 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Oct 06, 2025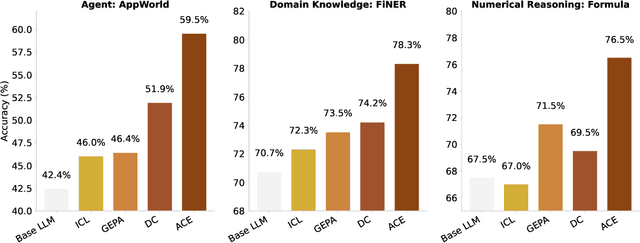
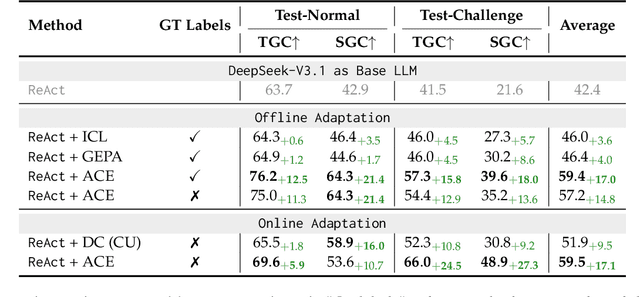
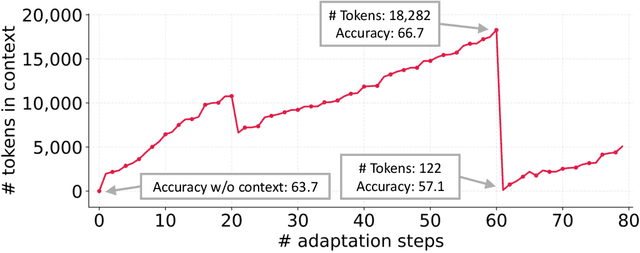
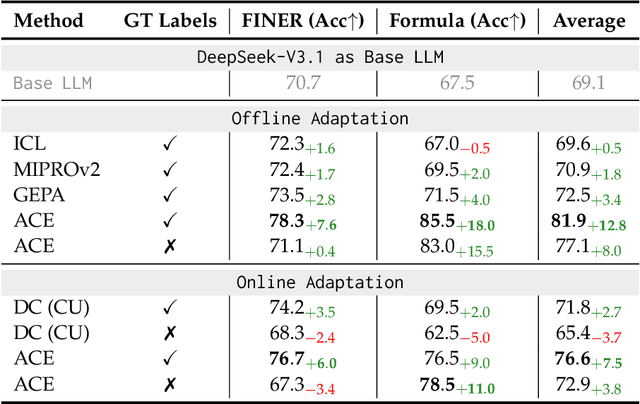
Large language model (LLM) applications such as agents and domain-specific reasoning increasingly rely on context adaptation -- modifying inputs with instructions, strategies, or evidence, rather than weight updates. Prior approaches improve usability but often suffer from brevity bias, which drops domain insights for concise summaries, and from context collapse, where iterative rewriting erodes details over time. Building on the adaptive memory introduced by Dynamic Cheatsheet, we introduce ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks that accumulate, refine, and organize strategies through a modular process of generation, reflection, and curation. ACE prevents collapse with structured, incremental updates that preserve detailed knowledge and scale with long-context models. Across agent and domain-specific benchmarks, ACE optimizes contexts both offline (e.g., system prompts) and online (e.g., agent memory), consistently outperforming strong baselines: +10.6% on agents and +8.6% on finance, while significantly reducing adaptation latency and rollout cost. Notably, ACE could adapt effectively without labeled supervision and instead by leveraging natural execution feedback. On the AppWorld leaderboard, ACE matches the top-ranked production-level agent on the overall average and surpasses it on the harder test-challenge split, despite using a smaller open-source model. These results show that comprehensive, evolving contexts enable scalable, efficient, and self-improving LLM systems with low overhead.
Synthetic Document Question Answering in Hungarian
May 29, 2025Modern VLMs have achieved near-saturation accuracy in English document visual question-answering (VQA). However, this task remains challenging in lower resource languages due to a dearth of suitable training and evaluation data. In this paper we present scalable methods for curating such datasets by focusing on Hungarian, approximately the 17th highest resource language on the internet. Specifically, we present HuDocVQA and HuDocVQA-manual, document VQA datasets that modern VLMs significantly underperform on compared to English DocVQA. HuDocVQA-manual is a small manually curated dataset based on Hungarian documents from Common Crawl, while HuDocVQA is a larger synthetically generated VQA data set from the same source. We apply multiple rounds of quality filtering and deduplication to HuDocVQA in order to match human-level quality in this dataset. We also present HuCCPDF, a dataset of 117k pages from Hungarian Common Crawl PDFs along with their transcriptions, which can be used for training a model for Hungarian OCR. To validate the quality of our datasets, we show how finetuning on a mixture of these datasets can improve accuracy on HuDocVQA for Llama 3.2 11B Instruct by +7.2%. Our datasets and code will be released to the public to foster further research in multilingual DocVQA.
Distributed LLMs and Multimodal Large Language Models: A Survey on Advances, Challenges, and Future Directions
Mar 20, 2025Language models (LMs) are machine learning models designed to predict linguistic patterns by estimating the probability of word sequences based on large-scale datasets, such as text. LMs have a wide range of applications in natural language processing (NLP) tasks, including autocomplete and machine translation. Although larger datasets typically enhance LM performance, scalability remains a challenge due to constraints in computational power and resources. Distributed computing strategies offer essential solutions for improving scalability and managing the growing computational demand. Further, the use of sensitive datasets in training and deployment raises significant privacy concerns. Recent research has focused on developing decentralized techniques to enable distributed training and inference while utilizing diverse computational resources and enabling edge AI. This paper presents a survey on distributed solutions for various LMs, including large language models (LLMs), vision language models (VLMs), multimodal LLMs (MLLMs), and small language models (SLMs). While LLMs focus on processing and generating text, MLLMs are designed to handle multiple modalities of data (e.g., text, images, and audio) and to integrate them for broader applications. To this end, this paper reviews key advancements across the MLLM pipeline, including distributed training, inference, fine-tuning, and deployment, while also identifying the contributions, limitations, and future areas of improvement. Further, it categorizes the literature based on six primary focus areas of decentralization. Our analysis describes gaps in current methodologies for enabling distributed solutions for LMs and outline future research directions, emphasizing the need for novel solutions to enhance the robustness and applicability of distributed LMs.
LLMs Know What to Drop: Self-Attention Guided KV Cache Eviction for Efficient Long-Context Inference
Mar 11, 2025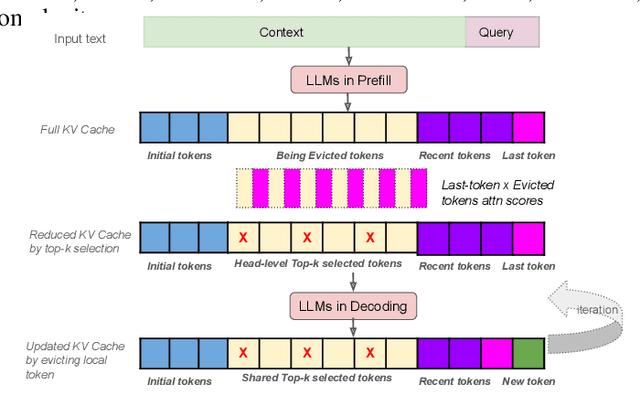
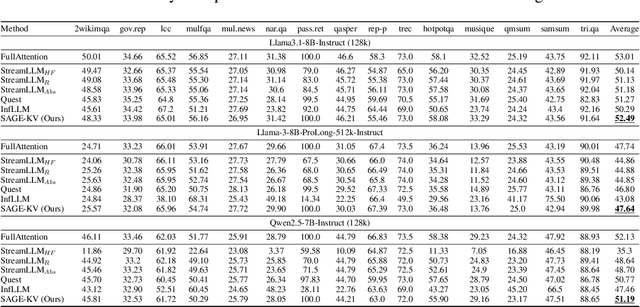
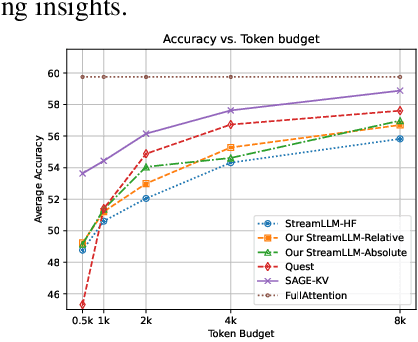
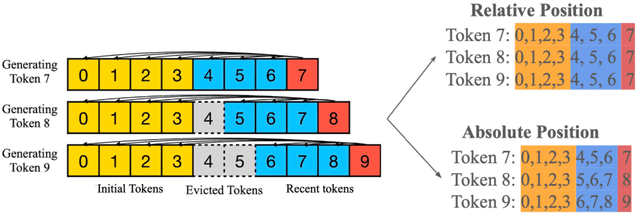
Efficient long-context inference is critical as large language models (LLMs) adopt context windows of ranging from 128K to 1M tokens. However, the growing key-value (KV) cache and the high computational complexity of attention create significant bottlenecks in memory usage and latency. In this paper, we find that attention in diverse long-context tasks exhibits sparsity, and LLMs implicitly "know" which tokens can be dropped or evicted at the head level after the pre-filling stage. Based on this insight, we propose Self-Attention Guided Eviction~(SAGE-KV), a simple and effective KV eviction cache method for long-context inference. After prefilling, our method performs a one-time top-k selection at both the token and head levels to compress the KV cache, enabling efficient inference with the reduced cache. Evaluations on LongBench and three long-context LLMs (Llama3.1-8B-Instruct-128k, Llama3-8B-Prolong-512k-Instruct, and Qwen2.5-7B-Instruct-128k) show that SAGE-KV maintains accuracy comparable to full attention while significantly improving efficiency. Specifically, SAGE-KV achieves 4x higher memory efficiency with improved accuracy over the static KV cache selection method StreamLLM, and 2x higher memory efficiency with better accuracy than the dynamic KV cache selection method Quest.
Training Domain Draft Models for Speculative Decoding: Best Practices and Insights
Mar 10, 2025Speculative decoding is an effective method for accelerating inference of large language models (LLMs) by employing a small draft model to predict the output of a target model. However, when adapting speculative decoding to domain-specific target models, the acceptance rate of the generic draft model drops significantly due to domain shift. In this work, we systematically investigate knowledge distillation techniques for training domain draft models to improve their speculation accuracy. We compare white-box and black-box distillation approaches and explore their effectiveness in various data accessibility scenarios, including historical user queries, curated domain data, and synthetically generated alignment data. Our experiments across Function Calling, Biology, and Chinese domains show that offline distillation consistently outperforms online distillation by 11% to 25%, white-box distillation surpasses black-box distillation by 2% to 10%, and data scaling trends hold across domains. Additionally, we find that synthetic data can effectively align draft models and achieve 80% to 93% of the performance of training on historical user queries. These findings provide practical guidelines for training domain-specific draft models to improve speculative decoding efficiency.
SubgoalXL: Subgoal-based Expert Learning for Theorem Proving
Aug 20, 2024



Formal theorem proving, a field at the intersection of mathematics and computer science, has seen renewed interest with advancements in large language models (LLMs). This paper introduces SubgoalXL, a novel approach that synergizes subgoal-based proofs with expert learning to enhance LLMs' capabilities in formal theorem proving within the Isabelle environment. SubgoalXL addresses two critical challenges: the scarcity of specialized mathematics and theorem-proving data, and the need for improved multi-step reasoning abilities in LLMs. By optimizing data efficiency and employing subgoal-level supervision, SubgoalXL extracts richer information from limited human-generated proofs. The framework integrates subgoal-oriented proof strategies with an expert learning system, iteratively refining formal statement, proof, and subgoal generators. Leveraging the Isabelle environment's advantages in subgoal-based proofs, SubgoalXL achieves a new state-of-the-art performance of 56.1\% in Isabelle on the standard miniF2F dataset, marking an absolute improvement of 4.9\%. Notably, SubgoalXL successfully solves 41 AMC12, 9 AIME, and 3 IMO problems from miniF2F. These results underscore the effectiveness of maximizing limited data utility and employing targeted guidance for complex reasoning in formal theorem proving, contributing to the ongoing advancement of AI reasoning capabilities. The implementation is available at \url{https://github.com/zhaoxlpku/SubgoalXL}.
SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts
May 13, 2024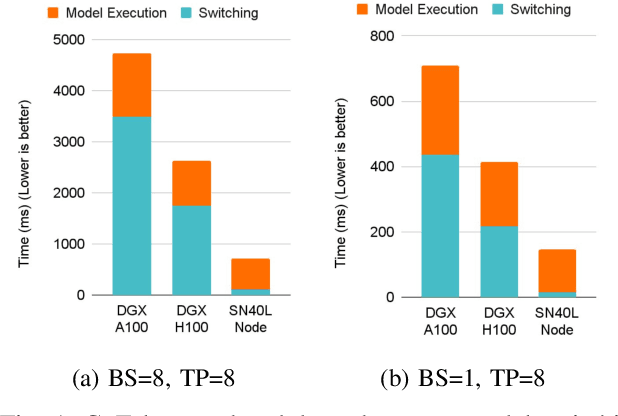
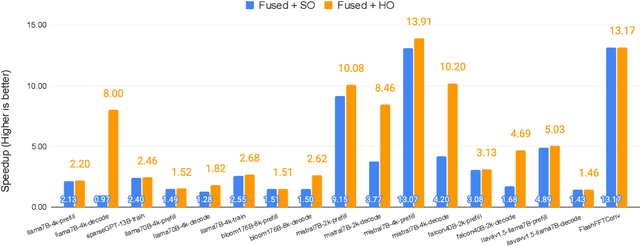
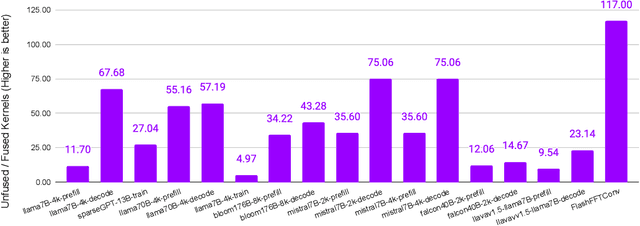
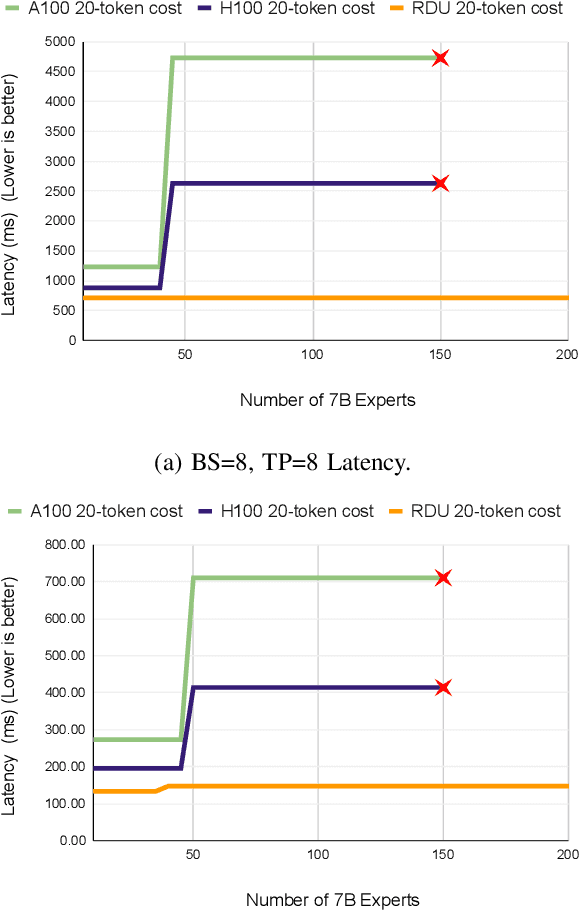
Monolithic large language models (LLMs) like GPT-4 have paved the way for modern generative AI applications. Training, serving, and maintaining monolithic LLMs at scale, however, remains prohibitively expensive and challenging. The disproportionate increase in compute-to-memory ratio of modern AI accelerators have created a memory wall, necessitating new methods to deploy AI. Composition of Experts (CoE) is an alternative modular approach that lowers the cost and complexity of training and serving. However, this approach presents two key challenges when using conventional hardware: (1) without fused operations, smaller models have lower operational intensity, which makes high utilization more challenging to achieve; and (2) hosting a large number of models can be either prohibitively expensive or slow when dynamically switching between them. In this paper, we describe how combining CoE, streaming dataflow, and a three-tier memory system scales the AI memory wall. We describe Samba-CoE, a CoE system with 150 experts and a trillion total parameters. We deploy Samba-CoE on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU) - a commercial dataflow accelerator architecture that has been co-designed for enterprise inference and training applications. The chip introduces a new three-tier memory system with on-chip distributed SRAM, on-package HBM, and off-package DDR DRAM. A dedicated inter-RDU network enables scaling up and out over multiple sockets. We demonstrate speedups ranging from 2x to 13x on various benchmarks running on eight RDU sockets compared with an unfused baseline. We show that for CoE inference deployments, the 8-socket RDU Node reduces machine footprint by up to 19x, speeds up model switching time by 15x to 31x, and achieves an overall speedup of 3.7x over a DGX H100 and 6.6x over a DGX A100.
SambaLingo: Teaching Large Language Models New Languages
Apr 08, 2024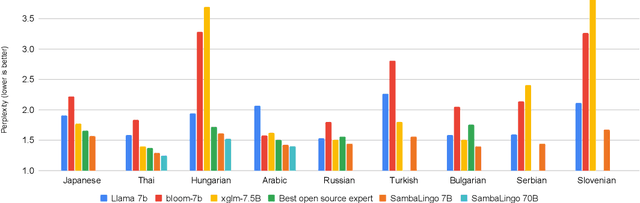
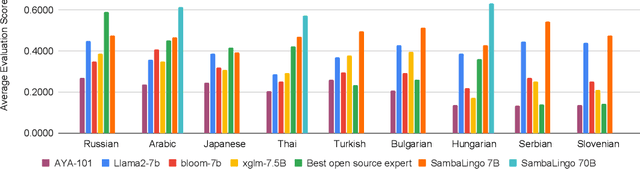

Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
Efficiently Adapting Pretrained Language Models To New Languages
Nov 09, 2023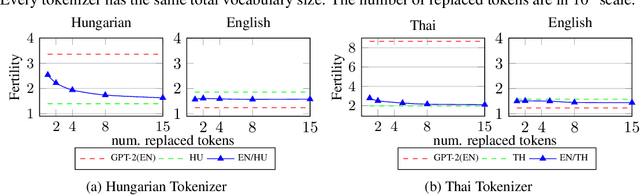
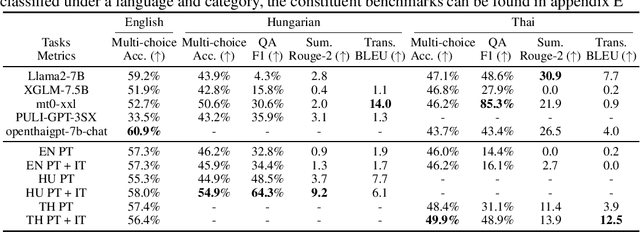
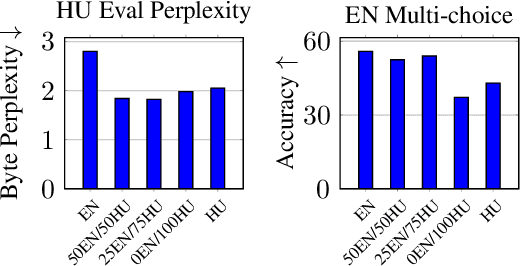
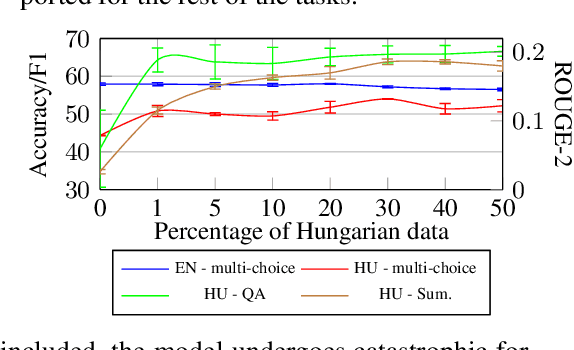
Recent large language models (LLM) exhibit sub-optimal performance on low-resource languages, as the training data of these models is usually dominated by English and other high-resource languages. Furthermore, it is challenging to train models for low-resource languages, especially from scratch, due to a lack of high quality training data. Adapting pretrained LLMs reduces the need for data in the new language while also providing cross lingual transfer capabilities. However, naively adapting to new languages leads to catastrophic forgetting and poor tokenizer efficiency. In this work, we study how to efficiently adapt any existing pretrained LLM to a new language without running into these issues. In particular, we improve the encoding efficiency of the tokenizer by adding new tokens from the target language and study the data mixing recipe to mitigate forgetting. Our experiments on adapting an English LLM to Hungarian and Thai show that our recipe can reach better performance than open source models on the target language, with minimal regressions on English.
Training Large Language Models Efficiently with Sparsity and Dataflow
Apr 11, 2023Large foundation language models have shown their versatility in being able to be adapted to perform a wide variety of downstream tasks, such as text generation, sentiment analysis, semantic search etc. However, training such large foundational models is a non-trivial exercise that requires a significant amount of compute power and expertise from machine learning and systems experts. As models get larger, these demands are only increasing. Sparsity is a promising technique to relieve the compute requirements for training. However, sparsity introduces new challenges in training the sparse model to the same quality as the dense counterparts. Furthermore, sparsity drops the operation intensity and introduces irregular memory access patterns that makes it challenging to efficiently utilize compute resources. This paper demonstrates an end-to-end training flow on a large language model - 13 billion GPT - using sparsity and dataflow. The dataflow execution model and architecture enables efficient on-chip irregular memory accesses as well as native kernel fusion and pipelined parallelism that helps recover device utilization. We show that we can successfully train GPT 13B to the same quality as the dense GPT 13B model, while achieving an end-end speedup of 4.5x over dense A100 baseline.