 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Distribution Shift in User Prompts and Its Effects on LLM Performance
Apr 19, 2026LLMs are increasingly deployed in dynamic, real-world settings, where the distribution of user prompts can shift substantially over time as new tasks, prompts, and users are introduced to a deployed model. Such natural prompt distribution shift poses a major challenge to LLM reliability, particularly for specialized models designed for narrow domains or user populations. Despite attention to out-of-distribution robustness, there is very limited exploration of measuring natural prompt distribution shift in prior work, and its impact on deployed LLMs remains poorly understood. We introduce the LLM Evaluation under Natural prompt Shift (LENS) framework: a data-centric approach for quantifying natural prompt distribution shift and evaluating its effect on the performance of deployed LLMs. We perform a large-scale evaluation using 192 real-world post-deployment prompt shift settings over time, user group, and geographic axes, training a total of 81 models on 4.68M training prompts, and evaluating on 57.6k prompts. We find that even moderate shifts in user prompt behavior correspond with large performance drops (73% average loss) in deployed LLMs. This performance degradation is particularly prevalent when users from different latent groups and geographic regions interact with models and is correlated with natural prompt distribution shift over time. We systematically characterize how LLM instruction following ability degrades over time and between user groups. Our findings highlight the critical need for data-driven monitoring to ensure LLM performance remains stable across diverse and evolving user populations.
How Much Would a Clinician Edit This Draft? Evaluating LLM Alignment for Patient Message Response Drafting
Jan 16, 2026Large language models (LLMs) show promise in drafting responses to patient portal messages, yet their integration into clinical workflows raises various concerns, including whether they would actually save clinicians time and effort in their portal workload. We investigate LLM alignment with individual clinicians through a comprehensive evaluation of the patient message response drafting task. We develop a novel taxonomy of thematic elements in clinician responses and propose a novel evaluation framework for assessing clinician editing load of LLM-drafted responses at both content and theme levels. We release an expert-annotated dataset and conduct large-scale evaluations of local and commercial LLMs using various adaptation techniques including thematic prompting, retrieval-augmented generation, supervised fine-tuning, and direct preference optimization. Our results reveal substantial epistemic uncertainty in aligning LLM drafts with clinician responses. While LLMs demonstrate capability in drafting certain thematic elements, they struggle with clinician-aligned generation in other themes, particularly question asking to elicit further information from patients. Theme-driven adaptation strategies yield improvements across most themes. Our findings underscore the necessity of adapting LLMs to individual clinician preferences to enable reliable and responsible use in patient-clinician communication workflows.
Can LLMs Solve My Grandma's Riddle? Evaluating Multilingual Large Language Models on Reasoning Traditional Bangla Tricky Riddles
Dec 23, 2025Large Language Models (LLMs) show impressive performance on many NLP benchmarks, yet their ability to reason in figurative, culturally grounded, and low-resource settings remains underexplored. We address this gap for Bangla by introducing BanglaRiddleEval, a benchmark of 1,244 traditional Bangla riddles instantiated across four tasks (4,976 riddle-task artifacts in total). Using an LLM-based pipeline, we generate Chain-of-Thought explanations, semantically coherent distractors, and fine-grained ambiguity annotations, and evaluate a diverse suite of open-source and closed-source models under different prompting strategies. Models achieve moderate semantic overlap on generative QA but low correctness, MCQ accuracy peaks at only about 56% versus an 83% human baseline, and ambiguity resolution ranges from roughly 26% to 68%, with high-quality explanations confined to the strongest models. These results show that current LLMs capture some cues needed for Bangla riddle reasoning but remain far from human-level performance, establishing BanglaRiddleEval as a challenging new benchmark for low-resource figurative reasoning. All data, code, and evaluation scripts are available on GitHub: https://github.com/Labib1610/BanglaRiddleEval.
In-Context Learning for Preserving Patient Privacy: A Framework for Synthesizing Realistic Patient Portal Messages
Nov 10, 2024
Since the COVID-19 pandemic, clinicians have seen a large and sustained influx in patient portal messages, significantly contributing to clinician burnout. To the best of our knowledge, there are no large-scale public patient portal messages corpora researchers can use to build tools to optimize clinician portal workflows. Informed by our ongoing work with a regional hospital, this study introduces an LLM-powered framework for configurable and realistic patient portal message generation. Our approach leverages few-shot grounded text generation, requiring only a small number of de-identified patient portal messages to help LLMs better match the true style and tone of real data. Clinical experts in our team deem this framework as HIPAA-friendly, unlike existing privacy-preserving approaches to synthetic text generation which cannot guarantee all sensitive attributes will be protected. Through extensive quantitative and human evaluation, we show that our framework produces data of higher quality than comparable generation methods as well as all related datasets. We believe this work provides a path forward for (i) the release of large-scale synthetic patient message datasets that are stylistically similar to ground-truth samples and (ii) HIPAA-friendly data generation which requires minimal human de-identification efforts.
Depth $F_1$: Improving Evaluation of Cross-Domain Text Classification by Measuring Semantic Generalizability
Jun 20, 2024



Recent evaluations of cross-domain text classification models aim to measure the ability of a model to obtain domain-invariant performance in a target domain given labeled samples in a source domain. The primary strategy for this evaluation relies on assumed differences between source domain samples and target domain samples in benchmark datasets. This evaluation strategy fails to account for the similarity between source and target domains, and may mask when models fail to transfer learning to specific target samples which are highly dissimilar from the source domain. We introduce Depth $F_1$, a novel cross-domain text classification performance metric. Designed to be complementary to existing classification metrics such as $F_1$, Depth $F_1$ measures how well a model performs on target samples which are dissimilar from the source domain. We motivate this metric using standard cross-domain text classification datasets and benchmark several recent cross-domain text classification models, with the goal of enabling in-depth evaluation of the semantic generalizability of cross-domain text classification models.
Do LLMs Find Human Answers To Fact-Driven Questions Perplexing? A Case Study on Reddit
Apr 01, 2024Large language models (LLMs) have been shown to be proficient in correctly answering questions in the context of online discourse. However, the study of using LLMs to model human-like answers to fact-driven social media questions is still under-explored. In this work, we investigate how LLMs model the wide variety of human answers to fact-driven questions posed on several topic-specific Reddit communities, or subreddits. We collect and release a dataset of 409 fact-driven questions and 7,534 diverse, human-rated answers from 15 r/Ask{Topic} communities across 3 categories: profession, social identity, and geographic location. We find that LLMs are considerably better at modeling highly-rated human answers to such questions, as opposed to poorly-rated human answers. We present several directions for future research based on our initial findings.
Chain-of-Thought Embeddings for Stance Detection on Social Media
Oct 30, 2023Stance detection on social media is challenging for Large Language Models (LLMs), as emerging slang and colloquial language in online conversations often contain deeply implicit stance labels. Chain-of-Thought (COT) prompting has recently been shown to improve performance on stance detection tasks -- alleviating some of these issues. However, COT prompting still struggles with implicit stance identification. This challenge arises because many samples are initially challenging to comprehend before a model becomes familiar with the slang and evolving knowledge related to different topics, all of which need to be acquired through the training data. In this study, we address this problem by introducing COT Embeddings which improve COT performance on stance detection tasks by embedding COT reasonings and integrating them into a traditional RoBERTa-based stance detection pipeline. Our analysis demonstrates that 1) text encoders can leverage COT reasonings with minor errors or hallucinations that would otherwise distort the COT output label. 2) Text encoders can overlook misleading COT reasoning when a sample's prediction heavily depends on domain-specific patterns. Our model achieves SOTA performance on multiple stance detection datasets collected from social media.
Statistical Depth for Ranking and Characterizing Transformer-Based Text Embeddings
Oct 23, 2023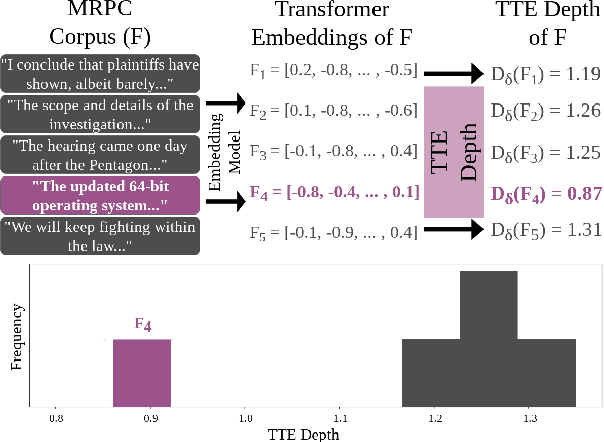



The popularity of transformer-based text embeddings calls for better statistical tools for measuring distributions of such embeddings. One such tool would be a method for ranking texts within a corpus by centrality, i.e. assigning each text a number signifying how representative that text is of the corpus as a whole. However, an intrinsic center-outward ordering of high-dimensional text representations is not trivial. A statistical depth is a function for ranking k-dimensional objects by measuring centrality with respect to some observed k-dimensional distribution. We adopt a statistical depth to measure distributions of transformer-based text embeddings, transformer-based text embedding (TTE) depth, and introduce the practical use of this depth for both modeling and distributional inference in NLP pipelines. We first define TTE depth and an associated rank sum test for determining whether two corpora differ significantly in embedding space. We then use TTE depth for the task of in-context learning prompt selection, showing that this approach reliably improves performance over statistical baseline approaches across six text classification tasks. Finally, we use TTE depth and the associated rank sum test to characterize the distributions of synthesized and human-generated corpora, showing that five recent synthetic data augmentation processes cause a measurable distributional shift away from associated human-generated text.
Text Encoders Lack Knowledge: Leveraging Generative LLMs for Domain-Specific Semantic Textual Similarity
Sep 12, 2023Amidst the sharp rise in the evaluation of large language models (LLMs) on various tasks, we find that semantic textual similarity (STS) has been under-explored. In this study, we show that STS can be cast as a text generation problem while maintaining strong performance on multiple STS benchmarks. Additionally, we show generative LLMs significantly outperform existing encoder-based STS models when characterizing the semantic similarity between two texts with complex semantic relationships dependent on world knowledge. We validate this claim by evaluating both generative LLMs and existing encoder-based STS models on three newly collected STS challenge sets which require world knowledge in the domains of Health, Politics, and Sports. All newly collected data is sourced from social media content posted after May 2023 to ensure the performance of closed-source models like ChatGPT cannot be credited to memorization. Our results show that, on average, generative LLMs outperform the best encoder-only baselines by an average of 22.3% on STS tasks requiring world knowledge. Our results suggest generative language models with STS-specific prompting strategies achieve state-of-the-art performance in complex, domain-specific STS tasks.
Characterizing Information Seeking Events in Health-Related Social Discourse
Aug 17, 2023Social media sites have become a popular platform for individuals to seek and share health information. Despite the progress in natural language processing for social media mining, a gap remains in analyzing health-related texts on social discourse in the context of events. Event-driven analysis can offer insights into different facets of healthcare at an individual and collective level, including treatment options, misconceptions, knowledge gaps, etc. This paper presents a paradigm to characterize health-related information-seeking in social discourse through the lens of events. Events here are board categories defined with domain experts that capture the trajectory of the treatment/medication. To illustrate the value of this approach, we analyze Reddit posts regarding medications for Opioid Use Disorder (OUD), a critical global health concern. To the best of our knowledge, this is the first attempt to define event categories for characterizing information-seeking in OUD social discourse. Guided by domain experts, we develop TREAT-ISE, a novel multilabel treatment information-seeking event dataset to analyze online discourse on an event-based framework. This dataset contains Reddit posts on information-seeking events related to recovery from OUD, where each post is annotated based on the type of events. We also establish a strong performance benchmark (77.4% F1 score) for the task by employing several machine learning and deep learning classifiers. Finally, we thoroughly investigate the performance and errors of ChatGPT on this task, providing valuable insights into the LLM's capabilities and ongoing characterization efforts.