 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed LLMs and Multimodal Large Language Models: A Survey on Advances, Challenges, and Future Directions
Mar 20, 2025Language models (LMs) are machine learning models designed to predict linguistic patterns by estimating the probability of word sequences based on large-scale datasets, such as text. LMs have a wide range of applications in natural language processing (NLP) tasks, including autocomplete and machine translation. Although larger datasets typically enhance LM performance, scalability remains a challenge due to constraints in computational power and resources. Distributed computing strategies offer essential solutions for improving scalability and managing the growing computational demand. Further, the use of sensitive datasets in training and deployment raises significant privacy concerns. Recent research has focused on developing decentralized techniques to enable distributed training and inference while utilizing diverse computational resources and enabling edge AI. This paper presents a survey on distributed solutions for various LMs, including large language models (LLMs), vision language models (VLMs), multimodal LLMs (MLLMs), and small language models (SLMs). While LLMs focus on processing and generating text, MLLMs are designed to handle multiple modalities of data (e.g., text, images, and audio) and to integrate them for broader applications. To this end, this paper reviews key advancements across the MLLM pipeline, including distributed training, inference, fine-tuning, and deployment, while also identifying the contributions, limitations, and future areas of improvement. Further, it categorizes the literature based on six primary focus areas of decentralization. Our analysis describes gaps in current methodologies for enabling distributed solutions for LMs and outline future research directions, emphasizing the need for novel solutions to enhance the robustness and applicability of distributed LMs.
Exploring Audio Editing Features as User-Centric Privacy Defenses Against Emotion Inference Attacks
Jan 30, 2025



The rapid proliferation of speech-enabled technologies, including virtual assistants, video conferencing platforms, and wearable devices, has raised significant privacy concerns, particularly regarding the inference of sensitive emotional information from audio data. Existing privacy-preserving methods often compromise usability and security, limiting their adoption in practical scenarios. This paper introduces a novel, user-centric approach that leverages familiar audio editing techniques, specifically pitch and tempo manipulation, to protect emotional privacy without sacrificing usability. By analyzing popular audio editing applications on Android and iOS platforms, we identified these features as both widely available and usable. We rigorously evaluated their effectiveness against a threat model, considering adversarial attacks from diverse sources, including Deep Neural Networks (DNNs), Large Language Models (LLMs), and and reversibility testing. Our experiments, conducted on three distinct datasets, demonstrate that pitch and tempo manipulation effectively obfuscates emotional data. Additionally, we explore the design principles for lightweight, on-device implementation to ensure broad applicability across various devices and platforms.
Blockchain-Empowered Cyber-Secure Federated Learning for Trustworthy Edge Computing
Dec 30, 2024



Federated Learning (FL) is a privacy-preserving distributed machine learning scheme, where each participant data remains on the participating devices and only the local model generated utilizing the local computational power is transmitted throughout the database. However, the distributed computational nature of FL creates the necessity to develop a mechanism that can remotely trigger any network agents, track their activities, and prevent threats to the overall process posed by malicious participants. Particularly, the FL paradigm may become vulnerable due to an active attack from the network participants, called a poisonous attack. In such an attack, the malicious participant acts as a benign agent capable of affecting the global model quality by uploading an obfuscated poisoned local model update to the server. This paper presents a cross-device FL model that ensures trustworthiness, fairness, and authenticity in the underlying FL training process. We leverage trustworthiness by constructing a reputation-based trust model based on contributions of agents toward model convergence. We ensure fairness by identifying and removing malicious agents from the training process through an outlier detection technique. Further, we establish authenticity by generating a token for each participating device through a distributed sensing mechanism and storing that unique token in a blockchain smart contract. Further, we insert the trust scores of all agents into a blockchain and validate their reputations using various consensus mechanisms that consider the computational task.
Securing Vision-Language Models with a Robust Encoder Against Jailbreak and Adversarial Attacks
Sep 11, 2024



Large Vision-Language Models (LVLMs), trained on multimodal big datasets, have significantly advanced AI by excelling in vision-language tasks. However, these models remain vulnerable to adversarial attacks, particularly jailbreak attacks, which bypass safety protocols and cause the model to generate misleading or harmful responses. This vulnerability stems from both the inherent susceptibilities of LLMs and the expanded attack surface introduced by the visual modality. We propose Sim-CLIP+, a novel defense mechanism that adversarially fine-tunes the CLIP vision encoder by leveraging a Siamese architecture. This approach maximizes cosine similarity between perturbed and clean samples, facilitating resilience against adversarial manipulations. Sim-CLIP+ offers a plug-and-play solution, allowing seamless integration into existing LVLM architectures as a robust vision encoder. Unlike previous defenses, our method requires no structural modifications to the LVLM and incurs minimal computational overhead. Sim-CLIP+ demonstrates effectiveness against both gradient-based adversarial attacks and various jailbreak techniques. We evaluate Sim-CLIP+ against three distinct jailbreak attack strategies and perform clean evaluations using standard downstream datasets, including COCO for image captioning and OKVQA for visual question answering. Extensive experiments demonstrate that Sim-CLIP+ maintains high clean accuracy while substantially improving robustness against both gradient-based adversarial attacks and jailbreak techniques. Our code and robust vision encoders are available at https://github.com/speedlab-git/Robust-Encoder-against-Jailbreak-attack.git.
TriplePlay: Enhancing Federated Learning with CLIP for Non-IID Data and Resource Efficiency
Sep 09, 2024



The rapid advancement and increasing complexity of pretrained models, exemplified by CLIP, offer significant opportunities as well as challenges for Federated Learning (FL), a critical component of privacy-preserving artificial intelligence. This research delves into the intricacies of integrating large foundation models like CLIP within FL frameworks to enhance privacy, efficiency, and adaptability across heterogeneous data landscapes. It specifically addresses the challenges posed by non-IID data distributions, the computational and communication overheads of leveraging such complex models, and the skewed representation of classes within datasets. We propose TriplePlay, a framework that integrates CLIP as an adapter to enhance FL's adaptability and performance across diverse data distributions. This approach addresses the long-tail distribution challenge to ensure fairness while reducing resource demands through quantization and low-rank adaptation techniques.Our simulation results demonstrate that TriplePlay effectively decreases GPU usage costs and speeds up the learning process, achieving convergence with reduced communication overhead.
Sim-CLIP: Unsupervised Siamese Adversarial Fine-Tuning for Robust and Semantically-Rich Vision-Language Models
Jul 20, 2024



Vision-language models (VLMs) have achieved significant strides in recent times specially in multimodal tasks, yet they remain susceptible to adversarial attacks on their vision components. To address this, we propose Sim-CLIP, an unsupervised adversarial fine-tuning method that enhances the robustness of the widely-used CLIP vision encoder against such attacks while maintaining semantic richness and specificity. By employing a Siamese architecture with cosine similarity loss, Sim-CLIP learns semantically meaningful and attack-resilient visual representations without requiring large batch sizes or momentum encoders. Our results demonstrate that VLMs enhanced with Sim-CLIP's fine-tuned CLIP encoder exhibit significantly enhanced robustness against adversarial attacks, while preserving semantic meaning of the perturbed images. Notably, Sim-CLIP does not require additional training or fine-tuning of the VLM itself; replacing the original vision encoder with our fine-tuned Sim-CLIP suffices to provide robustness. This work underscores the significance of reinforcing foundational models like CLIP to safeguard the reliability of downstream VLM applications, paving the way for more secure and effective multimodal systems.
Towards Sustainable SecureML: Quantifying Carbon Footprint of Adversarial Machine Learning
Mar 27, 2024The widespread adoption of machine learning (ML) across various industries has raised sustainability concerns due to its substantial energy usage and carbon emissions. This issue becomes more pressing in adversarial ML, which focuses on enhancing model security against different network-based attacks. Implementing defenses in ML systems often necessitates additional computational resources and network security measures, exacerbating their environmental impacts. In this paper, we pioneer the first investigation into adversarial ML's carbon footprint, providing empirical evidence connecting greater model robustness to higher emissions. Addressing the critical need to quantify this trade-off, we introduce the Robustness Carbon Trade-off Index (RCTI). This novel metric, inspired by economic elasticity principles, captures the sensitivity of carbon emissions to changes in adversarial robustness. We demonstrate the RCTI through an experiment involving evasion attacks, analyzing the interplay between robustness against attacks, performance, and carbon emissions.
FedAVO: Improving Communication Efficiency in Federated Learning with African Vultures Optimizer
May 02, 2023



Federated Learning (FL), a distributed machine learning technique has recently experienced tremendous growth in popularity due to its emphasis on user data privacy. However, the distributed computations of FL can result in constrained communication and drawn-out learning processes, necessitating the client-server communication cost optimization. The ratio of chosen clients and the quantity of local training passes are two hyperparameters that have a significant impact on FL performance. Due to different training preferences across various applications, it can be difficult for FL practitioners to manually select such hyperparameters. In our research paper, we introduce FedAVO, a novel FL algorithm that enhances communication effectiveness by selecting the best hyperparameters leveraging the African Vulture Optimizer (AVO). Our research demonstrates that the communication costs associated with FL operations can be substantially reduced by adopting AVO for FL hyperparameter adjustment. Through extensive evaluations of FedAVO on benchmark datasets, we show that FedAVO achieves significant improvement in terms of model accuracy and communication round, particularly with realistic cases of Non-IID datasets. Our extensive evaluation of the FedAVO algorithm identifies the optimal hyperparameters that are appropriately fitted for the benchmark datasets, eventually increasing global model accuracy by 6% in comparison to the state-of-the-art FL algorithms (such as FedAvg, FedProx, FedPSO, etc.).
A Survey on Secure and Private Federated Learning Using Blockchain: Theory and Application in Resource-constrained Computing
Mar 24, 2023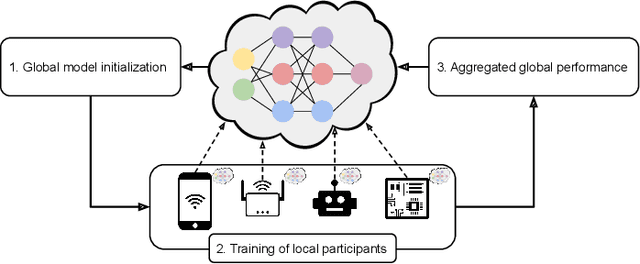
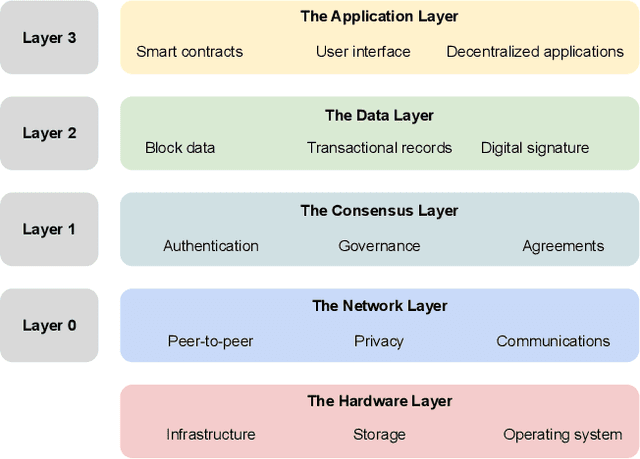
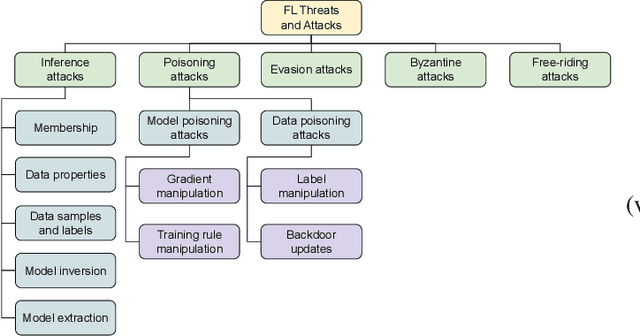
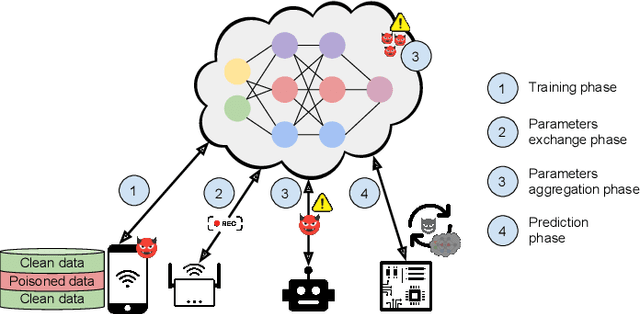
Federated Learning (FL) has gained widespread popularity in recent years due to the fast booming of advanced machine learning and artificial intelligence along with emerging security and privacy threats. FL enables efficient model generation from local data storage of the edge devices without revealing the sensitive data to any entities. While this paradigm partly mitigates the privacy issues of users' sensitive data, the performance of the FL process can be threatened and reached a bottleneck due to the growing cyber threats and privacy violation techniques. To expedite the proliferation of FL process, the integration of blockchain for FL environments has drawn prolific attention from the people of academia and industry. Blockchain has the potential to prevent security and privacy threats with its decentralization, immutability, consensus, and transparency characteristic. However, if the blockchain mechanism requires costly computational resources, then the resource-constrained FL clients cannot be involved in the training. Considering that, this survey focuses on reviewing the challenges, solutions, and future directions for the successful deployment of blockchain in resource-constrained FL environments. We comprehensively review variant blockchain mechanisms that are suitable for FL process and discuss their trade-offs for a limited resource budget. Further, we extensively analyze the cyber threats that could be observed in a resource-constrained FL environment, and how blockchain can play a key role to block those cyber attacks. To this end, we highlight some potential solutions towards the coupling of blockchain and federated learning that can offer high levels of reliability, data privacy, and distributed computing performance.
An enhanced method of initial cluster center selection for K-means algorithm
Oct 18, 2022
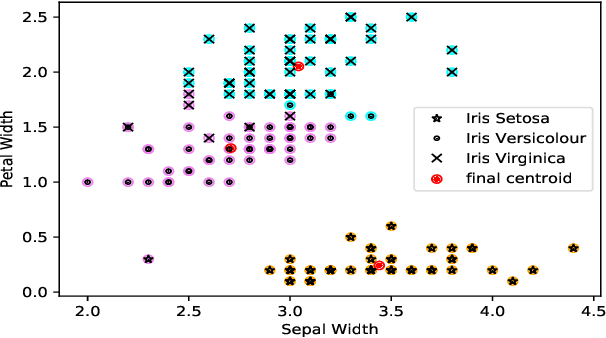
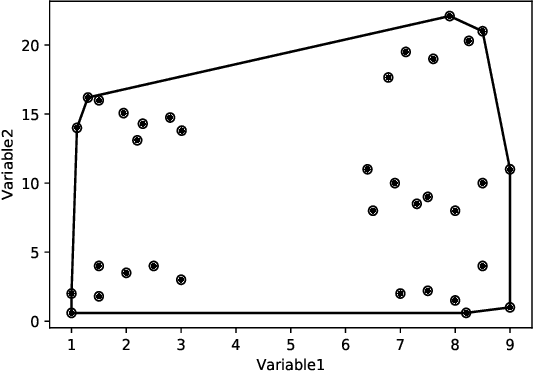
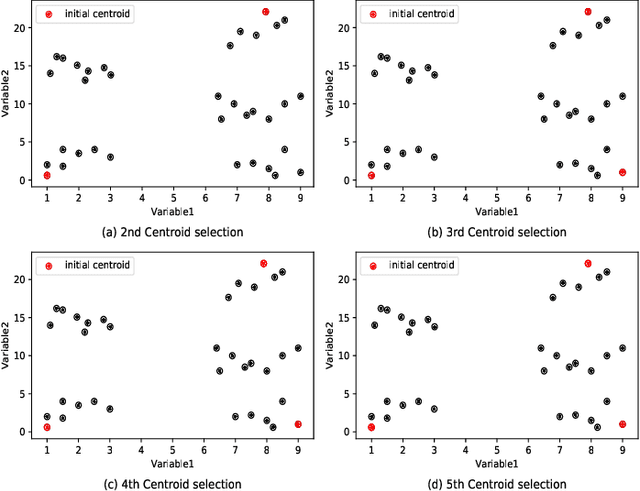
Clustering is one of the widely used techniques to find out patterns from a dataset that can be applied in different applications or analyses. K-means, the most popular and simple clustering algorithm, might get trapped into local minima if not properly initialized and the initialization of this algorithm is done randomly. In this paper, we propose a novel approach to improve initial cluster selection for K-means algorithm. This algorithm is based on the fact that the initial centroids must be well separated from each other since the final clusters are separated groups in feature space. The Convex Hull algorithm facilitates the computing of the first two centroids and the remaining ones are selected according to the distance from previously selected centers. To ensure the selection of one center per cluster, we use the nearest neighbor technique. To check the robustness of our proposed algorithm, we consider several real-world datasets. We obtained only 7.33%, 7.90%, and 0% clustering error in Iris, Letter, and Ruspini data respectively which proves better performance than other existing systems. The results indicate that our proposed method outperforms the conventional K means approach by accelerating the computation when the number of clusters is greater than 2.
* 6 pages