 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Anomalies in Blockchain Transactions using Machine Learning Classifiers and Explainability Analysis
Jan 07, 2024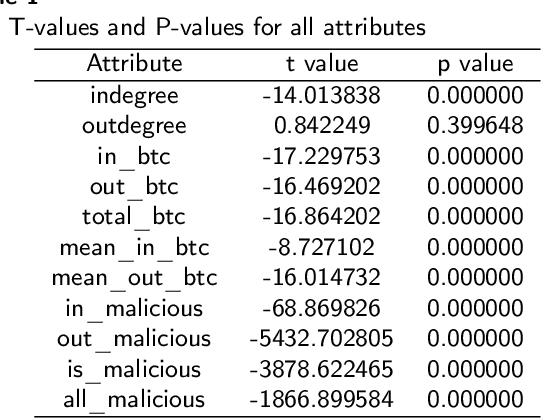
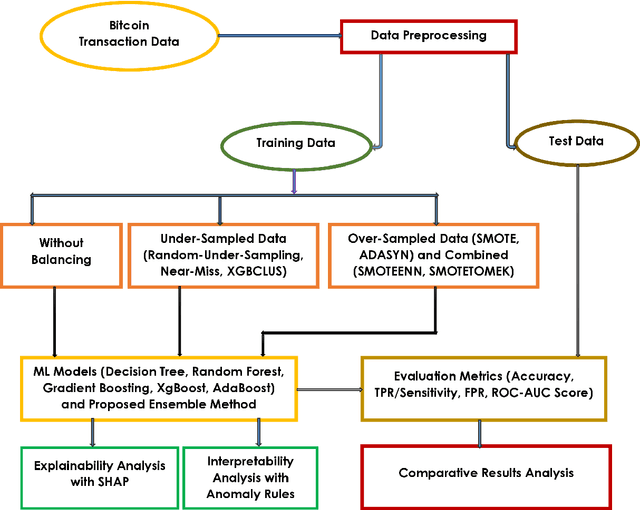

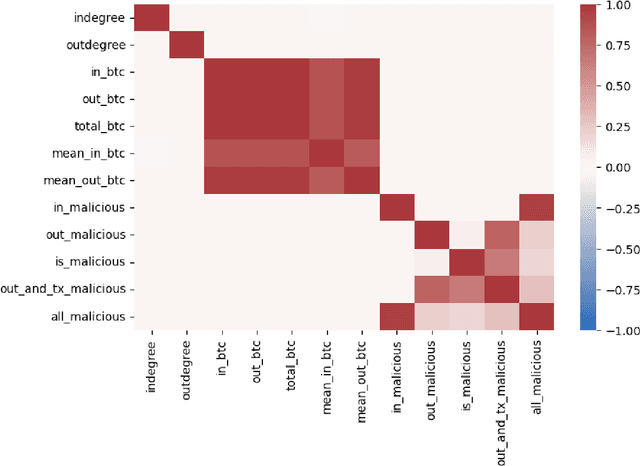
As the use of Blockchain for digital payments continues to rise in popularity, it also becomes susceptible to various malicious attacks. Successfully detecting anomalies within Blockchain transactions is essential for bolstering trust in digital payments. However, the task of anomaly detection in Blockchain transaction data is challenging due to the infrequent occurrence of illicit transactions. Although several studies have been conducted in the field, a limitation persists: the lack of explanations for the model's predictions. This study seeks to overcome this limitation by integrating eXplainable Artificial Intelligence (XAI) techniques and anomaly rules into tree-based ensemble classifiers for detecting anomalous Bitcoin transactions. The Shapley Additive exPlanation (SHAP) method is employed to measure the contribution of each feature, and it is compatible with ensemble models. Moreover, we present rules for interpreting whether a Bitcoin transaction is anomalous or not. Additionally, we have introduced an under-sampling algorithm named XGBCLUS, designed to balance anomalous and non-anomalous transaction data. This algorithm is compared against other commonly used under-sampling and over-sampling techniques. Finally, the outcomes of various tree-based single classifiers are compared with those of stacking and voting ensemble classifiers. Our experimental results demonstrate that: (i) XGBCLUS enhances TPR and ROC-AUC scores compared to state-of-the-art under-sampling and over-sampling techniques, and (ii) our proposed ensemble classifiers outperform traditional single tree-based machine learning classifiers in terms of accuracy, TPR, and FPR scores.
An enhanced method of initial cluster center selection for K-means algorithm
Oct 18, 2022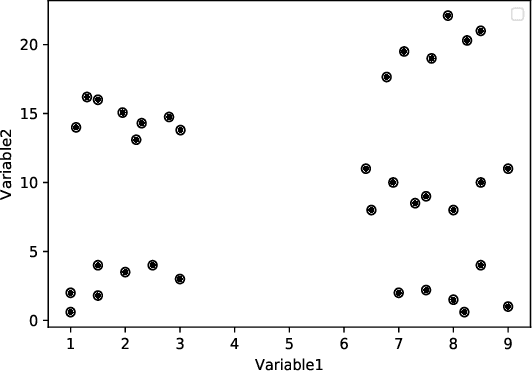
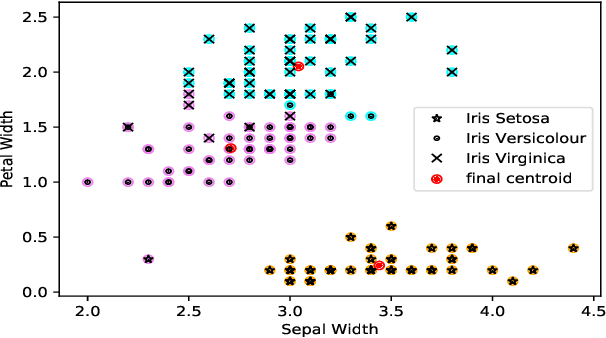
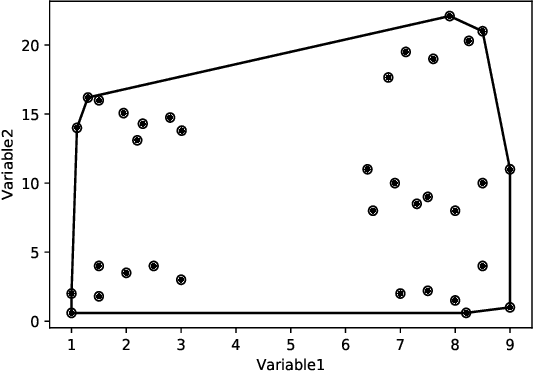
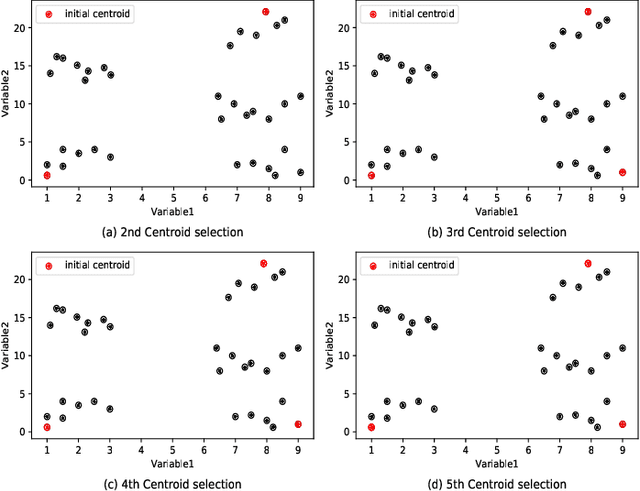
Clustering is one of the widely used techniques to find out patterns from a dataset that can be applied in different applications or analyses. K-means, the most popular and simple clustering algorithm, might get trapped into local minima if not properly initialized and the initialization of this algorithm is done randomly. In this paper, we propose a novel approach to improve initial cluster selection for K-means algorithm. This algorithm is based on the fact that the initial centroids must be well separated from each other since the final clusters are separated groups in feature space. The Convex Hull algorithm facilitates the computing of the first two centroids and the remaining ones are selected according to the distance from previously selected centers. To ensure the selection of one center per cluster, we use the nearest neighbor technique. To check the robustness of our proposed algorithm, we consider several real-world datasets. We obtained only 7.33%, 7.90%, and 0% clustering error in Iris, Letter, and Ruspini data respectively which proves better performance than other existing systems. The results indicate that our proposed method outperforms the conventional K means approach by accelerating the computation when the number of clusters is greater than 2.
* 6 pages