 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DPCT: 3D Point Cloud Transformer with Dual Self-attention
Paper and Code
Sep 21, 2022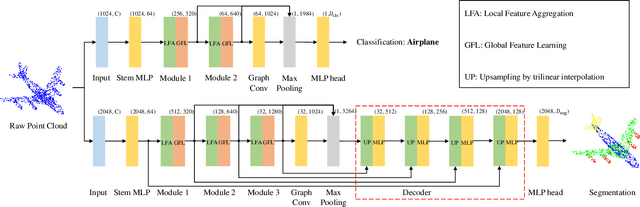
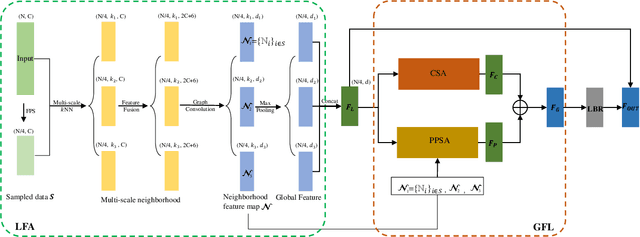
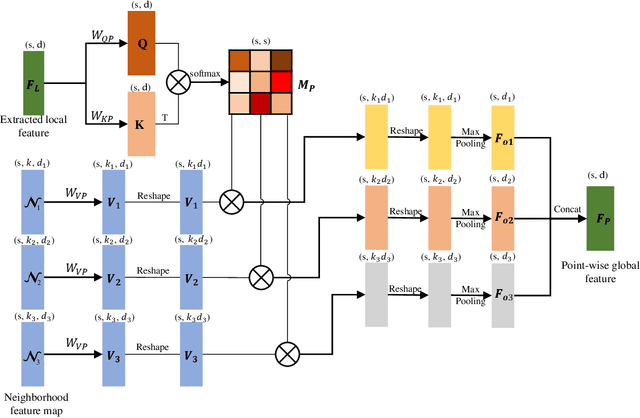
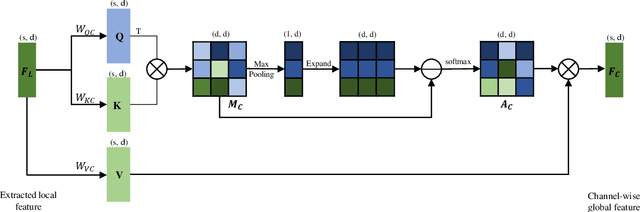
Transformers have resulted in remarkable achievements in the field of image processing. Inspired by this great success, the application of Transformers to 3D point cloud processing has drawn more and more attention. This paper presents a novel point cloud representational learning network, 3D Point Cloud Transformer with Dual Self-attention (3DPCT) and an encoder-decoder structure. Specifically, 3DPCT has a hierarchical encoder, which contains two local-global dual-attention modules for the classification task (three modules for the segmentation task), with each module consisting of a Local Feature Aggregation (LFA) block and a Global Feature Learning (GFL) block. The GFL block is dual self-attention, with both point-wise and channel-wise self-attention to improve feature extraction. Moreover, in LFA, to better leverage the local information extracted, a novel point-wise self-attention model, named as Point-Patch Self-Attention (PPSA), is designed. The performance is evaluated on both classification and segmentation datasets, containing both synthetic and real-world data. Extensive experiments demonstrate that the proposed method achieved state-of-the-art results on both classification and segmentation tasks.