 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinancial Fraud Detection Using Explainable AI and Stacking Ensemble Methods
May 15, 2025Traditional machine learning models often prioritize predictive accuracy, often at the expense of model transparency and interpretability. The lack of transparency makes it difficult for organizations to comply with regulatory requirements and gain stakeholders trust. In this research, we propose a fraud detection framework that combines a stacking ensemble of well-known gradient boosting models: XGBoost, LightGBM, and CatBoost. In addition, explainable artificial intelligence (XAI) techniques are used to enhance the transparency and interpretability of the model's decisions. We used SHAP (SHapley Additive Explanations) for feature selection to identify the most important features. Further efforts were made to explain the model's predictions using Local Interpretable Model-Agnostic Explanation (LIME), Partial Dependence Plots (PDP), and Permutation Feature Importance (PFI). The IEEE-CIS Fraud Detection dataset, which includes more than 590,000 real transaction records, was used to evaluate the proposed model. The model achieved a high performance with an accuracy of 99% and an AUC-ROC score of 0.99, outperforming several recent related approaches. These results indicate that combining high prediction accuracy with transparent interpretability is possible and could lead to a more ethical and trustworthy solution in financial fraud detection.
Heterogeneous virus classification using a functional deep learning model based on transmission electron microscopy images (Preprint)
May 24, 2024Viruses are submicroscopic agents that can infect all kinds of lifeforms and use their hosts' living cells to replicate themselves. Despite having some of the simplest genetic structures among all living beings, viruses are highly adaptable, resilient, and given the right conditions, are capable of causing unforeseen complications in their hosts' bodies. Due to their multiple transmission pathways, high contagion rate, and lethality, viruses are the biggest biological threat faced by animal and plant species. It is often challenging to promptly detect the presence of a virus in a possible host's body and accurately determine its type using manual examination techniques; however, it can be done using computer-based automatic diagnosis methods. Most notably, the analysis of Transmission Electron Microscopy (TEM) images has been proven to be quite successful in instant virus identification. Using TEM images collected from a recently published dataset, this article proposes a deep learning-based classification model to identify the type of virus within those images correctly. The methodology of this study includes two coherent image processing techniques to reduce the noise present in the raw microscopy images. Experimental results show that it can differentiate among the 14 types of viruses present in the dataset with a maximum of 97.44% classification accuracy and F1-score, which asserts the effectiveness and reliability of the proposed method. Implementing this scheme will impart a fast and dependable way of virus identification subsidiary to the thorough diagnostic procedures.
Bangla Natural Language Processing: A Comprehensive Review of Classical, Machine Learning, and Deep Learning Based Methods
Jun 08, 2021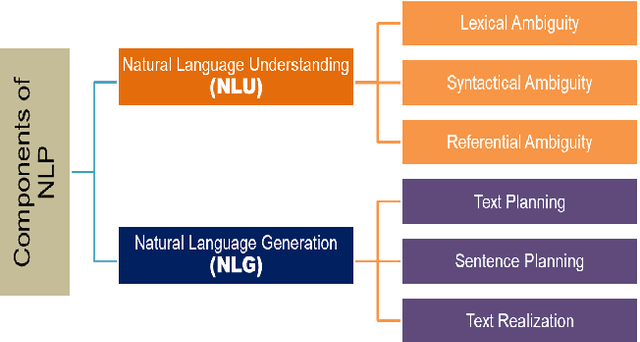

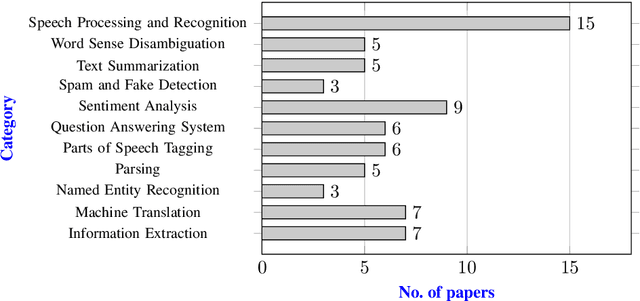
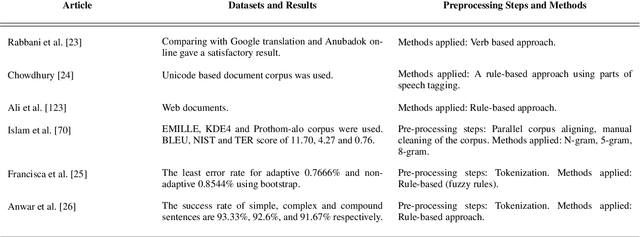
The Bangla language is the seventh most spoken language, with 265 million native and non-native speakers worldwide. However, English is the predominant language for online resources and technical knowledge, journals, and documentation. Consequently, many Bangla-speaking people, who have limited command of English, face hurdles to utilize English resources. To bridge the gap between limited support and increasing demand, researchers conducted many experiments and developed valuable tools and techniques to create and process Bangla language materials. Many efforts are also ongoing to make it easy to use the Bangla language in the online and technical domains. There are some review papers to understand the past, previous, and future Bangla Natural Language Processing (BNLP) trends. The studies are mainly concentrated on the specific domains of BNLP, such as sentiment analysis, speech recognition, optical character recognition, and text summarization. There is an apparent scarcity of resources that contain a comprehensive study of the recent BNLP tools and methods. Therefore, in this paper, we present a thorough review of 71 BNLP research papers and categorize them into 11 categories, namely Information Extraction, Machine Translation, Named Entity Recognition, Parsing, Parts of Speech Tagging, Question Answering System, Sentiment Analysis, Spam and Fake Detection, Text Summarization, Word Sense Disambiguation, and Speech Processing and Recognition. We study articles published between 1999 to 2021, and 50% of the papers were published after 2015. We discuss Classical, Machine Learning and Deep Learning approaches with different datasets while addressing the limitations and current and future trends of the BNLP.