 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaPlate: Counterfactual-Guided RAG-LLM Tool for Personalized Food Recommendation and Hyperglycemia Prevention
Jun 08, 2026Postprandial hyperglycemia is a key risk factor for metabolic disorders; however, existing dietary guidance is often static, impractical, and insufficiently personalized, providing recommendations that are difficult to follow or not impactful. While recent advances leverage continuous glucose monitoring (CGM) and machine learning to predict glycemic responses, these approaches are largely predictive and lack actionable guidance. Moreover, recommendation systems are often misaligned with user goals and require extensive input. We present MetaPlate, a counterfactual explanation (CF) guided, context-aware decision-support framework that generates personalized meal recommendations to mitigate postprandial glucose excursions in healthy adults. MetaPlate integrates multimodal data, including CGM readings, wearable-derived physiological signals, and user-provided meal inputs from $25$ individuals to model pre-meal context. A machine learning model predicts glucose response, while a CF optimization module adjusts meal composition modifying macronutrient amounts to maintain glucose levels within a target range ($\leq 140$ mg/dL). An LLM-based retrieval-augmented generation (RAG) layer enhances interpretability by producing human-readable recommendations using constrained search of the USDA food database. We evaluate MetaPlate via a structured expert-in-the-loop assessment with registered dietitians (RDs), comparing performance before and after prompt refinement. Results show improvements in meal realism, portion suitability, and recommendation likelihood, with expert feedback indicating a shift from clinically implausible outputs to actionable, contextually appropriate recommendations. Our findings emphasize the importance of domain knowledge and structured constraints in LLM-driven systems and highlight the potential of MetaPlate as a real-time personalized dietary decision-support tool.
GUIDE: Reinforcement Learning for Behavioral Action Support in Type 1 Diabetes
Apr 01, 2026Type 1 Diabetes (T1D) management requires continuous adjustment of insulin and lifestyle behaviors to maintain blood glucose within a safe target range. Although automated insulin delivery (AID) systems have improved glycemic outcomes, many patients still fail to achieve recommended clinical targets, warranting new approaches to improve glucose control in patients with T1D. While reinforcement learning (RL) has been utilized as a promising approach, current RL-based methods focus primarily on insulin-only treatment and do not provide behavioral recommendations for glucose control. To address this gap, we propose GUIDE, an RL-based decision-support framework designed to complement AID technologies by providing behavioral recommendations to prevent abnormal glucose events. GUIDE generates structured actions defined by intervention type, magnitude, and timing, including bolus insulin administration and carbohydrate intake events. GUIDE integrates a patient-specific glucose level predictor trained on real-world continuous glucose monitoring data and supports both offline and online RL algorithms within a unified environment. We evaluate both off-policy and on-policy methods across 25 individuals with T1D using standardized glycemic metrics. Among the evaluated approaches, the CQL-BC algorithm demonstrates the highest average time-in-range, reaching 85.49% while maintaining low hypoglycemia exposures. Behavioral similarity analysis further indicates that the learned CQL-BC policy preserves key structural characteristics of patient action patterns, achieving a mean cosine similarity of 0.87 $\pm$ 0.09 across subjects. These findings suggest that conservative offline RL with a structured behavioral action space can provide clinically meaningful and behaviorally plausible decision support for personalized diabetes management.
Gated Adaptation for Continual Learning in Human Activity Recognition
Mar 08, 2026Wearable sensors in Internet of Things (IoT) ecosystems increasingly support applications such as remote health monitoring, elderly care, and smart home automation, all of which rely on robust human activity recognition (HAR). Continual learning systems must balance plasticity (learning new tasks) with stability (retaining prior knowledge), yet AI models often exhibit catastrophic forgetting, where learning new tasks degrades performance on earlier ones. This challenge is especially acute in domain-incremental HAR, where on-device models must adapt to new subjects with distinct movement patterns while maintaining accuracy on prior subjects without transmitting sensitive data to the cloud. We propose a parameter-efficient continual learning framework based on channel-wise gated modulation of frozen pretrained representations. Our key insight is that adaptation should operate through feature selection rather than feature generation: by restricting learned transformations to diagonal scaling of existing features, we preserve the geometry of pretrained representations while enabling subject-specific modulation. We provide a theoretical analysis showing that gating implements a bounded diagonal operator that limits representational drift compared to unconstrained linear transformations. Empirically, freezing the backbone substantially reduces forgetting, and lightweight gates restore lost adaptation capacity, achieving stability and plasticity simultaneously. On PAMAP2 with 8 sequential subjects, our approach reduces forgetting from 39.7% to 16.2% and improves final accuracy from 56.7% to 77.7%, while training less than 2% of parameters. Our method matches or exceeds standard continual learning baselines without replay buffers or task-specific regularization, confirming that structured diagonal operators are effective and efficient under distribution shift.
Counterfactual Modeling with Fine-Tuned LLMs for Health Intervention Design and Sensor Data Augmentation
Jan 21, 2026Counterfactual explanations (CFEs) provide human-centric interpretability by identifying the minimal, actionable changes required to alter a machine learning model's prediction. Therefore, CFs can be used as (i) interventions for abnormality prevention and (ii) augmented data for training robust models. We conduct a comprehensive evaluation of CF generation using large language models (LLMs), including GPT-4 (zero-shot and few-shot) and two open-source models-BioMistral-7B and LLaMA-3.1-8B, in both pretrained and fine-tuned configurations. Using the multimodal AI-READI clinical dataset, we assess CFs across three dimensions: intervention quality, feature diversity, and augmentation effectiveness. Fine-tuned LLMs, particularly LLaMA-3.1-8B, produce CFs with high plausibility (up to 99%), strong validity (up to 0.99), and realistic, behaviorally modifiable feature adjustments. When used for data augmentation under controlled label-scarcity settings, LLM-generated CFs substantially restore classifier performance, yielding an average 20% F1 recovery across three scarcity scenarios. Compared with optimization-based baselines such as DiCE, CFNOW, and NICE, LLMs offer a flexible, model-agnostic approach that generates more clinically actionable and semantically coherent counterfactuals. Overall, this work demonstrates the promise of LLM-driven counterfactuals for both interpretable intervention design and data-efficient model training in sensor-based digital health. Impact: SenseCF fine-tunes an LLM to generate valid, representative counterfactual explanations and supplement minority class in an imbalanced dataset for improving model training and boosting model robustness and predictive performance
Guiding Diffusion with Deep Geometric Moments: Balancing Fidelity and Variation
May 18, 2025Text-to-image generation models have achieved remarkable capabilities in synthesizing images, but often struggle to provide fine-grained control over the output. Existing guidance approaches, such as segmentation maps and depth maps, introduce spatial rigidity that restricts the inherent diversity of diffusion models. In this work, we introduce Deep Geometric Moments (DGM) as a novel form of guidance that encapsulates the subject's visual features and nuances through a learned geometric prior. DGMs focus specifically on the subject itself compared to DINO or CLIP features, which suffer from overemphasis on global image features or semantics. Unlike ResNets, which are sensitive to pixel-wise perturbations, DGMs rely on robust geometric moments. Our experiments demonstrate that DGM effectively balance control and diversity in diffusion-based image generation, allowing a flexible control mechanism for steering the diffusion process.
GlyTwin: Digital Twin for Glucose Control in Type 1 Diabetes Through Optimal Behavioral Modifications Using Patient-Centric Counterfactuals
Apr 14, 2025



Frequent and long-term exposure to hyperglycemia (i.e., high blood glucose) increases the risk of chronic complications such as neuropathy, nephropathy, and cardiovascular disease. Current technologies like continuous subcutaneous insulin infusion (CSII) and continuous glucose monitoring (CGM) primarily model specific aspects of glycemic control-like hypoglycemia prediction or insulin delivery. Similarly, most digital twin approaches in diabetes management simulate only physiological processes. These systems lack the ability to offer alternative treatment scenarios that support proactive behavioral interventions. To address this, we propose GlyTwin, a novel digital twin framework that uses counterfactual explanations to simulate optimal treatments for glucose regulation. Our approach helps patients and caregivers modify behaviors like carbohydrate intake and insulin dosing to avoid abnormal glucose events. GlyTwin generates behavioral treatment suggestions that proactively prevent hyperglycemia by recommending small adjustments to daily choices, reducing both frequency and duration of these events. Additionally, it incorporates stakeholder preferences into the intervention design, making recommendations patient-centric and tailored. We evaluate GlyTwin on AZT1D, a newly constructed dataset with longitudinal data from 21 type 1 diabetes (T1D) patients on automated insulin delivery systems over 26 days. Results show GlyTwin outperforms state-of-the-art counterfactual methods, generating 76.6% valid and 86% effective interventions. These findings demonstrate the promise of counterfactual-driven digital twins in delivering personalized healthcare.
Enhancing Metabolic Syndrome Prediction with Hybrid Data Balancing and Counterfactuals
Apr 09, 2025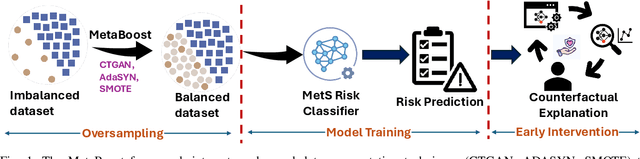

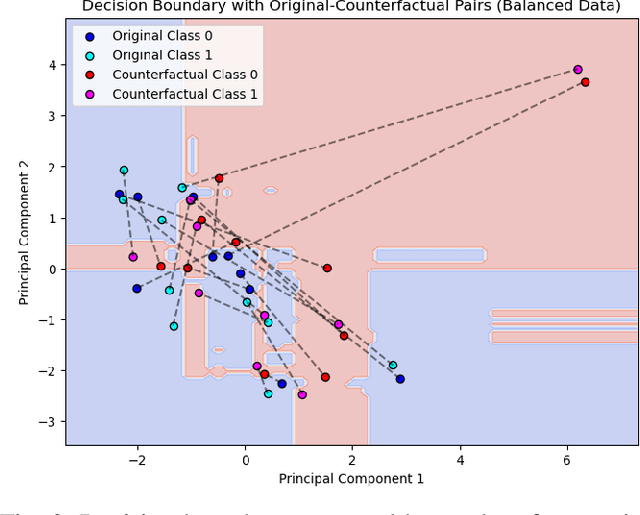

Metabolic Syndrome (MetS) is a cluster of interrelated risk factors that significantly increases the risk of cardiovascular diseases and type 2 diabetes. Despite its global prevalence, accurate prediction of MetS remains challenging due to issues such as class imbalance, data scarcity, and methodological inconsistencies in existing studies. In this paper, we address these challenges by systematically evaluating and optimizing machine learning (ML) models for MetS prediction, leveraging advanced data balancing techniques and counterfactual analysis. Multiple ML models, including XGBoost, Random Forest, TabNet, etc., were trained and compared under various data balancing techniques such as random oversampling (ROS), SMOTE, ADASYN, and CTGAN. Additionally, we introduce MetaBoost, a novel hybrid framework that integrates SMOTE, ADASYN, and CTGAN, optimizing synthetic data generation through weighted averaging and iterative weight tuning to enhance the model's performance (achieving a 1.14% accuracy improvement over individual balancing techniques). A comprehensive counterfactual analysis is conducted to quantify feature-level changes required to shift individuals from high-risk to low-risk categories. The results indicate that blood glucose (50.3%) and triglycerides (46.7%) were the most frequently modified features, highlighting their clinical significance in MetS risk reduction. Additionally, probabilistic analysis shows elevated blood glucose (85.5% likelihood) and triglycerides (74.9% posterior probability) as the strongest predictors. This study not only advances the methodological rigor of MetS prediction but also provides actionable insights for clinicians and researchers, highlighting the potential of ML in mitigating the public health burden of metabolic syndrome.
AIMI: Leveraging Future Knowledge and Personalization in Sparse Event Forecasting for Treatment Adherence
Mar 20, 2025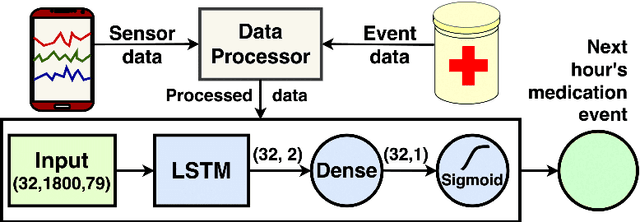

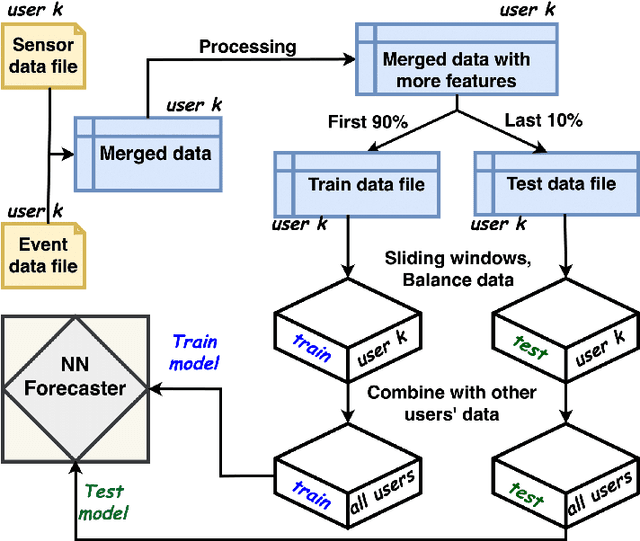

Adherence to prescribed treatments is crucial for individuals with chronic conditions to avoid costly or adverse health outcomes. For certain patient groups, intensive lifestyle interventions are vital for enhancing medication adherence. Accurate forecasting of treatment adherence can open pathways to developing an on-demand intervention tool, enabling timely and personalized support. With the increasing popularity of smartphones and wearables, it is now easier than ever to develop and deploy smart activity monitoring systems. However, effective forecasting systems for treatment adherence based on wearable sensors are still not widely available. We close this gap by proposing Adherence Forecasting and Intervention with Machine Intelligence (AIMI). AIMI is a knowledge-guided adherence forecasting system that leverages smartphone sensors and previous medication history to estimate the likelihood of forgetting to take a prescribed medication. A user study was conducted with 27 participants who took daily medications to manage their cardiovascular diseases. We designed and developed CNN and LSTM-based forecasting models with various combinations of input features and found that LSTM models can forecast medication adherence with an accuracy of 0.932 and an F-1 score of 0.936. Moreover, through a series of ablation studies involving convolutional and recurrent neural network architectures, we demonstrate that leveraging known knowledge about future and personalized training enhances the accuracy of medication adherence forecasting. Code available: https://github.com/ab9mamun/AIMI.
GlucoLens: Explainable Postprandial Blood Glucose Prediction from Diet and Physical Activity
Mar 05, 2025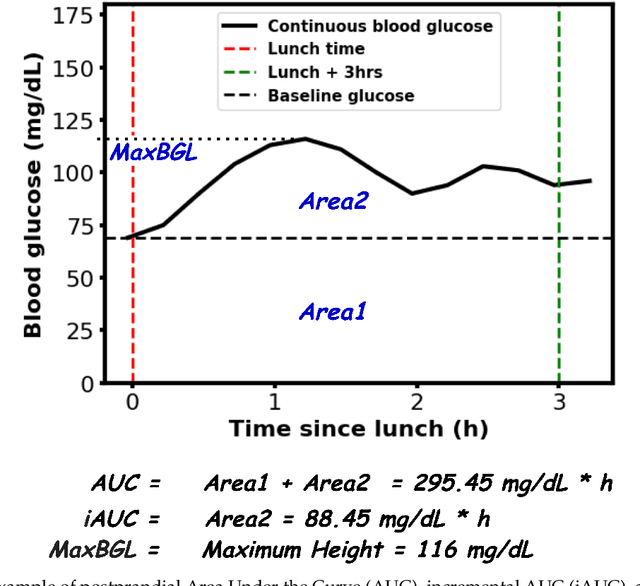
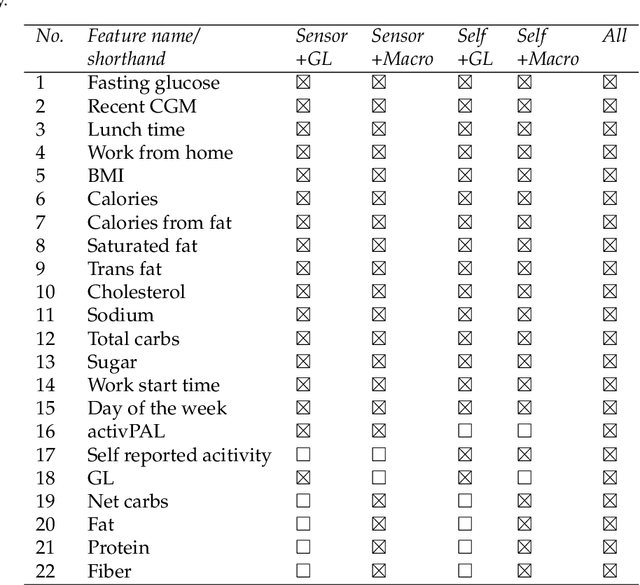
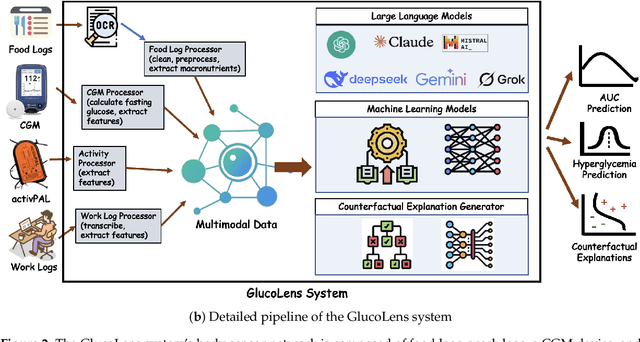

Postprandial hyperglycemia, marked by the blood glucose level exceeding the normal range after meals, is a critical indicator of progression toward type 2 diabetes in prediabetic and healthy individuals. A key metric for understanding blood glucose dynamics after eating is the postprandial area under the curve (PAUC). Predicting PAUC in advance based on a person's diet and activity level and explaining what affects postprandial blood glucose could allow an individual to adjust their lifestyle accordingly to maintain normal glucose levels. In this paper, we propose GlucoLens, an explainable machine learning approach to predict PAUC and hyperglycemia from diet, activity, and recent glucose patterns. We conducted a five-week user study with 10 full-time working individuals to develop and evaluate the computational model. Our machine learning model takes multimodal data including fasting glucose, recent glucose, recent activity, and macronutrient amounts, and provides an interpretable prediction of the postprandial glucose pattern. Our extensive analyses of the collected data revealed that the trained model achieves a normalized root mean squared error (NRMSE) of 0.123. On average, GlucoLense with a Random Forest backbone provides a 16% better result than the baseline models. Additionally, GlucoLens predicts hyperglycemia with an accuracy of 74% and recommends different options to help avoid hyperglycemia through diverse counterfactual explanations. Code available: https://github.com/ab9mamun/GlucoLens.
NutriGen: Personalized Meal Plan Generator Leveraging Large Language Models to Enhance Dietary and Nutritional Adherence
Feb 28, 2025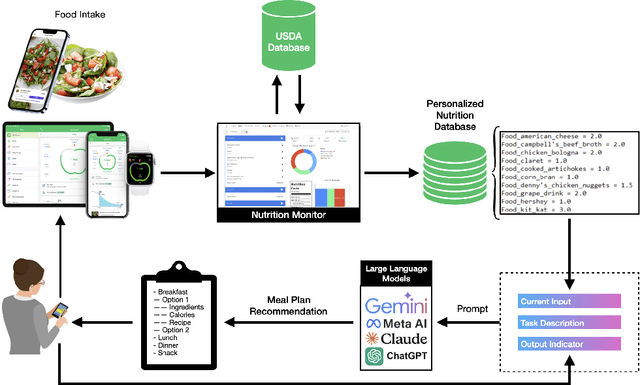
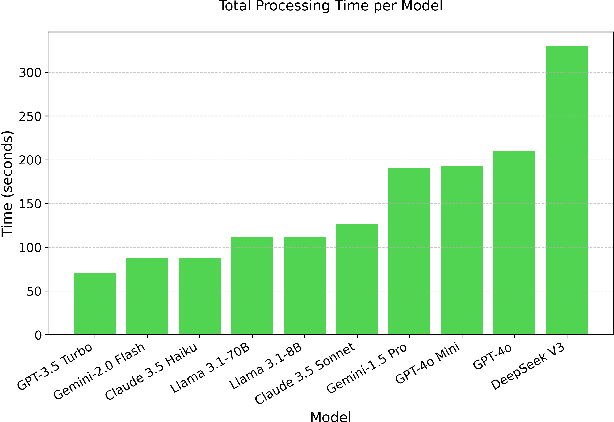
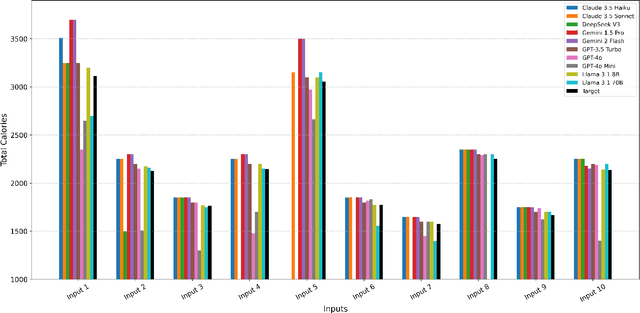
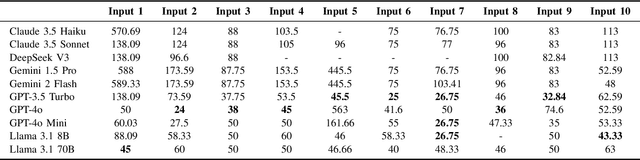
Maintaining a balanced diet is essential for overall health, yet many individuals struggle with meal planning due to nutritional complexity, time constraints, and lack of dietary knowledge. Personalized food recommendations can help address these challenges by tailoring meal plans to individual preferences, habits, and dietary restrictions. However, existing dietary recommendation systems often lack adaptability, fail to consider real-world constraints such as food ingredient availability, and require extensive user input, making them impractical for sustainable and scalable daily use. To address these limitations, we introduce NutriGen, a framework based on large language models (LLM) designed to generate personalized meal plans that align with user-defined dietary preferences and constraints. By building a personalized nutrition database and leveraging prompt engineering, our approach enables LLMs to incorporate reliable nutritional references like the USDA nutrition database while maintaining flexibility and ease-of-use. We demonstrate that LLMs have strong potential in generating accurate and user-friendly food recommendations, addressing key limitations in existing dietary recommendation systems by providing structured, practical, and scalable meal plans. Our evaluation shows that Llama 3.1 8B and GPT-3.5 Turbo achieve the lowest percentage errors of 1.55\% and 3.68\%, respectively, producing meal plans that closely align with user-defined caloric targets while minimizing deviation and improving precision. Additionally, we compared the performance of DeepSeek V3 against several established models to evaluate its potential in personalized nutrition planning.