 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Human AI Collaboration in Security Operations Centers with Trusted Autonomy
May 29, 2025This article presents a structured framework for Human-AI collaboration in Security Operations Centers (SOCs), integrating AI autonomy, trust calibration, and Human-in-the-loop decision making. Existing frameworks in SOCs often focus narrowly on automation, lacking systematic structures to manage human oversight, trust calibration, and scalable autonomy with AI. Many assume static or binary autonomy settings, failing to account for the varied complexity, criticality, and risk across SOC tasks considering Humans and AI collaboration. To address these limitations, we propose a novel autonomy tiered framework grounded in five levels of AI autonomy from manual to fully autonomous, mapped to Human-in-the-Loop (HITL) roles and task-specific trust thresholds. This enables adaptive and explainable AI integration across core SOC functions, including monitoring, protection, threat detection, alert triage, and incident response. The proposed framework differentiates itself from previous research by creating formal connections between autonomy, trust, and HITL across various SOC levels, which allows for adaptive task distribution according to operational complexity and associated risks. The framework is exemplified through a simulated cyber range that features the cybersecurity AI-Avatar, a fine-tuned LLM-based SOC assistant. The AI-Avatar case study illustrates human-AI collaboration for SOC tasks, reducing alert fatigue, enhancing response coordination, and strategically calibrating trust. This research systematically presents both the theoretical and practical aspects and feasibility of designing next-generation cognitive SOCs that leverage AI not to replace but to enhance human decision-making.
ExplainableDetector: Exploring Transformer-based Language Modeling Approach for SMS Spam Detection with Explainability Analysis
May 12, 2024SMS, or short messaging service, is a widely used and cost-effective communication medium that has sadly turned into a haven for unwanted messages, commonly known as SMS spam. With the rapid adoption of smartphones and Internet connectivity, SMS spam has emerged as a prevalent threat. Spammers have taken notice of the significance of SMS for mobile phone users. Consequently, with the emergence of new cybersecurity threats, the number of SMS spam has expanded significantly in recent years. The unstructured format of SMS data creates significant challenges for SMS spam detection, making it more difficult to successfully fight spam attacks in the cybersecurity domain. In this work, we employ optimized and fine-tuned transformer-based Large Language Models (LLMs) to solve the problem of spam message detection. We use a benchmark SMS spam dataset for this spam detection and utilize several preprocessing techniques to get clean and noise-free data and solve the class imbalance problem using the text augmentation technique. The overall experiment showed that our optimized fine-tuned BERT (Bidirectional Encoder Representations from Transformers) variant model RoBERTa obtained high accuracy with 99.84\%. We also work with Explainable Artificial Intelligence (XAI) techniques to calculate the positive and negative coefficient scores which explore and explain the fine-tuned model transparency in this text-based spam SMS detection task. In addition, traditional Machine Learning (ML) models were also examined to compare their performance with the transformer-based models. This analysis describes how LLMs can make a good impact on complex textual-based spam data in the cybersecurity field.
A Data-Driven Predictive Analysis on Cyber Security Threats with Key Risk Factors
Mar 28, 2024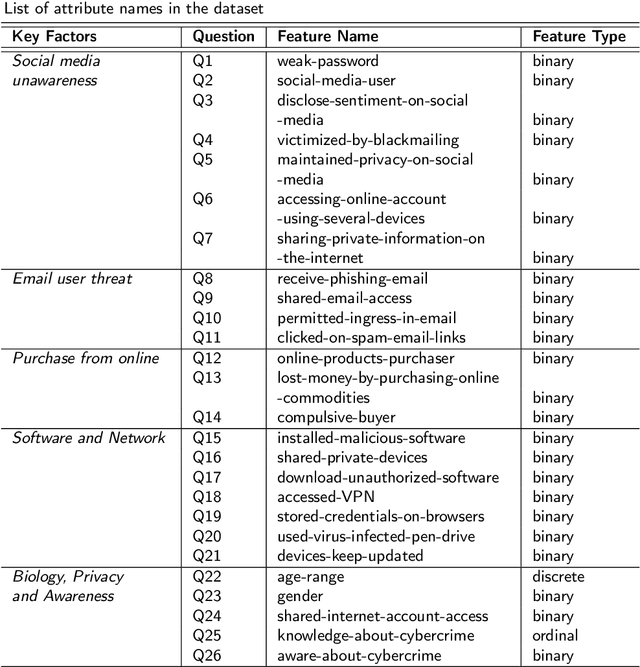
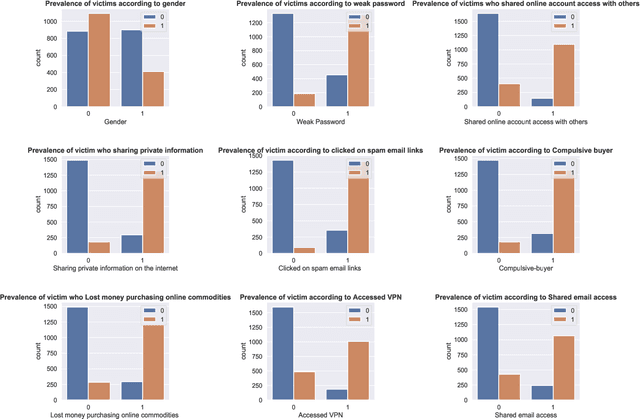
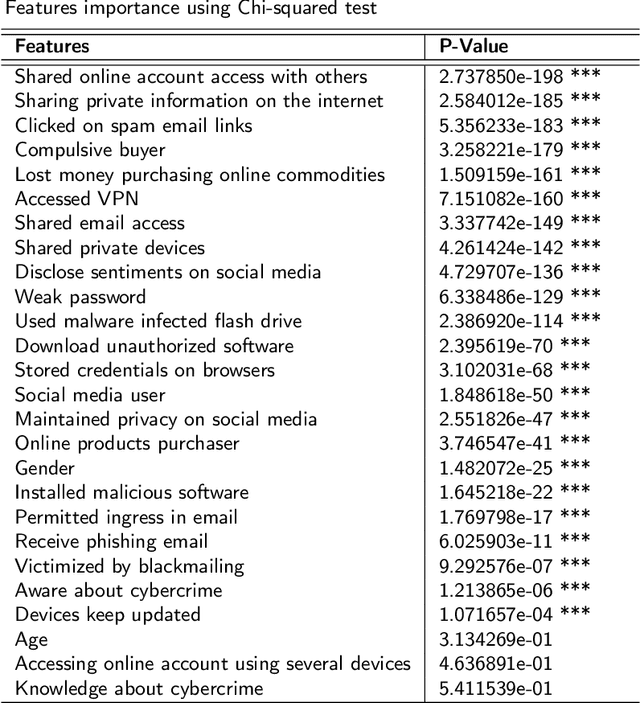
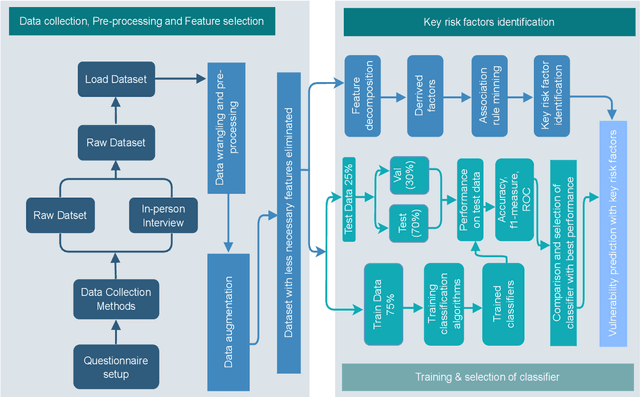
Cyber risk refers to the risk of defacing reputation, monetary losses, or disruption of an organization or individuals, and this situation usually occurs by the unconscious use of cyber systems. The cyber risk is unhurriedly increasing day by day and it is right now a global threat. Developing countries like Bangladesh face major cyber risk challenges. The growing cyber threat worldwide focuses on the need for effective modeling to predict and manage the associated risk. This paper exhibits a Machine Learning(ML) based model for predicting individuals who may be victims of cyber attacks by analyzing socioeconomic factors. We collected the dataset from victims and non-victims of cyberattacks based on socio-demographic features. The study involved the development of a questionnaire to gather data, which was then used to measure the significance of features. Through data augmentation, the dataset was expanded to encompass 3286 entries, setting the stage for our investigation and modeling. Among several ML models with 19, 20, 21, and 26 features, we proposed a novel Pertinent Features Random Forest (RF) model, which achieved maximum accuracy with 20 features (95.95\%) and also demonstrated the association among the selected features using the Apriori algorithm with Confidence (above 80\%) according to the victim. We generated 10 important association rules and presented the framework that is rigorously evaluated on real-world datasets, demonstrating its potential to predict cyberattacks and associated risk factors effectively. Looking ahead, future efforts will be directed toward refining the predictive model's precision and delving into additional risk factors, to fortify the proposed framework's efficacy in navigating the complex terrain of cybersecurity threats.
An Explainable Transformer-based Model for Phishing Email Detection: A Large Language Model Approach
Feb 21, 2024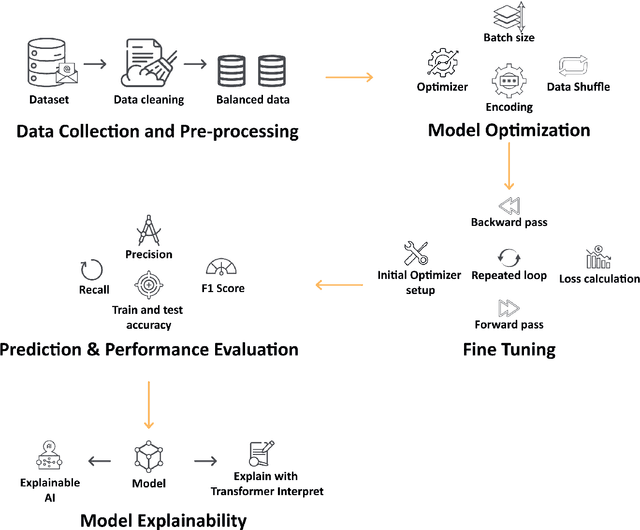



Phishing email is a serious cyber threat that tries to deceive users by sending false emails with the intention of stealing confidential information or causing financial harm. Attackers, often posing as trustworthy entities, exploit technological advancements and sophistication to make detection and prevention of phishing more challenging. Despite extensive academic research, phishing detection remains an ongoing and formidable challenge in the cybersecurity landscape. Large Language Models (LLMs) and Masked Language Models (MLMs) possess immense potential to offer innovative solutions to address long-standing challenges. In this research paper, we present an optimized, fine-tuned transformer-based DistilBERT model designed for the detection of phishing emails. In the detection process, we work with a phishing email dataset and utilize the preprocessing techniques to clean and solve the imbalance class issues. Through our experiments, we found that our model effectively achieves high accuracy, demonstrating its capability to perform well. Finally, we demonstrate our fine-tuned model using Explainable-AI (XAI) techniques such as Local Interpretable Model-Agnostic Explanations (LIME) and Transformer Interpret to explain how our model makes predictions in the context of text classification for phishing emails.
Agricultural Recommendation System based on Deep Learning: A Multivariate Weather Forecasting Approach
Jan 21, 2024Bangladesh is predominantly an agricultural country, where the agrarian sector plays an essential role in accelerating economic growth and enabling the food security of the people. The performance of this sector has an overwhelming impact on the primary macroeconomic objectives like food security, employment generation, poverty alleviation, human resources development, and other economic and social forces. Although Bangladesh's labor-intensive agriculture has achieved steady increases in food grain production, it often suffered from unfavorable weather conditions such as heavy rainfall, low temperature, and drought. Consequently, these factors hinder the production of food substantially, putting the country's overall food security in danger. In order to have a profitable, sustainable, and farmer-friendly agricultural practice, this paper proposes a context-based crop recommendation system powered by a weather forecast model. With extensive evaluation, the multivariate Stacked Bi-LSTM Network is employed as the weather forecasting model. The proposed weather model can forecast Rainfall, Temperature, Humidity, and Sunshine for any given location in Bangladesh with higher accuracy. These predictions guide our system to assist the farmers in making feasible decisions about planting, irrigation, harvesting, and so on. Additionally, our full-fledged system is capable of alerting the farmers about extreme weather conditions so that preventive measures can be undertaken to protect the crops. Finally, the system is also adept at making knowledge-based crop suggestions for the flood and drought-prone regions of Bangladesh.
Detecting Anomalies in Blockchain Transactions using Machine Learning Classifiers and Explainability Analysis
Jan 07, 2024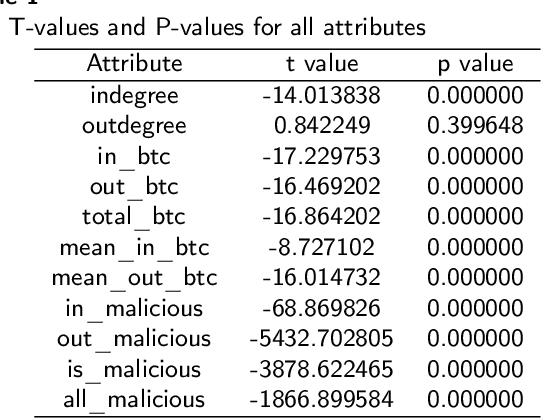
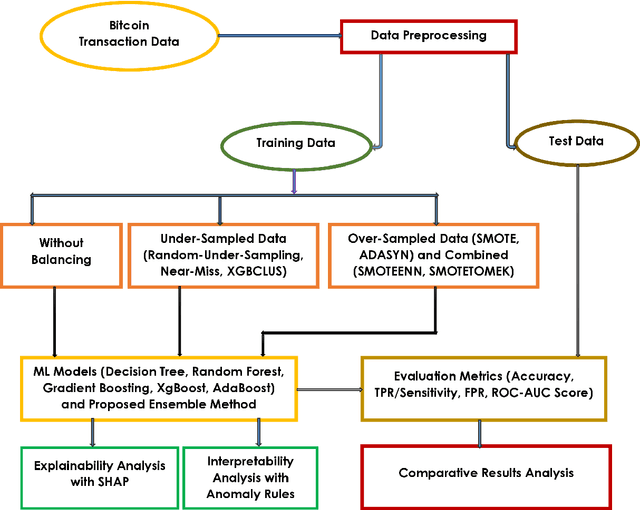

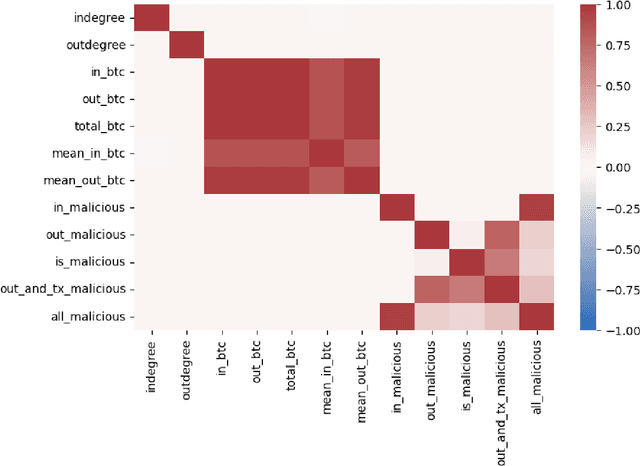
As the use of Blockchain for digital payments continues to rise in popularity, it also becomes susceptible to various malicious attacks. Successfully detecting anomalies within Blockchain transactions is essential for bolstering trust in digital payments. However, the task of anomaly detection in Blockchain transaction data is challenging due to the infrequent occurrence of illicit transactions. Although several studies have been conducted in the field, a limitation persists: the lack of explanations for the model's predictions. This study seeks to overcome this limitation by integrating eXplainable Artificial Intelligence (XAI) techniques and anomaly rules into tree-based ensemble classifiers for detecting anomalous Bitcoin transactions. The Shapley Additive exPlanation (SHAP) method is employed to measure the contribution of each feature, and it is compatible with ensemble models. Moreover, we present rules for interpreting whether a Bitcoin transaction is anomalous or not. Additionally, we have introduced an under-sampling algorithm named XGBCLUS, designed to balance anomalous and non-anomalous transaction data. This algorithm is compared against other commonly used under-sampling and over-sampling techniques. Finally, the outcomes of various tree-based single classifiers are compared with those of stacking and voting ensemble classifiers. Our experimental results demonstrate that: (i) XGBCLUS enhances TPR and ROC-AUC scores compared to state-of-the-art under-sampling and over-sampling techniques, and (ii) our proposed ensemble classifiers outperform traditional single tree-based machine learning classifiers in terms of accuracy, TPR, and FPR scores.
Exploring a Hybrid Deep Learning Framework to Automatically Discover Topic and Sentiment in COVID-19 Tweets
Dec 02, 2023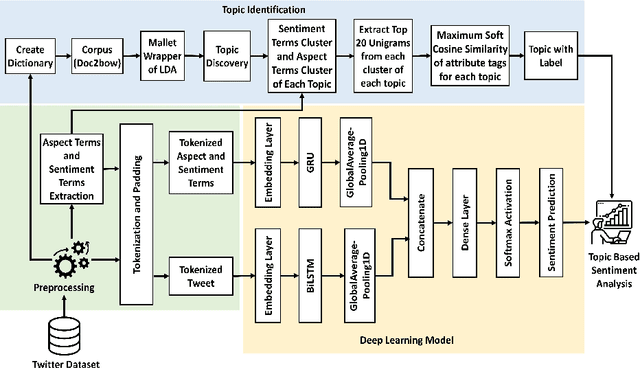
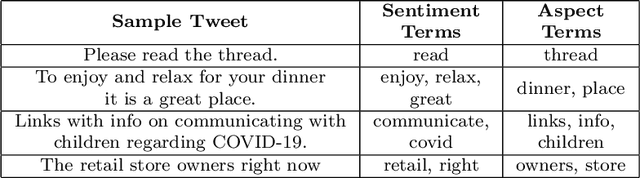
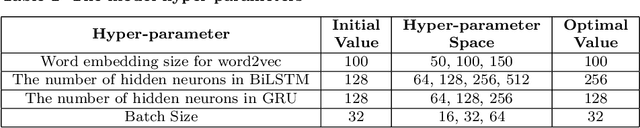
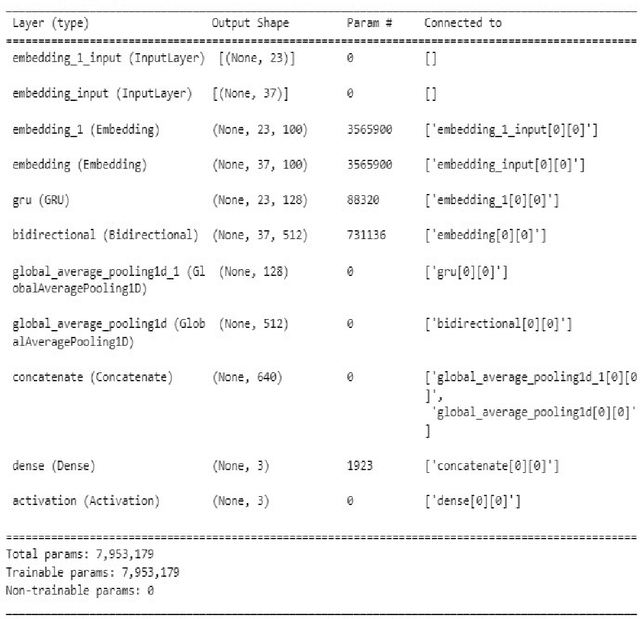
COVID-19 has created a major public health problem worldwide and other problems such as economic crisis, unemployment, mental distress, etc. The pandemic is deadly in the world and involves many people not only with infection but also with problems, stress, wonder, fear, resentment, and hatred. Twitter is a highly influential social media platform and a significant source of health-related information, news, opinion and public sentiment where information is shared by both citizens and government sources. Therefore an effective analysis of COVID-19 tweets is essential for policymakers to make wise decisions. However, it is challenging to identify interesting and useful content from major streams of text to understand people's feelings about the important topics of the COVID-19 tweets. In this paper, we propose a new \textit{framework} for analyzing topic-based sentiments by extracting key topics with significant labels and classifying positive, negative, or neutral tweets on each topic to quickly find common topics of public opinion and COVID-19-related attitudes. While building our model, we take into account hybridization of BiLSTM and GRU structures for sentiment analysis to achieve our goal. The experimental results show that our topic identification method extracts better topic labels and the sentiment analysis approach using our proposed hybrid deep learning model achieves the highest accuracy compared to traditional models.
A Dynamic Topic Identification and Labeling Approach of COVID-19 Tweets
Aug 13, 2021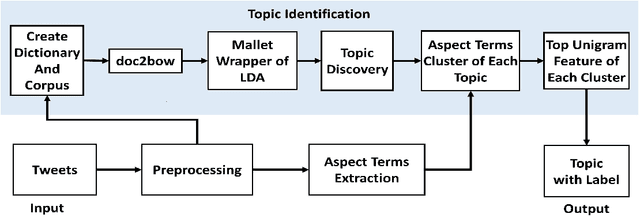

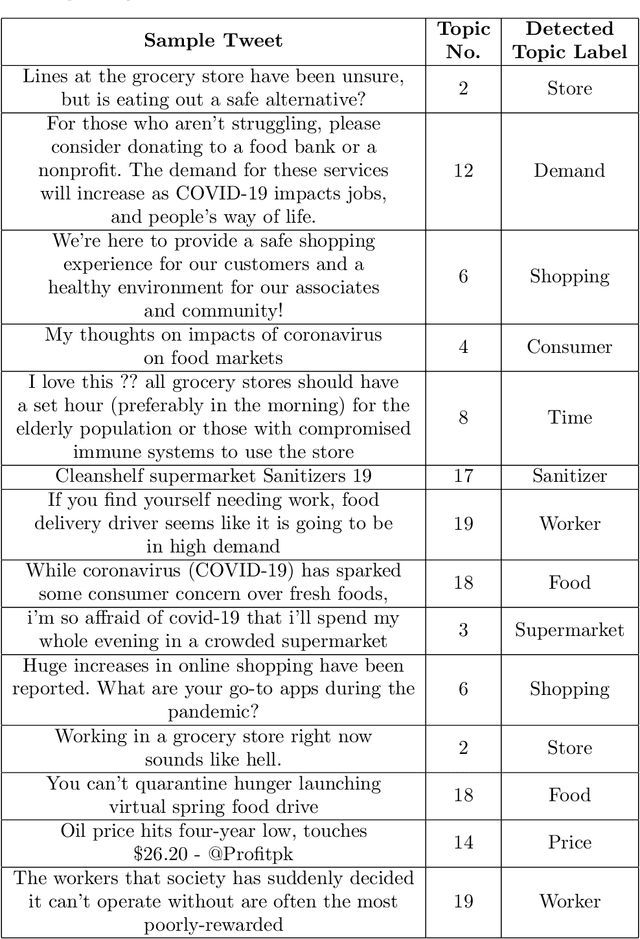
This paper formulates the problem of dynamically identifying key topics with proper labels from COVID-19 Tweets to provide an overview of wider public opinion. Nowadays, social media is one of the best ways to connect people through Internet technology, which is also considered an essential part of our daily lives. In late December 2019, an outbreak of the novel coronavirus, COVID-19 was reported, and the World Health Organization declared an emergency due to its rapid spread all over the world. The COVID-19 epidemic has affected the use of social media by many people across the globe. Twitter is one of the most influential social media services, which has seen a dramatic increase in its use from the epidemic. Thus dynamic extraction of specific topics with labels from tweets of COVID-19 is a challenging issue for highlighting conversation instead of manual topic labeling approach. In this paper, we propose a framework that automatically identifies the key topics with labels from the tweets using the top Unigram feature of aspect terms cluster from Latent Dirichlet Allocation (LDA) generated topics. Our experiment result shows that this dynamic topic identification and labeling approach is effective having the accuracy of 85.48\% with respect to the manual static approach.
Emotion Classification in a Resource Constrained Language Using Transformer-based Approach
Apr 17, 2021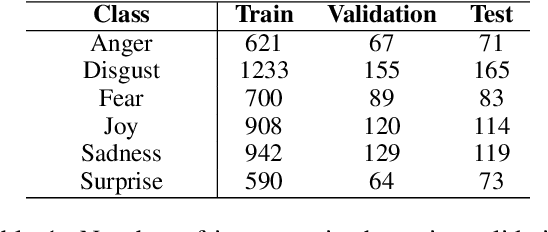
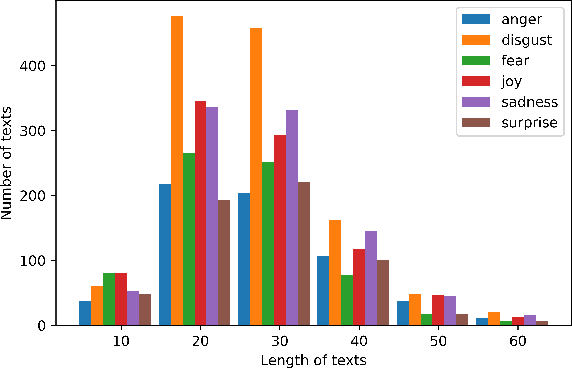
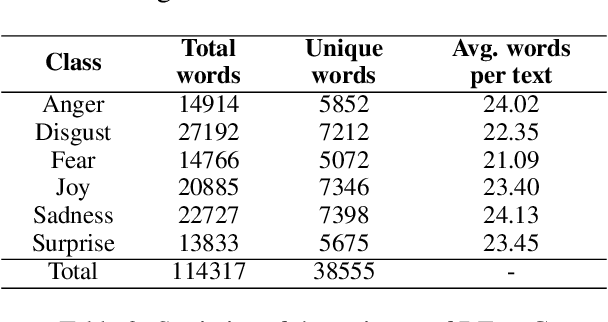
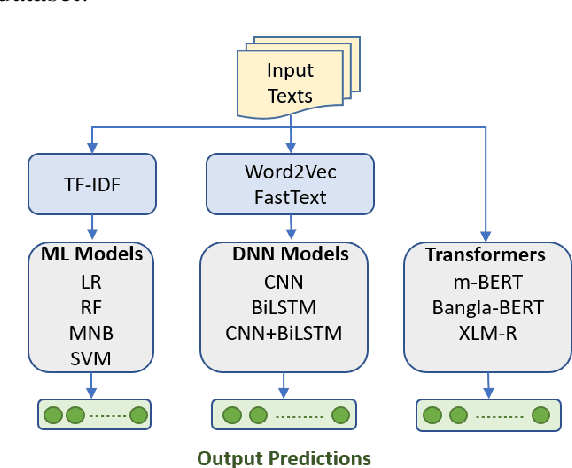
Although research on emotion classification has significantly progressed in high-resource languages, it is still infancy for resource-constrained languages like Bengali. However, unavailability of necessary language processing tools and deficiency of benchmark corpora makes the emotion classification task in Bengali more challenging and complicated. This work proposes a transformer-based technique to classify the Bengali text into one of the six basic emotions: anger, fear, disgust, sadness, joy, and surprise. A Bengali emotion corpus consists of 6243 texts is developed for the classification task. Experimentation carried out using various machine learning (LR, RF, MNB, SVM), deep neural networks (CNN, BiLSTM, CNN+BiLSTM) and transformer (Bangla-BERT, m-BERT, XLM-R) based approaches. Experimental outcomes indicate that XLM-R outdoes all other techniques by achieving the highest weighted $f_1$-score of $69.73\%$ on the test data. The dataset is publicly available at https://github.com/omar-sharif03/NAACL-SRW-2021.
CyberLearning: Effectiveness Analysis of Machine Learning Security Modeling to Detect Cyber-Anomalies and Multi-Attacks
Mar 28, 2021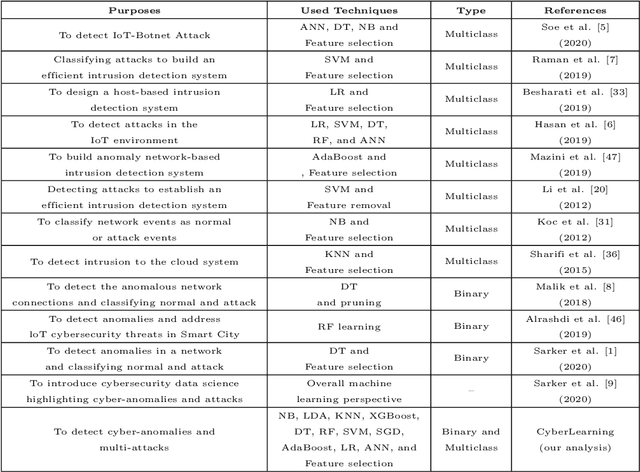
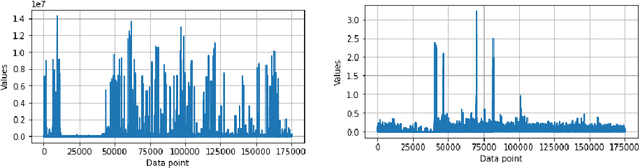
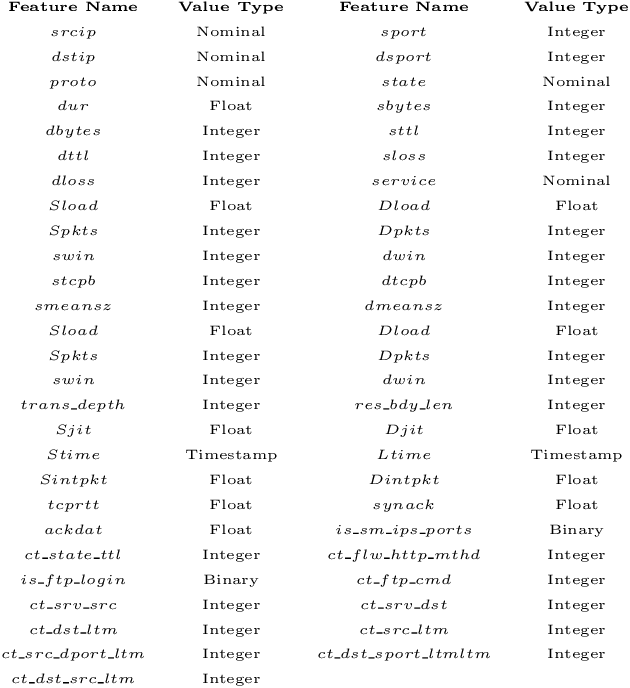
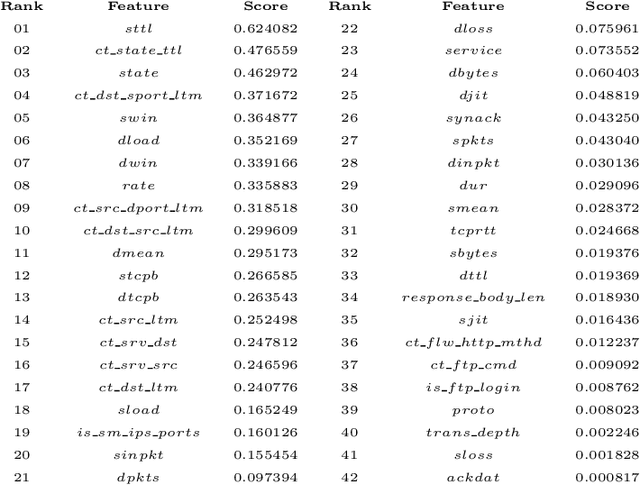
Detecting cyber-anomalies and attacks are becoming a rising concern these days in the domain of cybersecurity. The knowledge of artificial intelligence, particularly, the machine learning techniques can be used to tackle these issues. However, the effectiveness of a learning-based security model may vary depending on the security features and the data characteristics. In this paper, we present "CyberLearning", a machine learning-based cybersecurity modeling with correlated-feature selection, and a comprehensive empirical analysis on the effectiveness of various machine learning based security models. In our CyberLearning modeling, we take into account a binary classification model for detecting anomalies, and multi-class classification model for various types of cyber-attacks. To build the security model, we first employ the popular ten machine learning classification techniques, such as naive Bayes, Logistic regression, Stochastic gradient descent, K-nearest neighbors, Support vector machine, Decision Tree, Random Forest, Adaptive Boosting, eXtreme Gradient Boosting, as well as Linear discriminant analysis. We then present the artificial neural network-based security model considering multiple hidden layers. The effectiveness of these learning-based security models is examined by conducting a range of experiments utilizing the two most popular security datasets, UNSW-NB15 and NSL-KDD. Overall, this paper aims to serve as a reference point for data-driven security modeling through our experimental analysis and findings in the context of cybersecurity.