 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Metamorphic Testing Perspective on Knowledge Distillation for Language Models of Code: Does the Student Deeply Mimic the Teacher?
Nov 07, 2025
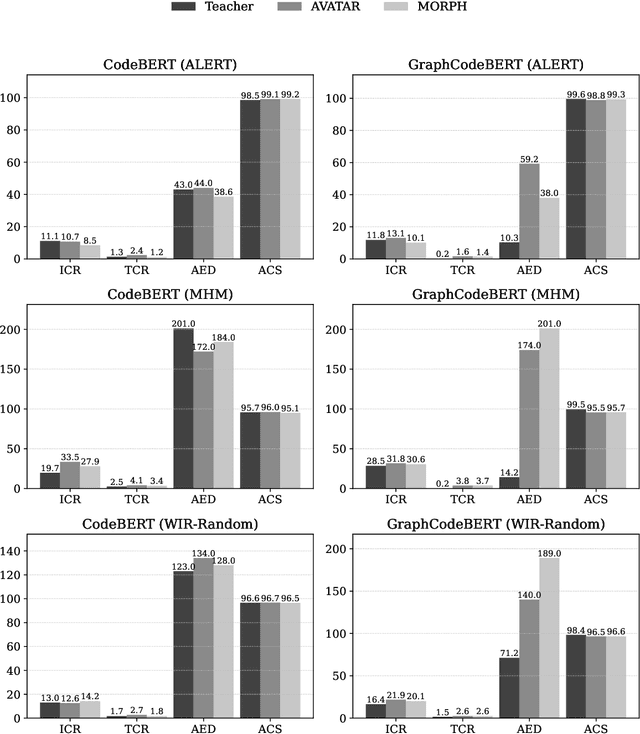
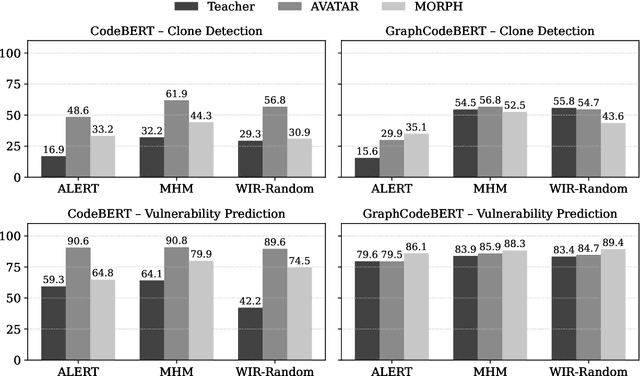

Transformer-based language models of code have achieved state-of-the-art performance across a wide range of software analytics tasks, but their practical deployment remains limited due to high computational costs, slow inference speeds, and significant environmental impact. To address these challenges, recent research has increasingly explored knowledge distillation as a method for compressing a large language model of code (the teacher) into a smaller model (the student) while maintaining performance. However, the degree to which a student model deeply mimics the predictive behavior and internal representations of its teacher remains largely unexplored, as current accuracy-based evaluation provides only a surface-level view of model quality and often fails to capture more profound discrepancies in behavioral fidelity between the teacher and student models. To address this gap, we empirically show that the student model often fails to deeply mimic the teacher model, resulting in up to 285% greater performance drop under adversarial attacks, which is not captured by traditional accuracy-based evaluation. Therefore, we propose MetaCompress, a metamorphic testing framework that systematically evaluates behavioral fidelity by comparing the outputs of teacher and student models under a set of behavior-preserving metamorphic relations. We evaluate MetaCompress on two widely studied tasks, using compressed versions of popular language models of code, obtained via three different knowledge distillation techniques: Compressor, AVATAR, and MORPH. The results show that MetaCompress identifies up to 62% behavioral discrepancies in student models, underscoring the need for behavioral fidelity evaluation within the knowledge distillation pipeline and establishing MetaCompress as a practical framework for testing compressed language models of code derived through knowledge distillation.
Bangla Natural Language Processing: A Comprehensive Review of Classical, Machine Learning, and Deep Learning Based Methods
Jun 08, 2021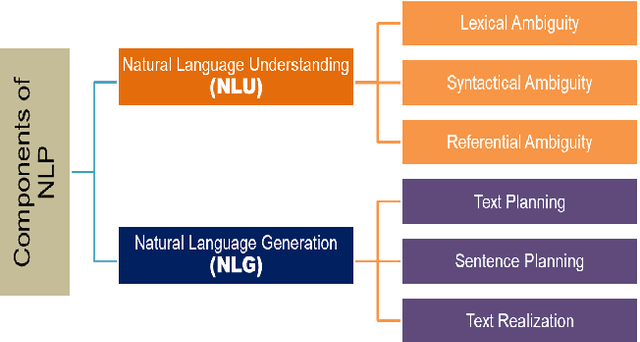

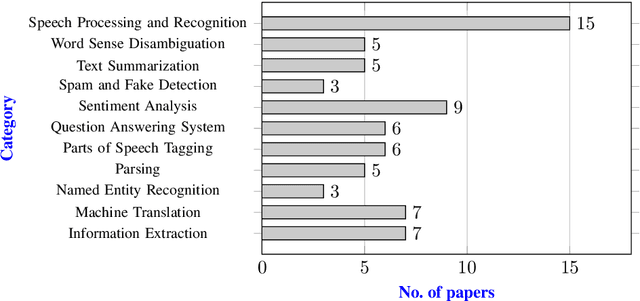
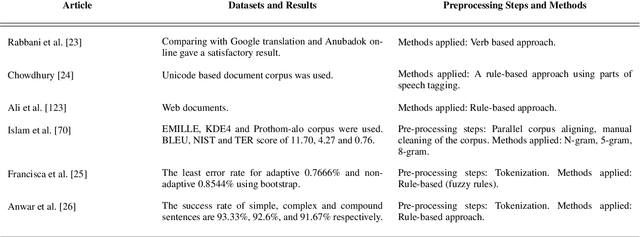
The Bangla language is the seventh most spoken language, with 265 million native and non-native speakers worldwide. However, English is the predominant language for online resources and technical knowledge, journals, and documentation. Consequently, many Bangla-speaking people, who have limited command of English, face hurdles to utilize English resources. To bridge the gap between limited support and increasing demand, researchers conducted many experiments and developed valuable tools and techniques to create and process Bangla language materials. Many efforts are also ongoing to make it easy to use the Bangla language in the online and technical domains. There are some review papers to understand the past, previous, and future Bangla Natural Language Processing (BNLP) trends. The studies are mainly concentrated on the specific domains of BNLP, such as sentiment analysis, speech recognition, optical character recognition, and text summarization. There is an apparent scarcity of resources that contain a comprehensive study of the recent BNLP tools and methods. Therefore, in this paper, we present a thorough review of 71 BNLP research papers and categorize them into 11 categories, namely Information Extraction, Machine Translation, Named Entity Recognition, Parsing, Parts of Speech Tagging, Question Answering System, Sentiment Analysis, Spam and Fake Detection, Text Summarization, Word Sense Disambiguation, and Speech Processing and Recognition. We study articles published between 1999 to 2021, and 50% of the papers were published after 2015. We discuss Classical, Machine Learning and Deep Learning approaches with different datasets while addressing the limitations and current and future trends of the BNLP.
Acute Lymphoblastic Leukemia Detection from Microscopic Images Using Weighted Ensemble of Convolutional Neural Networks
May 09, 2021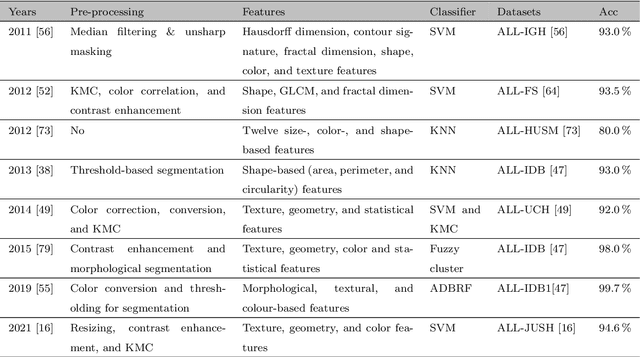
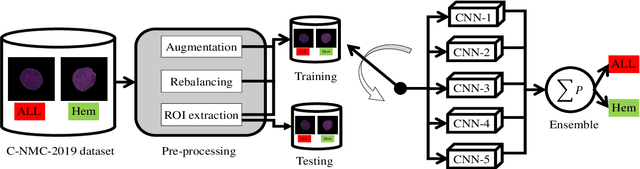
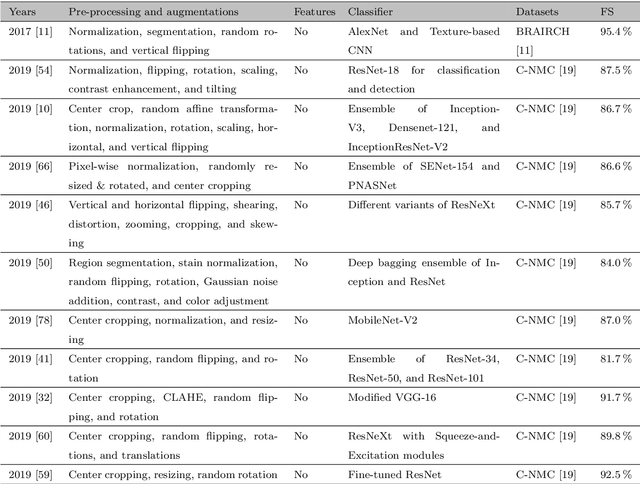
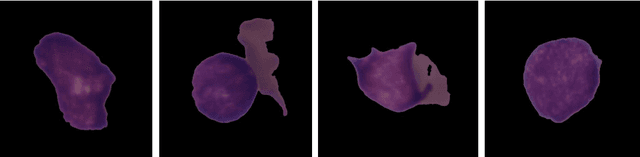
Acute Lymphoblastic Leukemia (ALL) is a blood cell cancer characterized by numerous immature lymphocytes. Even though automation in ALL prognosis is an essential aspect of cancer diagnosis, it is challenging due to the morphological correlation between malignant and normal cells. The traditional ALL classification strategy demands experienced pathologists to carefully read the cell images, which is arduous, time-consuming, and often suffers inter-observer variations. This article has automated the ALL detection task from microscopic cell images, employing deep Convolutional Neural Networks (CNNs). We explore the weighted ensemble of different deep CNNs to recommend a better ALL cell classifier. The weights for the ensemble candidate models are estimated from their corresponding metrics, such as accuracy, F1-score, AUC, and kappa values. Various data augmentations and pre-processing are incorporated for achieving a better generalization of the network. We utilize the publicly available C-NMC-2019 ALL dataset to conduct all the comprehensive experiments. Our proposed weighted ensemble model, using the kappa values of the ensemble candidates as their weights, has outputted a weighted F1-score of 88.6 %, a balanced accuracy of 86.2 %, and an AUC of 0.941 in the preliminary test set. The qualitative results displaying the gradient class activation maps confirm that the introduced model has a concentrated learned region. In contrast, the ensemble candidate models, such as Xception, VGG-16, DenseNet-121, MobileNet, and InceptionResNet-V2, separately produce coarse and scatter learned areas for most example cases. Since the proposed kappa value-based weighted ensemble yields a better result for the aimed task in this article, it can experiment in other domains of medical diagnostic applications.
Human Activity Analysis and Recognition from Smartphones using Machine Learning Techniques
Mar 30, 2021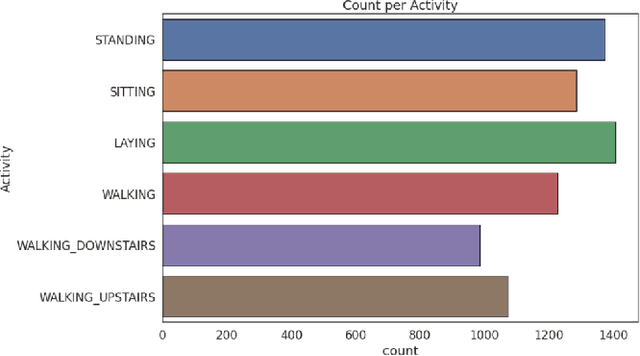
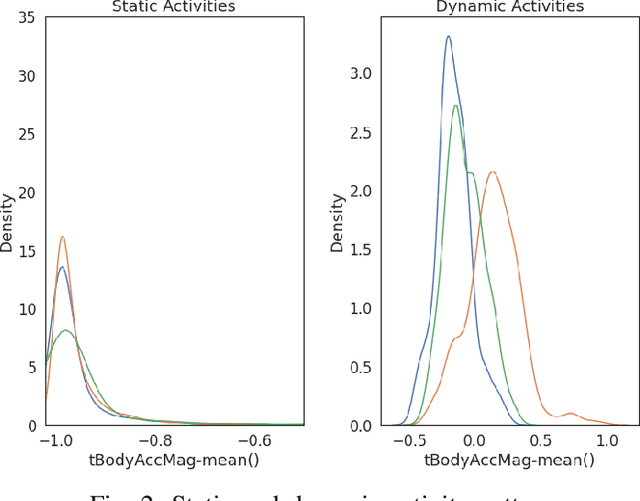
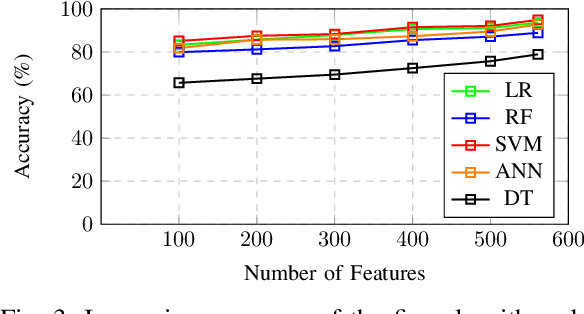
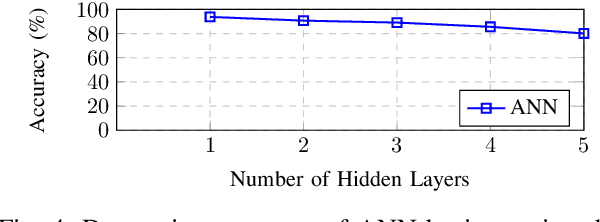
Human Activity Recognition (HAR) is considered a valuable research topic in the last few decades. Different types of machine learning models are used for this purpose, and this is a part of analyzing human behavior through machines. It is not a trivial task to analyze the data from wearable sensors for complex and high dimensions. Nowadays, researchers mostly use smartphones or smart home sensors to capture these data. In our paper, we analyze these data using machine learning models to recognize human activities, which are now widely used for many purposes such as physical and mental health monitoring. We apply different machine learning models and compare performances. We use Logistic Regression (LR) as the benchmark model for its simplicity and excellent performance on a dataset, and to compare, we take Decision Tree (DT), Support Vector Machine (SVM), Random Forest (RF), and Artificial Neural Network (ANN). Additionally, we select the best set of parameters for each model by grid search. We use the HAR dataset from the UCI Machine Learning Repository as a standard dataset to train and test the models. Throughout the analysis, we can see that the Support Vector Machine performed (average accuracy 96.33%) far better than the other methods. We also prove that the results are statistically significant by employing statistical significance test methods.