 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sight to Insight: Improving Visual Reasoning Capabilities of Multimodal Models via Reinforcement Learning
Jan 01, 2026Reinforcement learning (RL) has emerged as a promising approach for eliciting reasoning chains before generating final answers. However, multimodal large language models (MLLMs) generate reasoning that lacks integration of visual information. This limits their ability to solve problems that demand accurate visual perception, such as visual puzzles. We show that visual perception is the key bottleneck in such tasks: converting images into textual descriptions significantly improves performance, yielding gains of 26.7% for Claude 3.5 and 23.6% for Claude 3.7. To address this, we investigate reward-driven RL as a mechanism to unlock long visual reasoning in open-source MLLMs without requiring costly supervision. We design and evaluate six reward functions targeting different reasoning aspects, including image understanding, thinking steps, and answer accuracy. Using group relative policy optimization (GRPO), our approach explicitly incentivizes longer, structured reasoning and mitigates bypassing of visual information. Experiments on Qwen-2.5-VL-7B achieve 5.56% improvements over the base model, with consistent gains across both in-domain and out-of-domain settings.
Socially Constructed Treatment Plans: Analyzing Online Peer Interactions to Understand How Patients Navigate Complex Medical Conditions
Mar 27, 2025When faced with complex and uncertain medical conditions (e.g., cancer, mental health conditions, recovery from substance dependency), millions of patients seek online peer support. In this study, we leverage content analysis of online discourse and ethnographic studies with clinicians and patient representatives to characterize how treatment plans for complex conditions are "socially constructed." Specifically, we ground online conversation on medication-assisted recovery treatment to medication guidelines and subsequently surface when and why people deviate from the clinical guidelines. We characterize the implications and effectiveness of socially constructed treatment plans through in-depth interviews with clinical experts. Finally, given the enthusiasm around AI-powered solutions for patient communication, we investigate whether and how socially constructed treatment-related knowledge is reflected in a state-of-the-art large language model (LLM). Leveraging a novel mixed-method approach, this study highlights critical research directions for patient-centered communication in online health communities.
REGen: A Reliable Evaluation Framework for Generative Event Argument Extraction
Feb 24, 2025Event argument extraction identifies arguments for predefined event roles in text. Traditional evaluations rely on exact match (EM), requiring predicted arguments to match annotated spans exactly. However, this approach fails for generative models like large language models (LLMs), which produce diverse yet semantically accurate responses. EM underestimates performance by disregarding valid variations, implicit arguments (unstated but inferable), and scattered arguments (distributed across a document). To bridge this gap, we introduce Reliable Evaluation framework for Generative event argument extraction (REGen), a framework that better aligns with human judgment. Across six datasets, REGen improves performance by an average of 23.93 F1 points over EM. Human validation further confirms REGen's effectiveness, achieving 87.67% alignment with human assessments of argument correctness.
Explicit, Implicit, and Scattered: Revisiting Event Extraction to Capture Complex Arguments
Oct 04, 2024



Prior works formulate the extraction of event-specific arguments as a span extraction problem, where event arguments are explicit -- i.e. assumed to be contiguous spans of text in a document. In this study, we revisit this definition of Event Extraction (EE) by introducing two key argument types that cannot be modeled by existing EE frameworks. First, implicit arguments are event arguments which are not explicitly mentioned in the text, but can be inferred through context. Second, scattered arguments are event arguments that are composed of information scattered throughout the text. These two argument types are crucial to elicit the full breadth of information required for proper event modeling. To support the extraction of explicit, implicit, and scattered arguments, we develop a novel dataset, DiscourseEE, which includes 7,464 argument annotations from online health discourse. Notably, 51.2% of the arguments are implicit, and 17.4% are scattered, making DiscourseEE a unique corpus for complex event extraction. Additionally, we formulate argument extraction as a text generation problem to facilitate the extraction of complex argument types. We provide a comprehensive evaluation of state-of-the-art models and highlight critical open challenges in generative event extraction. Our data and codebase are available at https://omar-sharif03.github.io/DiscourseEE.
A Thematic Framework for Analyzing Large-scale Self-reported Social Media Data on Opioid Use Disorder Treatment Using Buprenorphine Product
Oct 02, 2024Background: One of the key FDA-approved medications for Opioid Use Disorder (OUD) is buprenorphine. Despite its popularity, individuals often report various information needs regarding buprenorphine treatment on social media platforms like Reddit. However, the key challenge is to characterize these needs. In this study, we propose a theme-based framework to curate and analyze large-scale data from social media to characterize self-reported treatment information needs (TINs). Methods: We collected 15,253 posts from r/Suboxone, one of the largest Reddit sub-community for buprenorphine products. Following the standard protocol, we first identified and defined five main themes from the data and then coded 6,000 posts based on these themes, where one post can be labeled with applicable one to three themes. Finally, we determined the most frequently appearing sub-themes (topics) for each theme by analyzing samples from each group. Results: Among the 6,000 posts, 40.3% contained a single theme, 36% two themes, and 13.9% three themes. The most frequent topics for each theme or theme combination came with several key findings - prevalent reporting of psychological and physical effects during recovery, complexities in accessing buprenorphine, and significant information gaps regarding medication administration, tapering, and usage of substances during different stages of recovery. Moreover, self-treatment strategies and peer-driven advice reveal valuable insights and potential misconceptions. Conclusions: The findings obtained using our proposed framework can inform better patient education and patient-provider communication, design systematic interventions to address treatment-related misconceptions and rumors, and streamline the generation of hypotheses for future research.
Do LLMs Find Human Answers To Fact-Driven Questions Perplexing? A Case Study on Reddit
Apr 01, 2024Large language models (LLMs) have been shown to be proficient in correctly answering questions in the context of online discourse. However, the study of using LLMs to model human-like answers to fact-driven social media questions is still under-explored. In this work, we investigate how LLMs model the wide variety of human answers to fact-driven questions posed on several topic-specific Reddit communities, or subreddits. We collect and release a dataset of 409 fact-driven questions and 7,534 diverse, human-rated answers from 15 r/Ask{Topic} communities across 3 categories: profession, social identity, and geographic location. We find that LLMs are considerably better at modeling highly-rated human answers to such questions, as opposed to poorly-rated human answers. We present several directions for future research based on our initial findings.
Deciphering Hate: Identifying Hateful Memes and Their Targets
Mar 16, 2024
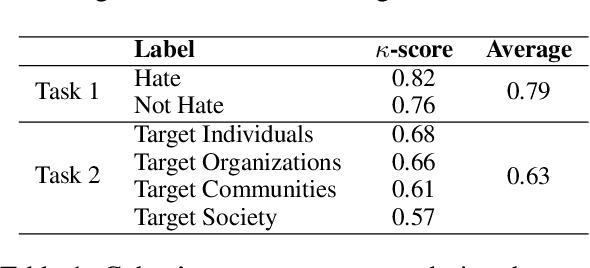
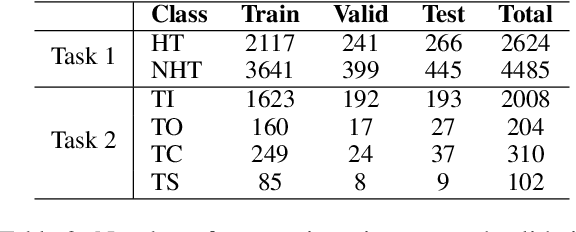
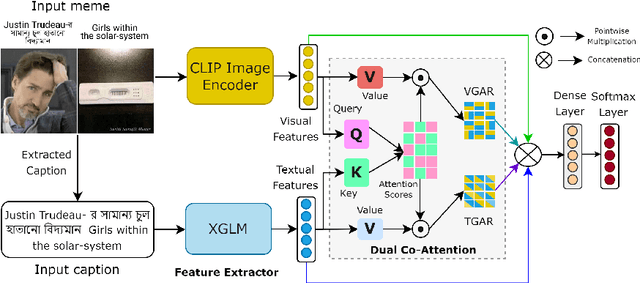
Internet memes have become a powerful means for individuals to express emotions, thoughts, and perspectives on social media. While often considered as a source of humor and entertainment, memes can also disseminate hateful content targeting individuals or communities. Most existing research focuses on the negative aspects of memes in high-resource languages, overlooking the distinctive challenges associated with low-resource languages like Bengali (also known as Bangla). Furthermore, while previous work on Bengali memes has focused on detecting hateful memes, there has been no work on detecting their targeted entities. To bridge this gap and facilitate research in this arena, we introduce a novel multimodal dataset for Bengali, BHM (Bengali Hateful Memes). The dataset consists of 7,148 memes with Bengali as well as code-mixed captions, tailored for two tasks: (i) detecting hateful memes, and (ii) detecting the social entities they target (i.e., Individual, Organization, Community, and Society). To solve these tasks, we propose DORA (Dual cO attention fRAmework), a multimodal deep neural network that systematically extracts the significant modality features from the memes and jointly evaluates them with the modality-specific features to understand the context better. Our experiments show that DORA is generalizable on other low-resource hateful meme datasets and outperforms several state-of-the-art rivaling baselines.
Mad Libs Are All You Need: Augmenting Cross-Domain Document-Level Event Argument Data
Mar 05, 2024Document-Level Event Argument Extraction (DocEAE) is an extremely difficult information extraction problem -- with significant limitations in low-resource cross-domain settings. To address this problem, we introduce Mad Lib Aug (MLA), a novel generative DocEAE data augmentation framework. Our approach leverages the intuition that Mad Libs, which are categorically masked documents used as a part of a popular game, can be generated and solved by LLMs to produce data for DocEAE. Using MLA, we achieve a 2.6-point average improvement in overall F1 score. Moreover, this approach achieves a 3.9 and 5.2 point average increase in zero and few-shot event roles compared to augmentation-free baselines across all experiments. To better facilitate analysis of cross-domain DocEAE, we additionally introduce a new metric, Role-Depth F1 (RDF1), which uses statistical depth to identify roles in the target domain which are semantic outliers with respect to roles observed in the source domain. Our experiments show that MLA augmentation can boost RDF1 performance by an average of 5.85 points compared to non-augmented datasets.
Align before Attend: Aligning Visual and Textual Features for Multimodal Hateful Content Detection
Feb 15, 2024Multimodal hateful content detection is a challenging task that requires complex reasoning across visual and textual modalities. Therefore, creating a meaningful multimodal representation that effectively captures the interplay between visual and textual features through intermediate fusion is critical. Conventional fusion techniques are unable to attend to the modality-specific features effectively. Moreover, most studies exclusively concentrated on English and overlooked other low-resource languages. This paper proposes a context-aware attention framework for multimodal hateful content detection and assesses it for both English and non-English languages. The proposed approach incorporates an attention layer to meaningfully align the visual and textual features. This alignment enables selective focus on modality-specific features before fusing them. We evaluate the proposed approach on two benchmark hateful meme datasets, viz. MUTE (Bengali code-mixed) and MultiOFF (English). Evaluation results demonstrate our proposed approach's effectiveness with F1-scores of $69.7$% and $70.3$% for the MUTE and MultiOFF datasets. The scores show approximately $2.5$% and $3.2$% performance improvement over the state-of-the-art systems on these datasets. Our implementation is available at https://github.com/eftekhar-hossain/Bengali-Hateful-Memes.
Chain-of-Thought Embeddings for Stance Detection on Social Media
Oct 30, 2023Stance detection on social media is challenging for Large Language Models (LLMs), as emerging slang and colloquial language in online conversations often contain deeply implicit stance labels. Chain-of-Thought (COT) prompting has recently been shown to improve performance on stance detection tasks -- alleviating some of these issues. However, COT prompting still struggles with implicit stance identification. This challenge arises because many samples are initially challenging to comprehend before a model becomes familiar with the slang and evolving knowledge related to different topics, all of which need to be acquired through the training data. In this study, we address this problem by introducing COT Embeddings which improve COT performance on stance detection tasks by embedding COT reasonings and integrating them into a traditional RoBERTa-based stance detection pipeline. Our analysis demonstrates that 1) text encoders can leverage COT reasonings with minor errors or hallucinations that would otherwise distort the COT output label. 2) Text encoders can overlook misleading COT reasoning when a sample's prediction heavily depends on domain-specific patterns. Our model achieves SOTA performance on multiple stance detection datasets collected from social media.