 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyberLearning: Effectiveness Analysis of Machine Learning Security Modeling to Detect Cyber-Anomalies and Multi-Attacks
Paper and Code
Mar 28, 2021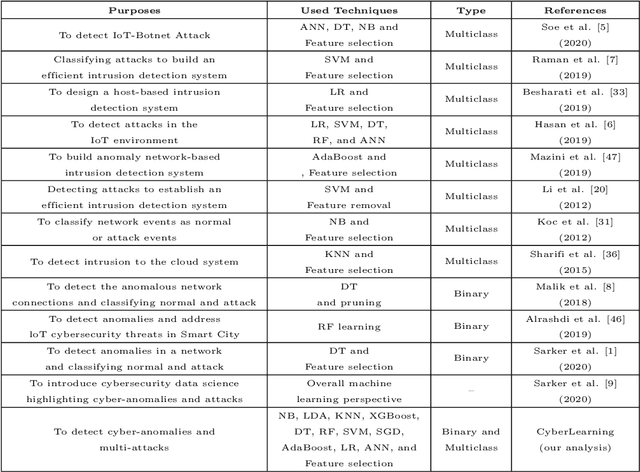
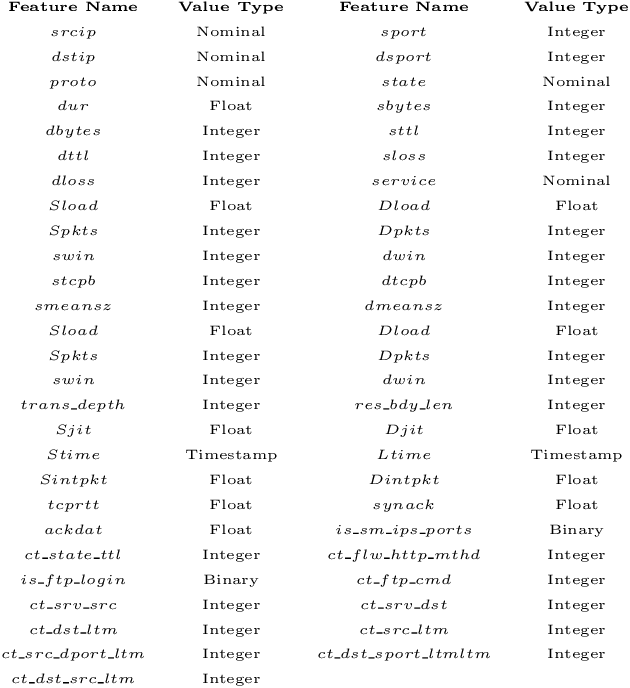
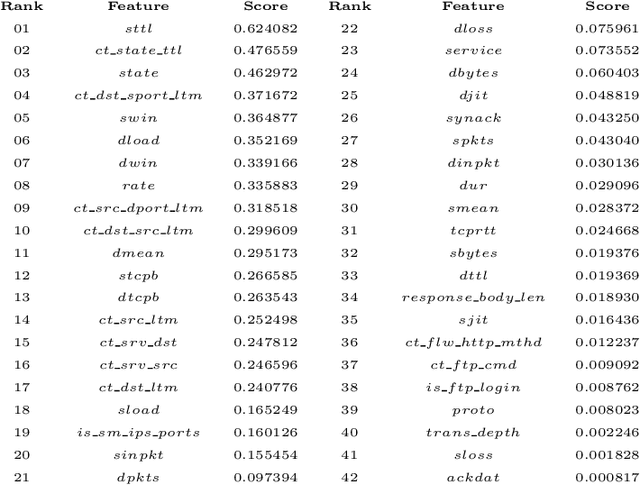
Detecting cyber-anomalies and attacks are becoming a rising concern these days in the domain of cybersecurity. The knowledge of artificial intelligence, particularly, the machine learning techniques can be used to tackle these issues. However, the effectiveness of a learning-based security model may vary depending on the security features and the data characteristics. In this paper, we present "CyberLearning", a machine learning-based cybersecurity modeling with correlated-feature selection, and a comprehensive empirical analysis on the effectiveness of various machine learning based security models. In our CyberLearning modeling, we take into account a binary classification model for detecting anomalies, and multi-class classification model for various types of cyber-attacks. To build the security model, we first employ the popular ten machine learning classification techniques, such as naive Bayes, Logistic regression, Stochastic gradient descent, K-nearest neighbors, Support vector machine, Decision Tree, Random Forest, Adaptive Boosting, eXtreme Gradient Boosting, as well as Linear discriminant analysis. We then present the artificial neural network-based security model considering multiple hidden layers. The effectiveness of these learning-based security models is examined by conducting a range of experiments utilizing the two most popular security datasets, UNSW-NB15 and NSL-KDD. Overall, this paper aims to serve as a reference point for data-driven security modeling through our experimental analysis and findings in the context of cybersecurity.