning (dubbed 3DLG-Detector). 3DLG-Detector has two key contributions. First, it develops a Dynamic Points Interaction (DPI) module that preserves effective local features during pooling. Besides, DPI is detachable and can be incorporated into existing 3OD networks to boost their performance. Second, it develops a Global Context Aggregation module to aggregate multi-scale features from different layers of the encoder to achieve scene context-awareness. Our method shows improvements over thirteen competitors in terms of detection accuracy and robustness on both the SUN RGB-D and ScanNet datasets. Source code will be available upon publication.
Transformers in 3D Point Clouds: A Survey
May 16, 2022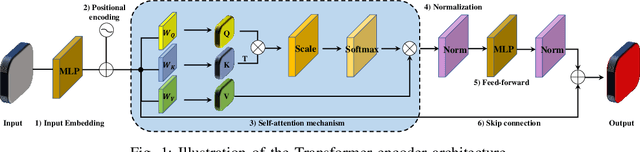
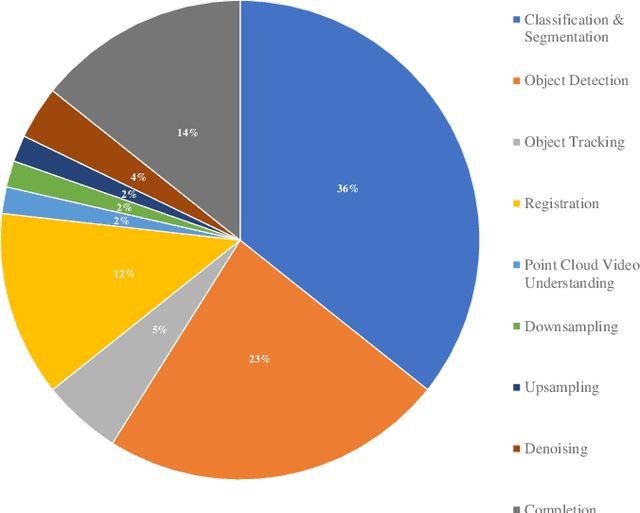
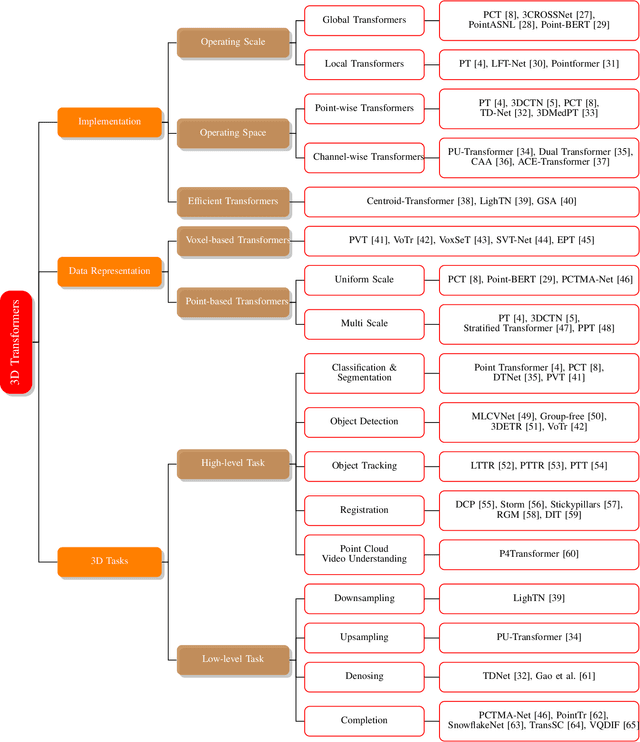
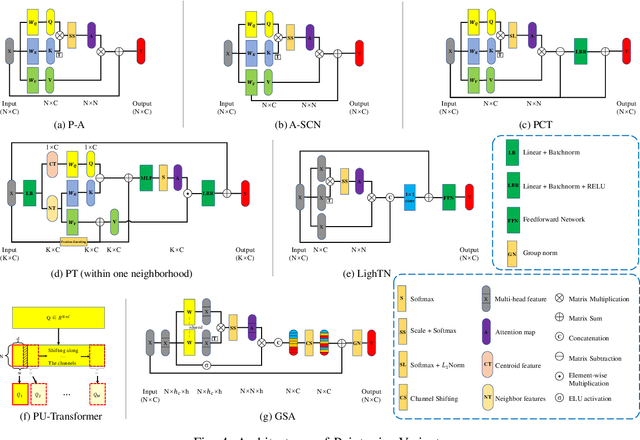
In recent years, Transformer models have been proven to have the remarkable ability of long-range dependencies modeling. They have achieved satisfactory results both in Natural Language Processing (NLP) and image processing. This significant achievement sparks great interest among researchers in 3D point cloud processing to apply them to various 3D tasks. Due to the inherent permutation invariance and strong global feature learning ability, 3D Transformers are well suited for point cloud processing and analysis. They have achieved competitive or even better performance compared to the state-of-the-art non-Transformer algorithms. This survey aims to provide a comprehensive overview of 3D Transformers designed for various tasks (e.g. point cloud classification, segmentation, object detection, and so on). We start by introducing the fundamental components of the general Transformer and providing a brief description of its application in 2D and 3D fields. Then, we present three different taxonomies (i.e., Transformer implementation-based taxonomy, data representation-based taxonomy, and task-based taxonomy) for method classification, which allows us to analyze involved methods from multiple perspectives. Furthermore, we also conduct an investigation of 3D self-attention mechanism variants designed for performance improvement. To demonstrate the superiority of 3D Transformers, we compare the performance of Transformer-based algorithms in terms of point cloud classification, segmentation, and object detection. Finally, we point out three potential future research directions, expecting to provide some benefit references for the development of 3D Transformers.