 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Limits of Long-Context Reasoning in Automated Bug Fixing
Feb 17, 2026Rapidly increasing context lengths have led to the assumption that large language models (LLMs) can directly reason over entire codebases. Concurrently, recent advances in LLMs have enabled strong performance on software engineering benchmarks, particularly when paired with agentic workflows. In this work, we systematically evaluate whether current LLMs can reliably perform long-context code debugging and patch generation. Using SWE-bench Verified as a controlled experimental setting, we first evaluate state-of-the-art models within an agentic harness (mini-SWE-agent), where performance improves substantially: GPT-5-nano achieves up to a 31\% resolve rate on 100 samples, and open-source models such as Deepseek-R1-0528 obtain competitive results. However, token-level analysis shows that successful agentic trajectories typically remain under 20k tokens, and that longer accumulated contexts correlate with lower success rates, indicating that agentic success primarily arises from task decomposition into short-context steps rather than effective long-context reasoning. To directly test long-context capability, we construct a data pipeline where we artificially inflate the context length of the input by placing the relevant files into the context (ensuring perfect retrieval recall); we then study single-shot patch generation under genuinely long contexts (64k-128k tokens). Despite this setup, performance degrades sharply: Qwen3-Coder-30B-A3B achieves only a 7\% resolve rate at 64k context, while GPT-5-nano solves none of the tasks. Qualitative analysis reveals systematic failure modes, including hallucinated diffs, incorrect file targets, and malformed patch headers. Overall, our findings highlight a significant gap between nominal context length and usable context capacity in current LLMs, and suggest that existing agentic coding benchmarks do not meaningfully evaluate long-context reasoning.
Training Domain Draft Models for Speculative Decoding: Best Practices and Insights
Mar 10, 2025



Speculative decoding is an effective method for accelerating inference of large language models (LLMs) by employing a small draft model to predict the output of a target model. However, when adapting speculative decoding to domain-specific target models, the acceptance rate of the generic draft model drops significantly due to domain shift. In this work, we systematically investigate knowledge distillation techniques for training domain draft models to improve their speculation accuracy. We compare white-box and black-box distillation approaches and explore their effectiveness in various data accessibility scenarios, including historical user queries, curated domain data, and synthetically generated alignment data. Our experiments across Function Calling, Biology, and Chinese domains show that offline distillation consistently outperforms online distillation by 11% to 25%, white-box distillation surpasses black-box distillation by 2% to 10%, and data scaling trends hold across domains. Additionally, we find that synthetic data can effectively align draft models and achieve 80% to 93% of the performance of training on historical user queries. These findings provide practical guidelines for training domain-specific draft models to improve speculative decoding efficiency.
Composition of Experts: A Modular Compound AI System Leveraging Large Language Models
Dec 02, 2024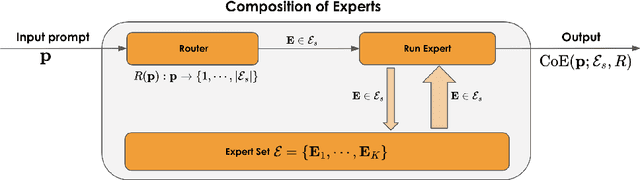
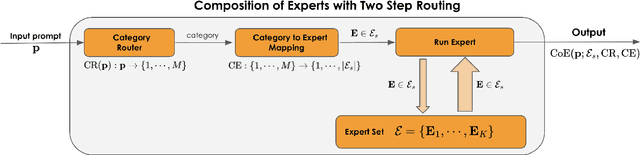
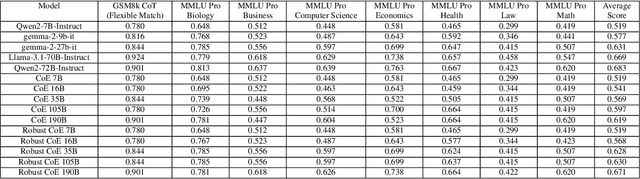
Large Language Models (LLMs) have achieved remarkable advancements, but their monolithic nature presents challenges in terms of scalability, cost, and customization. This paper introduces the Composition of Experts (CoE), a modular compound AI system leveraging multiple expert LLMs. CoE leverages a router to dynamically select the most appropriate expert for a given input, enabling efficient utilization of resources and improved performance. We formulate the general problem of training a CoE and discuss inherent complexities associated with it. We propose a two-step routing approach to address these complexities that first uses a router to classify the input into distinct categories followed by a category-to-expert mapping to obtain desired experts. CoE offers a flexible and cost-effective solution to build compound AI systems. Our empirical evaluation demonstrates the effectiveness of CoE in achieving superior performance with reduced computational overhead. Given that CoE comprises of many expert LLMs it has unique system requirements for cost-effective serving. We present an efficient implementation of CoE leveraging SambaNova SN40L RDUs unique three-tiered memory architecture. CoEs obtained using open weight LLMs Qwen/Qwen2-7B-Instruct, google/gemma-2-9b-it, google/gemma-2-27b-it, meta-llama/Llama-3.1-70B-Instruct and Qwen/Qwen2-72B-Instruct achieve a score of $59.4$ with merely $31$ billion average active parameters on Arena-Hard and a score of $9.06$ with $54$ billion average active parameters on MT-Bench.
Constructing Domain-Specific Evaluation Sets for LLM-as-a-judge
Aug 16, 2024



Large Language Models (LLMs) have revolutionized the landscape of machine learning, yet current benchmarks often fall short in capturing the diverse behavior of these models in real-world applications. A benchmark's usefulness is determined by its ability to clearly differentiate between models of varying capabilities (separability) and closely align with human preferences. Existing frameworks like Alpaca-Eval 2.0 LC \cite{dubois2024lengthcontrolledalpacaevalsimpleway} and Arena-Hard v0.1 \cite{li2024crowdsourced} are limited by their focus on general-purpose queries and lack of diversity across domains such as law, medicine, and multilingual contexts. In this paper, we address these limitations by introducing a novel data pipeline that curates diverse, domain-specific evaluation sets tailored for LLM-as-a-Judge frameworks. Our approach leverages a combination of manual curation, semi-supervised learning to generate clusters, and stratified sampling to ensure balanced representation across a wide range of domains and languages. The resulting evaluation set, which includes 1573 samples across 14 categories, demonstrates high separability (84\%) across ten top-ranked models, and agreement (84\%) with Chatbot Arena and (0.915) Spearman correlation. The agreement values are 9\% better than Arena Hard and 20\% better than AlpacaEval 2.0 LC, while the Spearman coefficient is 0.7 more than the next best benchmark, showcasing a significant improvement in the usefulness of the benchmark. We further provide an open-source evaluation tool that enables fine-grained analysis of model performance across user-defined categories, offering valuable insights for practitioners. This work contributes to the ongoing effort to enhance the transparency, diversity, and effectiveness of LLM evaluation methodologies.
BlurNet: Defense by Filtering the Feature Maps
Aug 06, 2019


Recently, the field of adversarial machine learning has been garnering attention by showing that state-of-the-art deep neural networks are vulnerable to adverserial examples, stemming from small perturbations being added to the input image. Adversarial examples are generated by a malicious adversary by obtaining access to the model parameters, such as gradient information, to alter the input or by attacking a substitute model and transferring those malicious examples over to attack the victim model. Specifically, one of these attack algorithms, Robust Physical Perturbations ($RP_2$), generates adverserial images of stop signs with black and white stickers to achieve high targeted misclassification rates against standard-architecture traffic sign classifiers. In this paper, we propose BlurNet, a defense against the $RP_2$ attack. First, we motivate the defense with a frequency analysis of the first layer feature maps of the network on the LISA dataset by demonstrating high frequency noise is introduced into the input image by the $RP_2$ algorithm. To alleviate the high frequency, we introduce a depthwise convolution layer of standard blur kernels after the first layer. Finally, we present a regularization scheme to incorporate this low-pass filtering behavior into the training regime of the network.