 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Forest Fuel Load Estimation via Virtual Remote Sensing and Metric-Scale Feed-Forward 3D Reconstruction
May 11, 2026Accurate quantification of forest coverage and combustible biomass (fuel load) is critical for wildfire risk assessment and ecosystem management. However, traditional methods relying on airborne LiDAR or field surveys are cost-prohibitive and time-intensive, while satellite imagery often lacks the vertical resolution required for canopy volume analysis. This paper proposes a novel, automated pipeline for rapid forest inventory using virtual remote sensing data derived from Google Earth Studio (GES). Our approach first generates low-altitude orbital imagery and camera poses for a target region. For dense 3D reconstruction, we employ Pi-Long, developed within the VGGT-Long framework. This model serves as a scalable extension of the Pi-3 feed-forward Transformer architecture. To address the inherent scale ambiguity in monocular reconstruction, we introduce a metric recovery module that aligns the reconstructed trajectory with GES ground truth poses via Sim(3) Umeyama optimization. The metric-scale point cloud is then orthogonally projected into Bird's-Eye-View (BEV) height and density maps. Finally, we employ a watershed-based segmentation algorithm combined with height variance analysis to classify tree species (conifer vs. broadleaf), calculate Leaf Area Index (LAI), and estimate total fuel load. Experimental results demonstrate that this pipeline offers a scalable, cost-effective alternative to physical scanning, enabling near-real-time estimation of forest biomass with high geometric consistency.
SparseGF: A Height-Aware Sparse Segmentation Framework with Context Compression for Robust Ground Filtering Across Urban to Natural Scenes
Apr 23, 2026High-quality digital terrain models derived from airborne laser scanning (ALS) data are essential for a wide range of geospatial analyses, and their generation typically relies on robust ground filtering (GF) to separate point clouds across diverse landscapes into ground and non-ground parts. Although current deep-learning-based GF methods have demonstrated impressive performance, especially in specific challenging terrains, their cross-scene generalization remains limited by two persistent issues: the context-detail dilemma in large-scale processing due to limited computational resources, and the random misclassification of tall objects arising from classification-only optimization. To overcome these limitations, we propose SparseGF, a height-aware sparse segmentation framework enhanced with context compression. It is built upon three key innovations: (1) a convex-mirror-inspired context compression module that condenses expansive contexts into compact representations while preserving central details; (2) a hybrid sparse voxel-point network architecture that effectively interprets compressed representations while mitigating compression-induced geometric distortion; and (3) a height-aware loss function that explicitly enforces topographic elevation priors during training to suppress random misclassification of tall objects. Extensive evaluations on two large-scale ALS benchmark datasets demonstrate that SparseGF delivers robust GF across urban to natural terrains, achieving leading performance in complex urban scenes, competitive results on mixed terrains, and moderate yet non-catastrophic accuracy in densely forested steep areas. This work offers new insights into deep-learning-based GF research and encourages further exploration toward truly cross-scene generalization for large-scale environmental monitoring.
KitchenTwin: Semantically and Geometrically Grounded 3D Kitchen Digital Twins
Mar 25, 2026Embodied AI training and evaluation require object-centric digital twin environments with accurate metric geometry and semantic grounding. Recent transformer-based feedforward reconstruction methods can efficiently predict global point clouds from sparse monocular videos, yet these geometries suffer from inherent scale ambiguity and inconsistent coordinate conventions. This mismatch prevents the reliable fusion of these dimensionless point cloud predictions with locally reconstructed object meshes. We propose a novel scale-aware 3D fusion framework that registers visually grounded object meshes with transformer-predicted global point clouds to construct metrically consistent digital twins. Our method introduces a Vision-Language Model (VLM)-guided geometric anchor mechanism that resolves this fundamental coordinate mismatch by recovering an accurate real-world metric scale. To fuse these networks, we propose a geometry-aware registration pipeline that explicitly enforces physical plausibility through gravity-aligned vertical estimation, Manhattan-world structural constraints, and collision-free local refinement. Experiments on real indoor kitchen environments demonstrate improved cross-network object alignment and geometric consistency for downstream tasks, including multi-primitive fitting and metric measurement. We additionally introduce an open-source indoor digital twin dataset with metrically scaled scenes and semantically grounded and registered object-centric mesh annotations.
Trustworthy Data-Driven Wildfire Risk Prediction and Understanding in Western Canada
Jan 04, 2026In recent decades, the intensification of wildfire activity in western Canada has resulted in substantial socio-economic and environmental losses. Accurate wildfire risk prediction is hindered by the intrinsic stochasticity of ignition and spread and by nonlinear interactions among fuel conditions, meteorology, climate variability, topography, and human activities, challenging the reliability and interpretability of purely data-driven models. We propose a trustworthy data-driven wildfire risk prediction framework based on long-sequence, multi-scale temporal modeling, which integrates heterogeneous drivers while explicitly quantifying predictive uncertainty and enabling process-level interpretation. Evaluated over western Canada during the record-breaking 2023 and 2024 fire seasons, the proposed model outperforms existing time-series approaches, achieving an F1 score of 0.90 and a PR-AUC of 0.98 with low computational cost. Uncertainty-aware analysis reveals structured spatial and seasonal patterns in predictive confidence, highlighting increased uncertainty associated with ambiguous predictions and spatiotemporal decision boundaries. SHAP-based interpretation provides mechanistic understanding of wildfire controls, showing that temperature-related drivers dominate wildfire risk in both years, while moisture-related constraints play a stronger role in shaping spatial and land-cover-specific contrasts in 2024 compared to the widespread hot and dry conditions of 2023. Data and code are available at https://github.com/SynUW/mmFire.
DVGBench: Implicit-to-Explicit Visual Grounding Benchmark in UAV Imagery with Large Vision-Language Models
Jan 02, 2026Remote sensing (RS) large vision-language models (LVLMs) have shown strong promise across visual grounding (VG) tasks. However, existing RS VG datasets predominantly rely on explicit referring expressions-such as relative position, relative size, and color cues-thereby constraining performance on implicit VG tasks that require scenario-specific domain knowledge. This article introduces DVGBench, a high-quality implicit VG benchmark for drones, covering six major application scenarios: traffic, disaster, security, sport, social activity, and productive activity. Each object provides both explicit and implicit queries. Based on the dataset, we design DroneVG-R1, an LVLM that integrates the novel Implicit-to-Explicit Chain-of-Thought (I2E-CoT) within a reinforcement learning paradigm. This enables the model to take advantage of scene-specific expertise, converting implicit references into explicit ones and thus reducing grounding difficulty. Finally, an evaluation of mainstream models on both explicit and implicit VG tasks reveals substantial limitations in their reasoning capabilities. These findings provide actionable insights for advancing the reasoning capacity of LVLMs for drone-based agents. The code and datasets will be released at https://github.com/zytx121/DVGBench
Cautious Weight Decay
Oct 14, 2025We introduce Cautious Weight Decay (CWD), a one-line, optimizer-agnostic modification that applies weight decay only to parameter coordinates whose signs align with the optimizer update. Unlike standard decoupled decay, which implicitly optimizes a regularized or constrained objective, CWD preserves the original loss and admits a bilevel interpretation: it induces sliding-mode behavior upon reaching the stationary manifold, allowing it to search for locally Pareto-optimal stationary points of the unmodified objective. In practice, CWD is a drop-in change for optimizers such as AdamW, Lion, and Muon, requiring no new hyperparameters or additional tuning. For language model pre-training and ImageNet classification, CWD consistently improves final loss and accuracy at million- to billion-parameter scales.
TDRM: Smooth Reward Models with Temporal Difference for LLM RL and Inference
Sep 18, 2025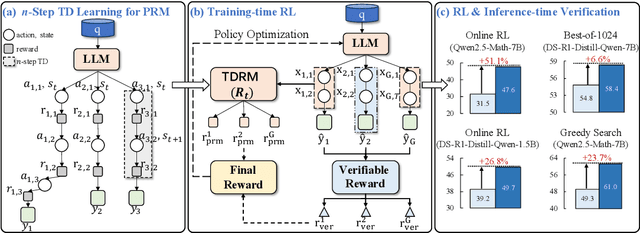
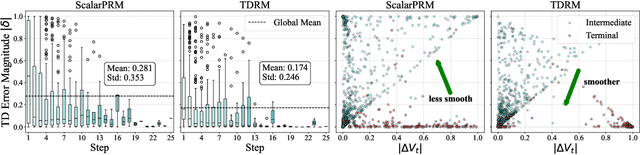

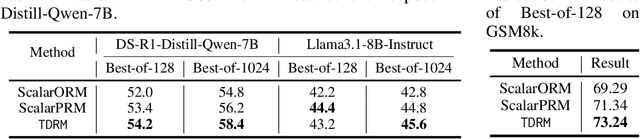
Reward models are central to both reinforcement learning (RL) with language models and inference-time verification. However, existing reward models often lack temporal consistency, leading to ineffective policy updates and unstable RL training. We introduce TDRM, a method for learning smoother and more reliable reward models by minimizing temporal differences during training. This temporal-difference (TD) regularization produces smooth rewards and improves alignment with long-term objectives. Incorporating TDRM into the actor-critic style online RL loop yields consistent empirical gains. It is worth noting that TDRM is a supplement to verifiable reward methods, and both can be used in series. Experiments show that TD-trained process reward models (PRMs) improve performance across Best-of-N (up to 6.6%) and tree-search (up to 23.7%) settings. When combined with Reinforcement Learning with Verifiable Rewards (RLVR), TD-trained PRMs lead to more data-efficient RL -- achieving comparable performance with just 2.5k data to what baseline methods require 50.1k data to attain -- and yield higher-quality language model policies on 8 model variants (5 series), e.g., Qwen2.5-(0.5B, 1,5B), GLM4-9B-0414, GLM-Z1-9B-0414, Qwen2.5-Math-(1.5B, 7B), and DeepSeek-R1-Distill-Qwen-(1.5B, 7B). We release all code at https://github.com/THUDM/TDRM.
Maps for Autonomous Driving: Full-process Survey and Frontiers
Sep 16, 2025Maps have always been an essential component of autonomous driving. With the advancement of autonomous driving technology, both the representation and production process of maps have evolved substantially. The article categorizes the evolution of maps into three stages: High-Definition (HD) maps, Lightweight (Lite) maps, and Implicit maps. For each stage, we provide a comprehensive review of the map production workflow, with highlighting technical challenges involved and summarizing relevant solutions proposed by the academic community. Furthermore, we discuss cutting-edge research advances in map representations and explore how these innovations can be integrated into end-to-end autonomous driving frameworks.
SAGOnline: Segment Any Gaussians Online
Aug 11, 20253D Gaussian Splatting (3DGS) has emerged as a powerful paradigm for explicit 3D scene representation, yet achieving efficient and consistent 3D segmentation remains challenging. Current methods suffer from prohibitive computational costs, limited 3D spatial reasoning, and an inability to track multiple objects simultaneously. We present Segment Any Gaussians Online (SAGOnline), a lightweight and zero-shot framework for real-time 3D segmentation in Gaussian scenes that addresses these limitations through two key innovations: (1) a decoupled strategy that integrates video foundation models (e.g., SAM2) for view-consistent 2D mask propagation across synthesized views; and (2) a GPU-accelerated 3D mask generation and Gaussian-level instance labeling algorithm that assigns unique identifiers to 3D primitives, enabling lossless multi-object tracking and segmentation across views. SAGOnline achieves state-of-the-art performance on NVOS (92.7% mIoU) and Spin-NeRF (95.2% mIoU) benchmarks, outperforming Feature3DGS, OmniSeg3D-gs, and SA3D by 15--1500 times in inference speed (27 ms/frame). Qualitative results demonstrate robust multi-object segmentation and tracking in complex scenes. Our contributions include: (i) a lightweight and zero-shot framework for 3D segmentation in Gaussian scenes, (ii) explicit labeling of Gaussian primitives enabling simultaneous segmentation and tracking, and (iii) the effective adaptation of 2D video foundation models to the 3D domain. This work allows real-time rendering and 3D scene understanding, paving the way for practical AR/VR and robotic applications.
PointGauss: Point Cloud-Guided Multi-Object Segmentation for Gaussian Splatting
Aug 01, 2025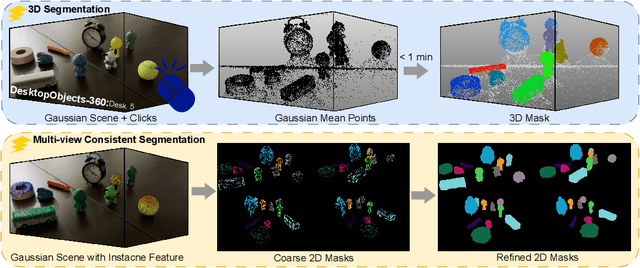
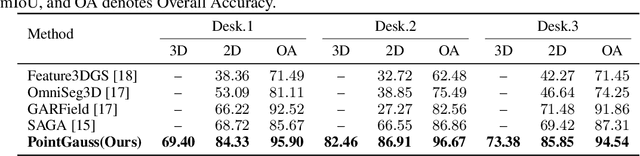
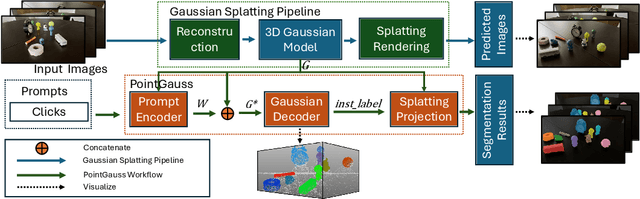
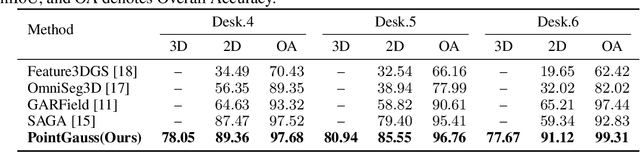
We introduce PointGauss, a novel point cloud-guided framework for real-time multi-object segmentation in Gaussian Splatting representations. Unlike existing methods that suffer from prolonged initialization and limited multi-view consistency, our approach achieves efficient 3D segmentation by directly parsing Gaussian primitives through a point cloud segmentation-driven pipeline. The key innovation lies in two aspects: (1) a point cloud-based Gaussian primitive decoder that generates 3D instance masks within 1 minute, and (2) a GPU-accelerated 2D mask rendering system that ensures multi-view consistency. Extensive experiments demonstrate significant improvements over previous state-of-the-art methods, achieving performance gains of 1.89 to 31.78% in multi-view mIoU, while maintaining superior computational efficiency. To address the limitations of current benchmarks (single-object focus, inconsistent 3D evaluation, small scale, and partial coverage), we present DesktopObjects-360, a novel comprehensive dataset for 3D segmentation in radiance fields, featuring: (1) complex multi-object scenes, (2) globally consistent 2D annotations, (3) large-scale training data (over 27 thousand 2D masks), (4) full 360{\deg} coverage, and (5) 3D evaluation masks.