 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Aware LLM Agents for Geospatial Data Retrieval: Design and Preliminary Adversarial Evaluation
Jun 13, 2026We present an LLM-driven framework for retrieving remote sensing data from cloud-based geospatial catalogues using natural language queries. The system converts user intent into structured API calls, enabling efficient access to satellite imagery and environmental datasets. The architecture integrates three agents: Guardrail for safety and policy enforcement, General-QA for intent interpretation, and Recommender-Analyst for schema-aware API call generation. This coordinated design ensures reliable, semantically aligned interaction with external data services. The modular framework is portable across platforms through API schema substitution and supports applications in environmental monitoring, disaster response, and climate analysis. It establishes a scalable interface between user intent and geospatial infrastructure, enabling streamlined and automated Earth observation workflows. Preliminary experiments under adversarial multi-turn settings show that prompt-level safety instructions improve robustness, although rare high-impact failures persist in API manipulation scenarios and highlight the need for adaptive, system-level defenses that balance safety, usability, and cost efficiency, which motivates the use of our intercept-level Guardrail agent.
Securing Multi-Agent GIS Systems: Risk Evaluation and Prompt Hardening Optimization
Jun 13, 2026Agentic systems are increasingly integrated with geographic information systems (GIS), where multi-agent coordination enables complex conversational and spatial analysis but introduces security risks. This work presents a security-oriented framework for risk identification, evaluation, and mitigation in a multi-agent GIS system while maintaining adaptability to broader agentic architectures. We test the agentic system of a commercial geospatial partner while developing a modular state-machine-based orchestration framework that abstracts agent behavior into reusable components. We evaluate robustness using a red-teaming framework with an adaptive attacker LLM and a deterministic judge that produces binary outcomes with supporting rationales across multi-turn attacks. We further improve resilience with a prompt optimization framework that treats prompts as structured signatures and injects adversarial demonstrations, enabling systematic security improvements without degrading task performance.
Rapid Forest Fuel Load Estimation via Virtual Remote Sensing and Metric-Scale Feed-Forward 3D Reconstruction
May 11, 2026Accurate quantification of forest coverage and combustible biomass (fuel load) is critical for wildfire risk assessment and ecosystem management. However, traditional methods relying on airborne LiDAR or field surveys are cost-prohibitive and time-intensive, while satellite imagery often lacks the vertical resolution required for canopy volume analysis. This paper proposes a novel, automated pipeline for rapid forest inventory using virtual remote sensing data derived from Google Earth Studio (GES). Our approach first generates low-altitude orbital imagery and camera poses for a target region. For dense 3D reconstruction, we employ Pi-Long, developed within the VGGT-Long framework. This model serves as a scalable extension of the Pi-3 feed-forward Transformer architecture. To address the inherent scale ambiguity in monocular reconstruction, we introduce a metric recovery module that aligns the reconstructed trajectory with GES ground truth poses via Sim(3) Umeyama optimization. The metric-scale point cloud is then orthogonally projected into Bird's-Eye-View (BEV) height and density maps. Finally, we employ a watershed-based segmentation algorithm combined with height variance analysis to classify tree species (conifer vs. broadleaf), calculate Leaf Area Index (LAI), and estimate total fuel load. Experimental results demonstrate that this pipeline offers a scalable, cost-effective alternative to physical scanning, enabling near-real-time estimation of forest biomass with high geometric consistency.
OpenWildlife: Open-Vocabulary Multi-Species Wildlife Detector for Geographically-Diverse Aerial Imagery
Jun 24, 2025We introduce OpenWildlife (OW), an open-vocabulary wildlife detector designed for multi-species identification in diverse aerial imagery. While existing automated methods perform well in specific settings, they often struggle to generalize across different species and environments due to limited taxonomic coverage and rigid model architectures. In contrast, OW leverages language-aware embeddings and a novel adaptation of the Grounding-DINO framework, enabling it to identify species specified through natural language inputs across both terrestrial and marine environments. Trained on 15 datasets, OW outperforms most existing methods, achieving up to \textbf{0.981} mAP50 with fine-tuning and \textbf{0.597} mAP50 on seven datasets featuring novel species. Additionally, we introduce an efficient search algorithm that combines k-nearest neighbors and breadth-first search to prioritize areas where social species are likely to be found. This approach captures over \textbf{95\%} of species while exploring only \textbf{33\%} of the available images. To support reproducibility, we publicly release our source code and dataset splits, establishing OW as a flexible, cost-effective solution for global biodiversity assessments.
Comparative and Interpretative Analysis of CNN and Transformer Models in Predicting Wildfire Spread Using Remote Sensing Data
Mar 18, 2025

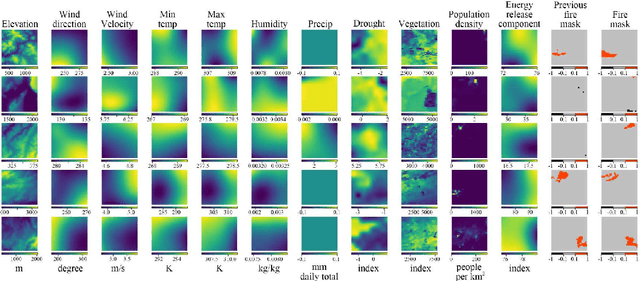

Facing the escalating threat of global wildfires, numerous computer vision techniques using remote sensing data have been applied in this area. However, the selection of deep learning methods for wildfire prediction remains uncertain due to the lack of comparative analysis in a quantitative and explainable manner, crucial for improving prevention measures and refining models. This study aims to thoroughly compare the performance, efficiency, and explainability of four prevalent deep learning architectures: Autoencoder, ResNet, UNet, and Transformer-based Swin-UNet. Employing a real-world dataset that includes nearly a decade of remote sensing data from California, U.S., these models predict the spread of wildfires for the following day. Through detailed quantitative comparison analysis, we discovered that Transformer-based Swin-UNet and UNet generally outperform Autoencoder and ResNet, particularly due to the advanced attention mechanisms in Transformer-based Swin-UNet and the efficient use of skip connections in both UNet and Transformer-based Swin-UNet, which contribute to superior predictive accuracy and model interpretability. Then we applied XAI techniques on all four models, this not only enhances the clarity and trustworthiness of models but also promotes focused improvements in wildfire prediction capabilities. The XAI analysis reveals that UNet and Transformer-based Swin-UNet are able to focus on critical features such as 'Previous Fire Mask', 'Drought', and 'Vegetation' more effectively than the other two models, while also maintaining balanced attention to the remaining features, leading to their superior performance. The insights from our thorough comparative analysis offer substantial implications for future model design and also provide guidance for model selection in different scenarios.
Language-Informed Hyperspectral Image Synthesis for Imbalanced-Small Sample Classification via Semi-Supervised Conditional Diffusion Model
Feb 28, 2025



Data augmentation effectively addresses the imbalanced-small sample data (ISSD) problem in hyperspectral image classification (HSIC). While most methodologies extend features in the latent space, few leverage text-driven generation to create realistic and diverse samples. Recently, text-guided diffusion models have gained significant attention due to their ability to generate highly diverse and high-quality images based on text prompts in natural image synthesis. Motivated by this, this paper proposes Txt2HSI-LDM(VAE), a novel language-informed hyperspectral image synthesis method to address the ISSD in HSIC. The proposed approach uses a denoising diffusion model, which iteratively removes Gaussian noise to generate hyperspectral samples conditioned on textual descriptions. First, to address the high-dimensionality of hyperspectral data, a universal variational autoencoder (VAE) is designed to map the data into a low-dimensional latent space, which provides stable features and reduces the inference complexity of diffusion model. Second, a semi-supervised diffusion model is designed to fully take advantage of unlabeled data. Random polygon spatial clipping (RPSC) and uncertainty estimation of latent feature (LF-UE) are used to simulate the varying degrees of mixing. Third, the VAE decodes HSI from latent space generated by the diffusion model with the language conditions as input. In our experiments, we fully evaluate synthetic samples' effectiveness from statistical characteristics and data distribution in 2D-PCA space. Additionally, visual-linguistic cross-attention is visualized on the pixel level to prove that our proposed model can capture the spatial layout and geometry of the generated data. Experiments demonstrate that the performance of the proposed Txt2HSI-LDM(VAE) surpasses the classical backbone models, state-of-the-art CNNs, and semi-supervised methods.
Spatial-Spectral Diffusion Contrastive Representation Network for Hyperspectral Image Classification
Feb 27, 2025



Although efficient extraction of discriminative spatial-spectral features is critical for hyperspectral images classification (HSIC), it is difficult to achieve these features due to factors such as the spatial-spectral heterogeneity and noise effect. This paper presents a Spatial-Spectral Diffusion Contrastive Representation Network (DiffCRN), based on denoising diffusion probabilistic model (DDPM) combined with contrastive learning (CL) for HSIC, with the following characteristics. First,to improve spatial-spectral feature representation, instead of adopting the UNets-like structure which is widely used for DDPM, we design a novel staged architecture with spatial self-attention denoising module (SSAD) and spectral group self-attention denoising module (SGSAD) in DiffCRN with improved efficiency for spectral-spatial feature learning. Second, to improve unsupervised feature learning efficiency, we design new DDPM model with logarithmic absolute error (LAE) loss and CL that improve the loss function effectiveness and increase the instance-level and inter-class discriminability. Third, to improve feature selection, we design a learnable approach based on pixel-level spectral angle mapping (SAM) for the selection of time steps in the proposed DDPM model in an adaptive and automatic manner. Last, to improve feature integration and classification, we design an Adaptive weighted addition modul (AWAM) and Cross time step Spectral-Spatial Fusion Module (CTSSFM) to fuse time-step-wise features and perform classification. Experiments conducted on widely used four HSI datasets demonstrate the improved performance of the proposed DiffCRN over the classical backbone models and state-of-the-art GAN, transformer models and other pretrained methods. The source code and pre-trained model will be made available publicly.
Digital Twin Buildings: 3D Modeling, GIS Integration, and Visual Descriptions Using Gaussian Splatting, ChatGPT/Deepseek, and Google Maps Platforms
Feb 09, 2025Urban digital twins are virtual replicas of cities that use multi-source data and data analytics to optimize urban planning, infrastructure management, and decision-making. Towards this, we propose a framework focused on the single-building scale. By connecting to cloud mapping platforms such as Google Map Platforms APIs, by leveraging state-of-the-art multi-agent Large Language Models data analysis using ChatGPT(4o) and Deepseek-V3/R1, and by using our Gaussian Splatting-based mesh extraction pipeline, our Digital Twin Buildings framework can retrieve a building's 3D model, visual descriptions, and achieve cloud-based mapping integration with large language model-based data analytics using a building's address, postal code, or geographic coordinates.
Gaussian Building Mesh (GBM): Extract a Building's 3D Mesh with Google Earth and Gaussian Splatting
Jan 07, 2025



Recently released open-source pre-trained foundational image segmentation and object detection models (SAM2+GroundingDINO) allow for geometrically consistent segmentation of objects of interest in multi-view 2D images. Users can use text-based or click-based prompts to segment objects of interest without requiring labeled training datasets. Gaussian Splatting allows for the learning of the 3D representation of a scene's geometry and radiance based on 2D images. Combining Google Earth Studio, SAM2+GroundingDINO, 2D Gaussian Splatting, and our improvements in mask refinement based on morphological operations and contour simplification, we created a pipeline to extract the 3D mesh of any building based on its name, address, or geographic coordinates.
Advancements in Road Lane Mapping: Comparative Fine-Tuning Analysis of Deep Learning-based Semantic Segmentation Methods Using Aerial Imagery
Oct 08, 2024

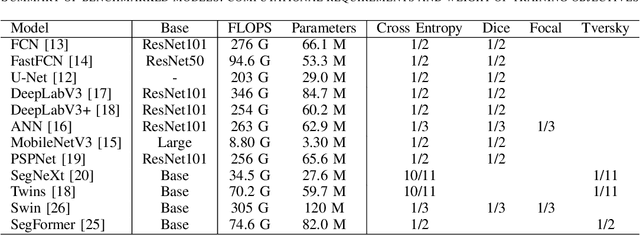
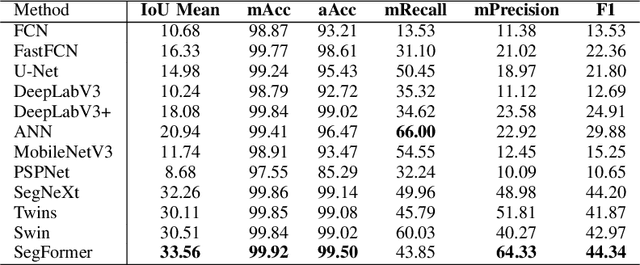
This research addresses the need for high-definition (HD) maps for autonomous vehicles (AVs), focusing on road lane information derived from aerial imagery. While Earth observation data offers valuable resources for map creation, specialized models for road lane extraction are still underdeveloped in remote sensing. In this study, we perform an extensive comparison of twelve foundational deep learning-based semantic segmentation models for road lane marking extraction from high-definition remote sensing images, assessing their performance under transfer learning with partially labeled datasets. These models were fine-tuned on the partially labeled Waterloo Urban Scene dataset, and pre-trained on the SkyScapes dataset, simulating a likely scenario of real-life model deployment under partial labeling. We observed and assessed the fine-tuning performance and overall performance. Models showed significant performance improvements after fine-tuning, with mean IoU scores ranging from 33.56% to 76.11%, and recall ranging from 66.0% to 98.96%. Transformer-based models outperformed convolutional neural networks, emphasizing the importance of model pre-training and fine-tuning in enhancing HD map development for AV navigation.