 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Point Transformer with Dynamic Token Aggregating for Point Cloud Processing
Paper and Code
May 23, 2024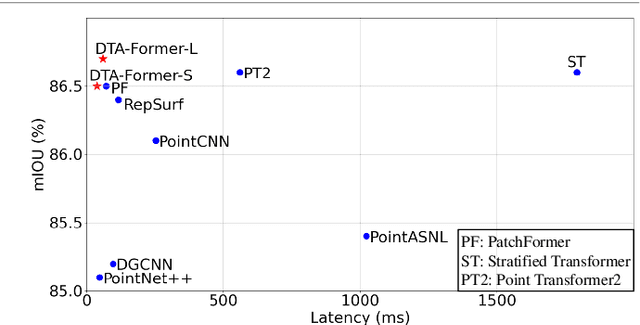
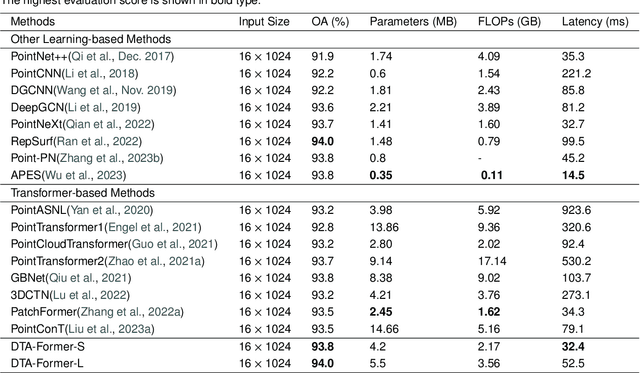
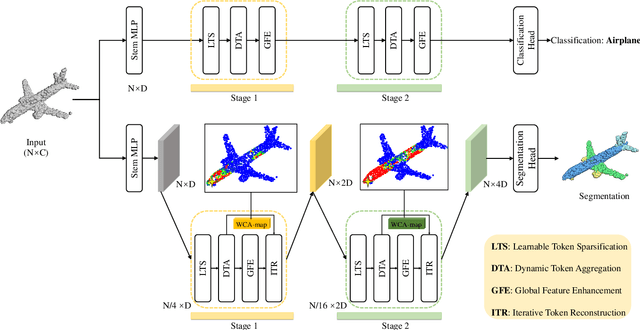
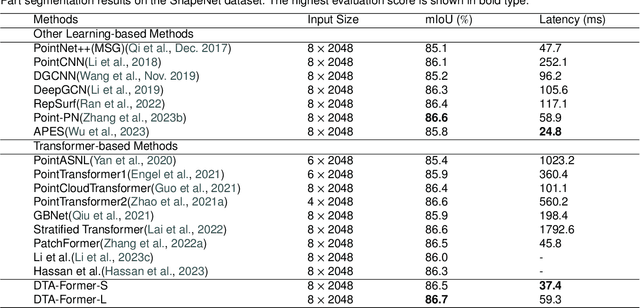
Recently, point cloud processing and analysis have made great progress due to the development of 3D Transformers. However, existing 3D Transformer methods usually are computationally expensive and inefficient due to their huge and redundant attention maps. They also tend to be slow due to requiring time-consuming point cloud sampling and grouping processes. To address these issues, we propose an efficient point TransFormer with Dynamic Token Aggregating (DTA-Former) for point cloud representation and processing. Firstly, we propose an efficient Learnable Token Sparsification (LTS) block, which considers both local and global semantic information for the adaptive selection of key tokens. Secondly, to achieve the feature aggregation for sparsified tokens, we present the first Dynamic Token Aggregating (DTA) block in the 3D Transformer paradigm, providing our model with strong aggregated features while preventing information loss. After that, a dual-attention Transformer-based Global Feature Enhancement (GFE) block is used to improve the representation capability of the model. Equipped with LTS, DTA, and GFE blocks, DTA-Former achieves excellent classification results via hierarchical feature learning. Lastly, a novel Iterative Token Reconstruction (ITR) block is introduced for dense prediction whereby the semantic features of tokens and their semantic relationships are gradually optimized during iterative reconstruction. Based on ITR, we propose a new W-net architecture, which is more suitable for Transformer-based feature learning than the common U-net design. Extensive experiments demonstrate the superiority of our method. It achieves SOTA performance with up to 30$\times$ faster than prior point Transformers on ModelNet40, ShapeNet, and airborne MultiSpectral LiDAR (MS-LiDAR) datasets.