 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed LLMs and Multimodal Large Language Models: A Survey on Advances, Challenges, and Future Directions
Mar 20, 2025Language models (LMs) are machine learning models designed to predict linguistic patterns by estimating the probability of word sequences based on large-scale datasets, such as text. LMs have a wide range of applications in natural language processing (NLP) tasks, including autocomplete and machine translation. Although larger datasets typically enhance LM performance, scalability remains a challenge due to constraints in computational power and resources. Distributed computing strategies offer essential solutions for improving scalability and managing the growing computational demand. Further, the use of sensitive datasets in training and deployment raises significant privacy concerns. Recent research has focused on developing decentralized techniques to enable distributed training and inference while utilizing diverse computational resources and enabling edge AI. This paper presents a survey on distributed solutions for various LMs, including large language models (LLMs), vision language models (VLMs), multimodal LLMs (MLLMs), and small language models (SLMs). While LLMs focus on processing and generating text, MLLMs are designed to handle multiple modalities of data (e.g., text, images, and audio) and to integrate them for broader applications. To this end, this paper reviews key advancements across the MLLM pipeline, including distributed training, inference, fine-tuning, and deployment, while also identifying the contributions, limitations, and future areas of improvement. Further, it categorizes the literature based on six primary focus areas of decentralization. Our analysis describes gaps in current methodologies for enabling distributed solutions for LMs and outline future research directions, emphasizing the need for novel solutions to enhance the robustness and applicability of distributed LMs.
Bangla Natural Language Processing: A Comprehensive Review of Classical, Machine Learning, and Deep Learning Based Methods
Jun 08, 2021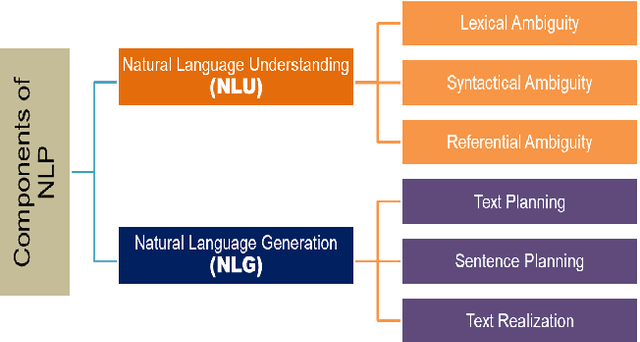

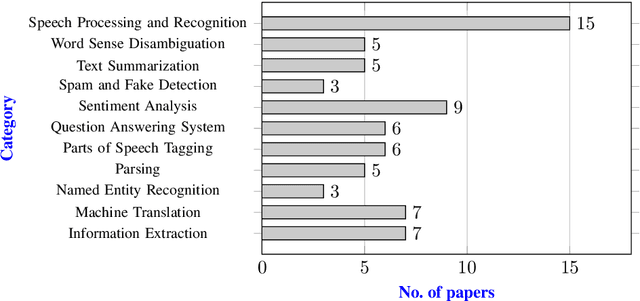
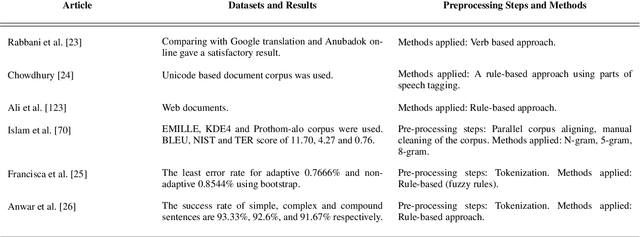
The Bangla language is the seventh most spoken language, with 265 million native and non-native speakers worldwide. However, English is the predominant language for online resources and technical knowledge, journals, and documentation. Consequently, many Bangla-speaking people, who have limited command of English, face hurdles to utilize English resources. To bridge the gap between limited support and increasing demand, researchers conducted many experiments and developed valuable tools and techniques to create and process Bangla language materials. Many efforts are also ongoing to make it easy to use the Bangla language in the online and technical domains. There are some review papers to understand the past, previous, and future Bangla Natural Language Processing (BNLP) trends. The studies are mainly concentrated on the specific domains of BNLP, such as sentiment analysis, speech recognition, optical character recognition, and text summarization. There is an apparent scarcity of resources that contain a comprehensive study of the recent BNLP tools and methods. Therefore, in this paper, we present a thorough review of 71 BNLP research papers and categorize them into 11 categories, namely Information Extraction, Machine Translation, Named Entity Recognition, Parsing, Parts of Speech Tagging, Question Answering System, Sentiment Analysis, Spam and Fake Detection, Text Summarization, Word Sense Disambiguation, and Speech Processing and Recognition. We study articles published between 1999 to 2021, and 50% of the papers were published after 2015. We discuss Classical, Machine Learning and Deep Learning approaches with different datasets while addressing the limitations and current and future trends of the BNLP.
Recent Advances in Deep Learning Techniques for Face Recognition
Mar 18, 2021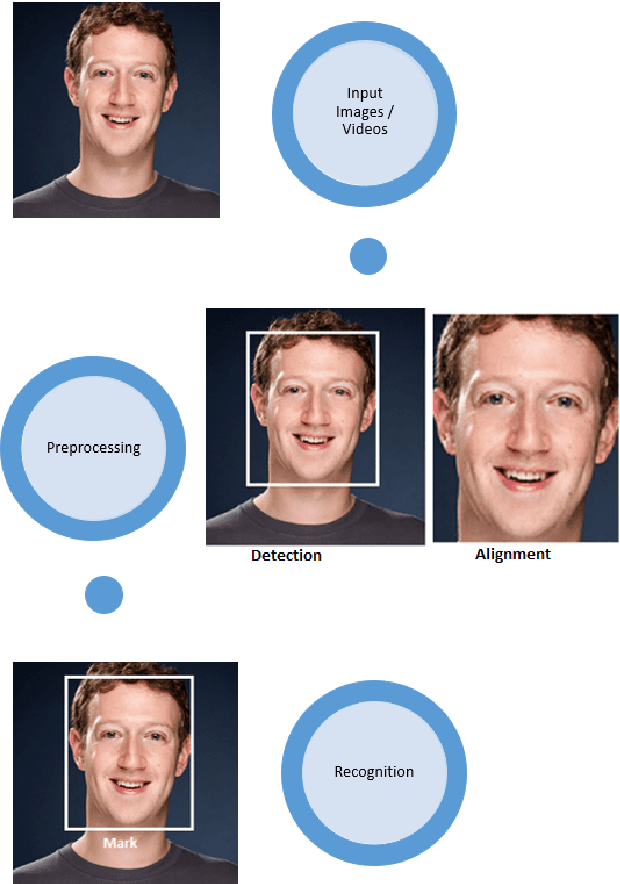
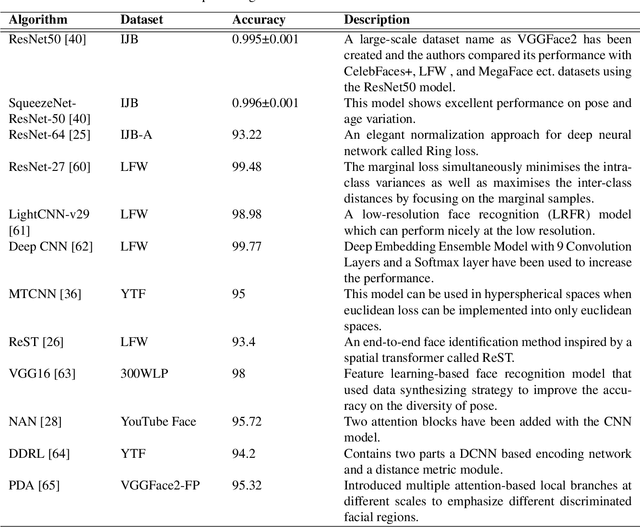
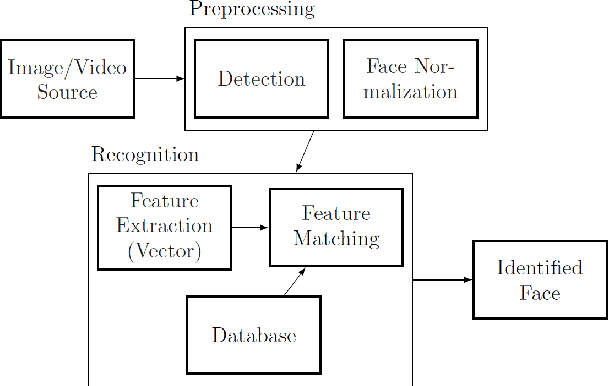

In recent years, researchers have proposed many deep learning (DL) methods for various tasks, and particularly face recognition (FR) made an enormous leap using these techniques. Deep FR systems benefit from the hierarchical architecture of the DL methods to learn discriminative face representation. Therefore, DL techniques significantly improve state-of-the-art performance on FR systems and encourage diverse and efficient real-world applications. In this paper, we present a comprehensive analysis of various FR systems that leverage the different types of DL techniques, and for the study, we summarize 168 recent contributions from this area. We discuss the papers related to different algorithms, architectures, loss functions, activation functions, datasets, challenges, improvement ideas, current and future trends of DL-based FR systems. We provide a detailed discussion of various DL methods to understand the current state-of-the-art, and then we discuss various activation and loss functions for the methods. Additionally, we summarize different datasets used widely for FR tasks and discuss challenges related to illumination, expression, pose variations, and occlusion. Finally, we discuss improvement ideas, current and future trends of FR tasks.