 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIMI: Leveraging Future Knowledge and Personalization in Sparse Event Forecasting for Treatment Adherence
Mar 20, 2025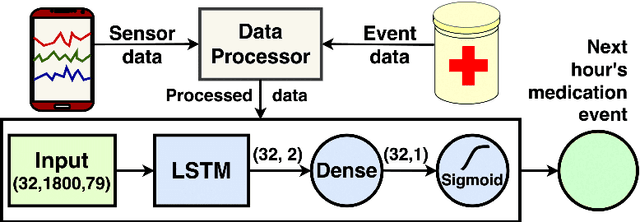

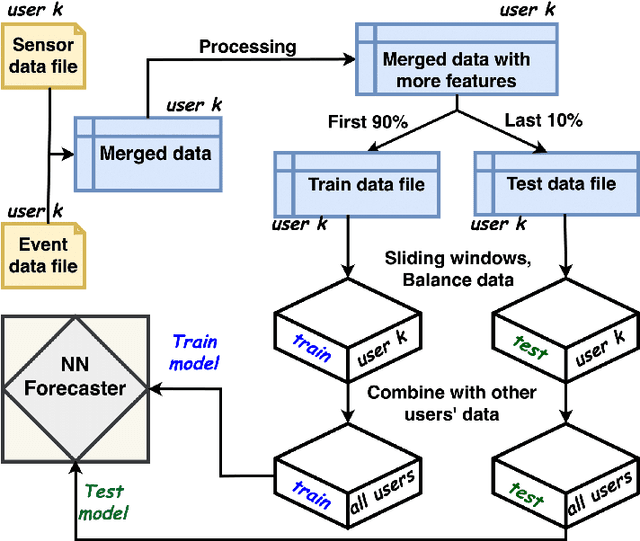

Adherence to prescribed treatments is crucial for individuals with chronic conditions to avoid costly or adverse health outcomes. For certain patient groups, intensive lifestyle interventions are vital for enhancing medication adherence. Accurate forecasting of treatment adherence can open pathways to developing an on-demand intervention tool, enabling timely and personalized support. With the increasing popularity of smartphones and wearables, it is now easier than ever to develop and deploy smart activity monitoring systems. However, effective forecasting systems for treatment adherence based on wearable sensors are still not widely available. We close this gap by proposing Adherence Forecasting and Intervention with Machine Intelligence (AIMI). AIMI is a knowledge-guided adherence forecasting system that leverages smartphone sensors and previous medication history to estimate the likelihood of forgetting to take a prescribed medication. A user study was conducted with 27 participants who took daily medications to manage their cardiovascular diseases. We designed and developed CNN and LSTM-based forecasting models with various combinations of input features and found that LSTM models can forecast medication adherence with an accuracy of 0.932 and an F-1 score of 0.936. Moreover, through a series of ablation studies involving convolutional and recurrent neural network architectures, we demonstrate that leveraging known knowledge about future and personalized training enhances the accuracy of medication adherence forecasting. Code available: https://github.com/ab9mamun/AIMI.
Domain Adaptation Under Behavioral and Temporal Shifts for Natural Time Series Mobile Activity Recognition
Jul 10, 2022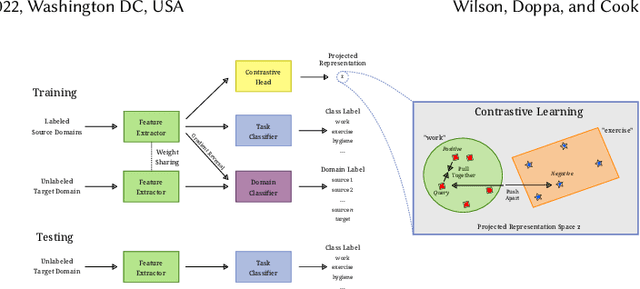
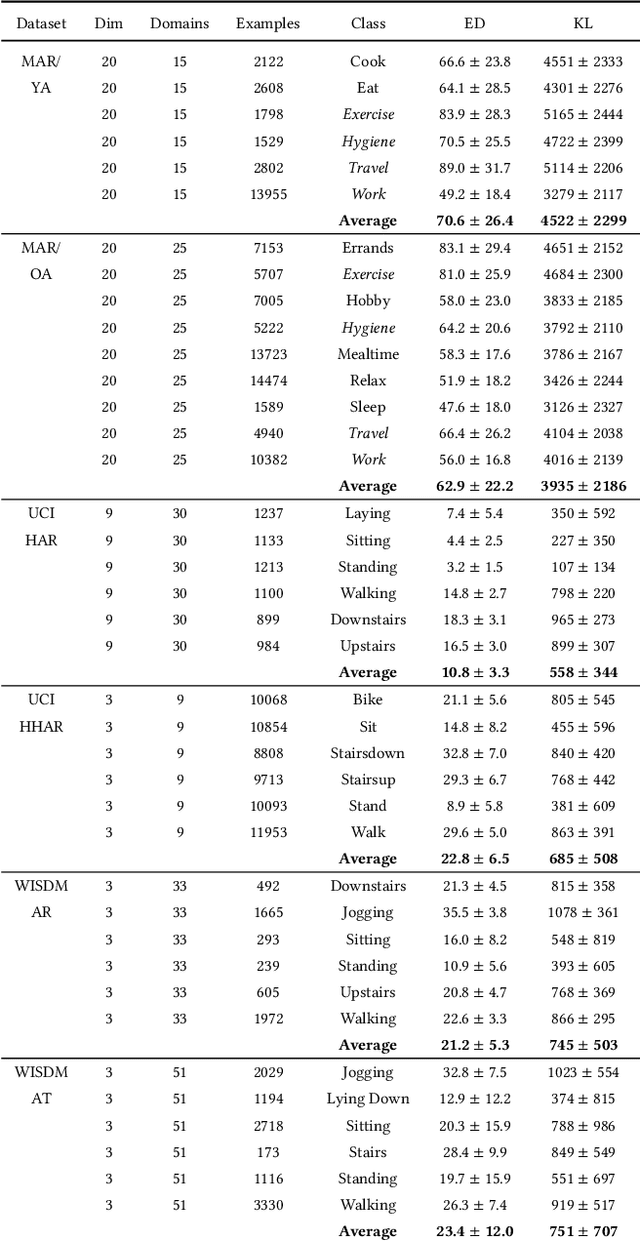
Increasingly, human behavior is captured on mobile devices, leading to an increased interest in automated human activity recognition. However, existing datasets typically consist of scripted movements. Our long-term goal is to perform mobile activity recognition in natural settings. We collect a dataset to support this goal with activity categories that are relevant for downstream tasks such as health monitoring and intervention. Because of the large variations present in human behavior, we collect data from many participants across two different age groups. Because human behavior can change over time, we also collect data from participants over a month's time to capture the temporal drift. We hypothesize that mobile activity recognition can benefit from unsupervised domain adaptation algorithms. To address this need and test this hypothesis, we analyze the performance of domain adaptation across people and across time. We then enhance unsupervised domain adaptation with contrastive learning and with weak supervision when label proportions are available. The dataset is available at https://github.com/WSU-CASAS/smartwatch-data
Mimic: An adaptive algorithm for multivariate time series classification
Nov 08, 2021
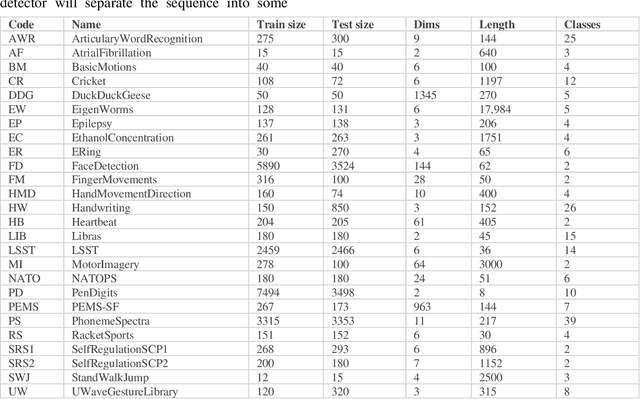
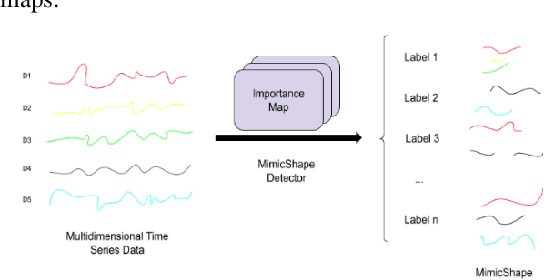

Time series data are valuable but are often inscrutable. Gaining trust in time series classifiers for finance, healthcare, and other critical applications may rely on creating interpretable models. Researchers have previously been forced to decide between interpretable methods that lack predictive power and deep learning methods that lack transparency. In this paper, we propose a novel Mimic algorithm that retains the predictive accuracy of the strongest classifiers while introducing interpretability. Mimic mirrors the learning method of an existing multivariate time series classifier while simultaneously producing a visual representation that enhances user understanding of the learned model. Experiments on 26 time series datasets support Mimic's ability to imitate a variety of time series classifiers visually and accurately.
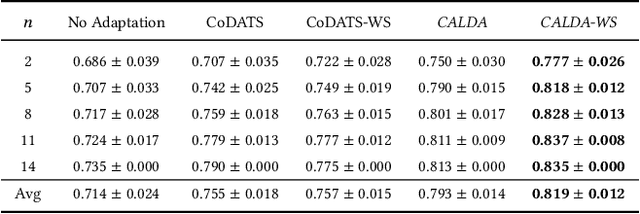
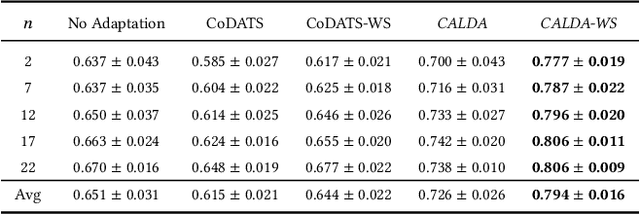
CALDA: Improving Multi-Source Time Series Domain Adaptation with Contrastive Adversarial Learning
Sep 30, 2021
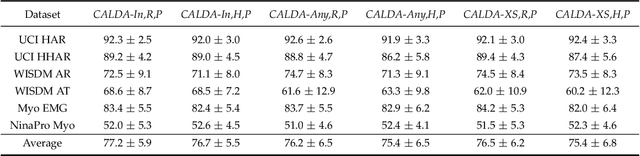
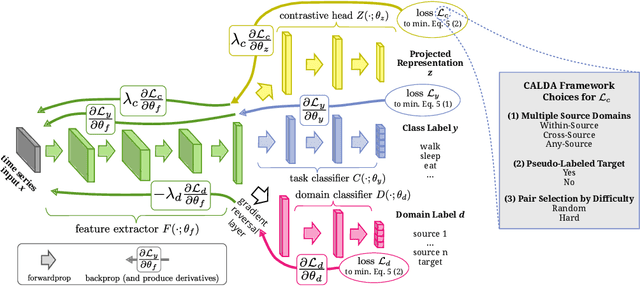
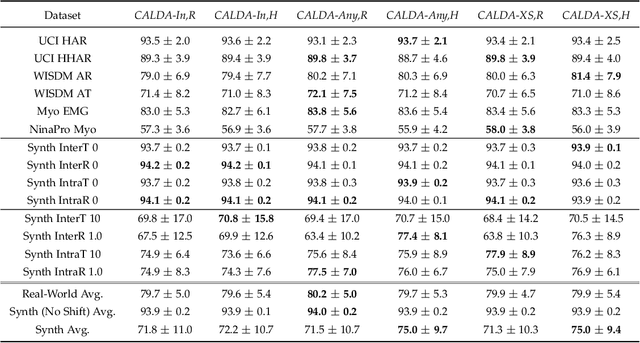
Unsupervised domain adaptation (UDA) provides a strategy for improving machine learning performance in data-rich (target) domains where ground truth labels are inaccessible but can be found in related (source) domains. In cases where meta-domain information such as label distributions is available, weak supervision can further boost performance. We propose a novel framework, CALDA, to tackle these two problems. CALDA synergistically combines the principles of contrastive learning and adversarial learning to robustly support multi-source UDA (MS-UDA) for time series data. Similar to prior methods, CALDA utilizes adversarial learning to align source and target feature representations. Unlike prior approaches, CALDA additionally leverages cross-source label information across domains. CALDA pulls examples with the same label close to each other, while pushing apart examples with different labels, reshaping the space through contrastive learning. Unlike prior contrastive adaptation methods, CALDA requires neither data augmentation nor pseudo labeling, which may be more challenging for time series. We empirically validate our proposed approach. Based on results from human activity recognition, electromyography, and synthetic datasets, we find utilizing cross-source information improves performance over prior time series and contrastive methods. Weak supervision further improves performance, even in the presence of noise, allowing CALDA to offer generalizable strategies for MS-UDA. Code is available at: https://github.com/floft/calda
Transfer Learning for Activity Recognition in Mobile Health
Jul 12, 2020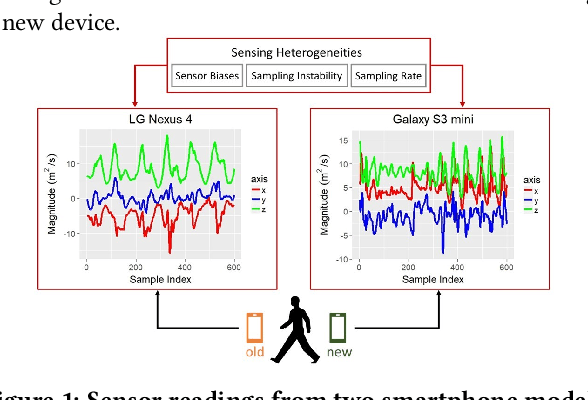
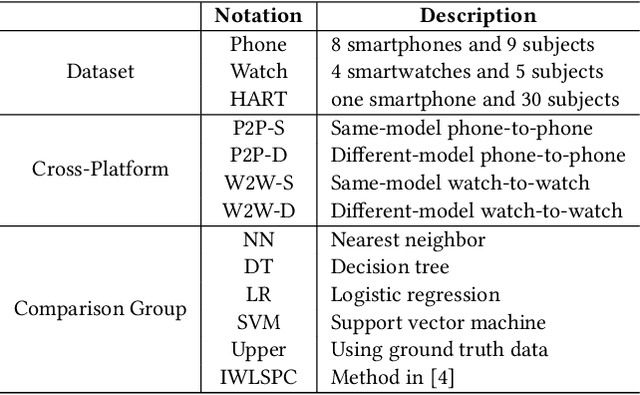
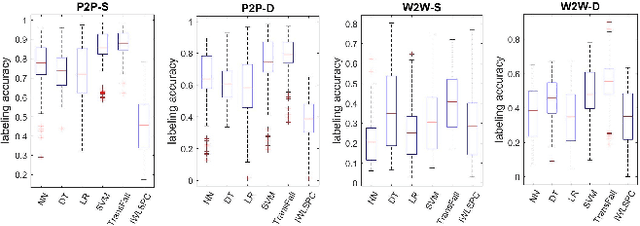
While activity recognition from inertial sensors holds potential for mobile health, differences in sensing platforms and user movement patterns cause performance degradation. Aiming to address these challenges, we propose a transfer learning framework, TransFall, for sensor-based activity recognition. TransFall's design contains a two-tier data transformation, a label estimation layer, and a model generation layer to recognize activities for the new scenario. We validate TransFall analytically and empirically.
Multi-Source Deep Domain Adaptation with Weak Supervision for Time-Series Sensor Data
May 22, 2020


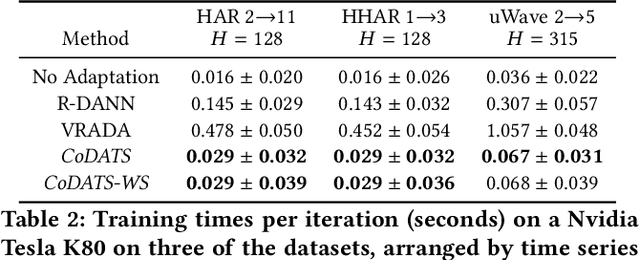
Domain adaptation (DA) offers a valuable means to reuse data and models for new problem domains. However, robust techniques have not yet been considered for time series data with varying amounts of data availability. In this paper, we make three main contributions to fill this gap. First, we propose a novel Convolutional deep Domain Adaptation model for Time Series data (CoDATS) that significantly improves accuracy and training time over state-of-the-art DA strategies on real-world sensor data benchmarks. By utilizing data from multiple source domains, we increase the usefulness of CoDATS to further improve accuracy over prior single-source methods, particularly on complex time series datasets that have high variability between domains. Second, we propose a novel Domain Adaptation with Weak Supervision (DA-WS) method by utilizing weak supervision in the form of target-domain label distributions, which may be easier to collect than additional data labels. Third, we perform comprehensive experiments on diverse real-world datasets to evaluate the effectiveness of our domain adaptation and weak supervision methods. Results show that CoDATS for single-source DA significantly improves over the state-of-the-art methods, and we achieve additional improvements in accuracy using data from multiple source domains and weakly supervised signals. Code is available at: https://github.com/floft/codats
Multi-Purposing Domain Adaptation Discriminators for Pseudo Labeling Confidence
Jul 17, 2019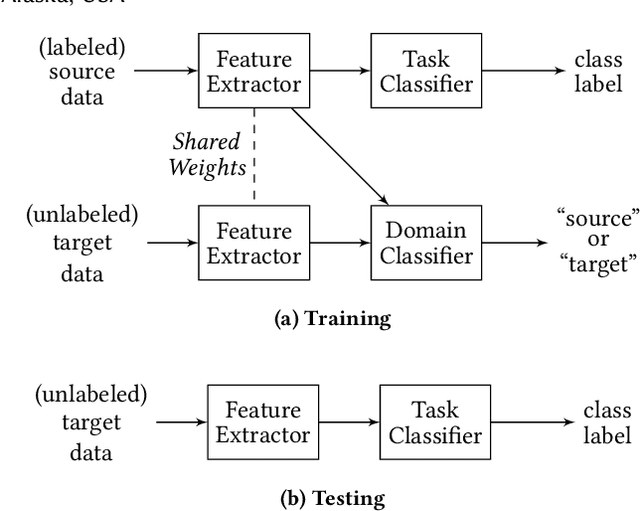
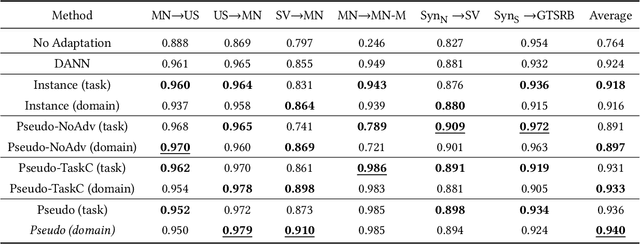
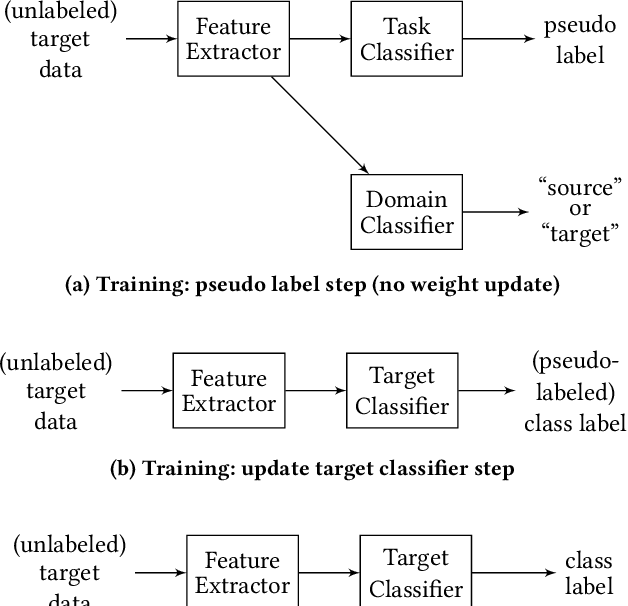
Often domain adaptation is performed using a discriminator (domain classifier) to learn domain-invariant feature representations so that a classifier trained on labeled source data will generalize well to unlabeled target data. A line of research stemming from semi-supervised learning uses pseudo labeling to directly generate "pseudo labels" for the unlabeled target data and trains a classifier on the now-labeled target data, where the samples are selected or weighted based on some measure of confidence. In this paper, we propose multi-purposing the discriminator to not only aid in producing domain-invariant representations but also to provide pseudo labeling confidence.
Activity2Vec: Learning ADL Embeddings from Sensor Data with a Sequence-to-Sequence Model
Jul 12, 2019


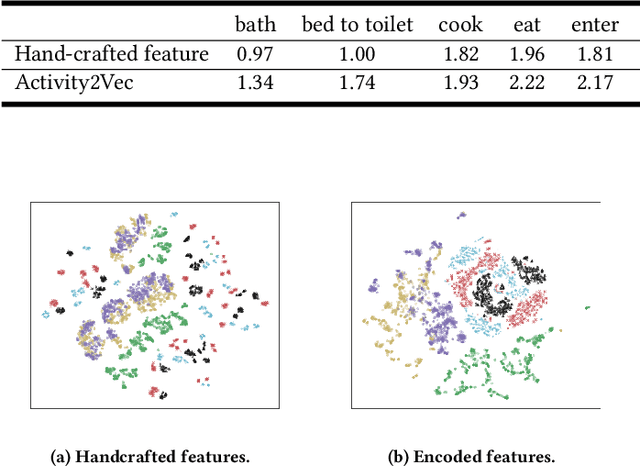
Recognizing activities of daily living (ADLs) plays an essential role in analyzing human health and behavior. The widespread availability of sensors implanted in homes, smartphones, and smart watches have engendered collection of big datasets that reflect human behavior. To obtain a machine learning model based on these data,researchers have developed multiple feature extraction methods. In this study, we investigate a method for automatically extracting universal and meaningful features that are applicable across similar time series-based learning tasks such as activity recognition and fall detection. We propose creating a sequence-to-sequence (seq2seq) model to perform this feature learning. Beside avoiding feature engineering, the meaningful features learned by the seq2seq model can also be utilized for semi-supervised learning. We evaluate both of these benefits on datasets collected from wearable and ambient sensors.
Adversarial Transfer Learning
Dec 06, 2018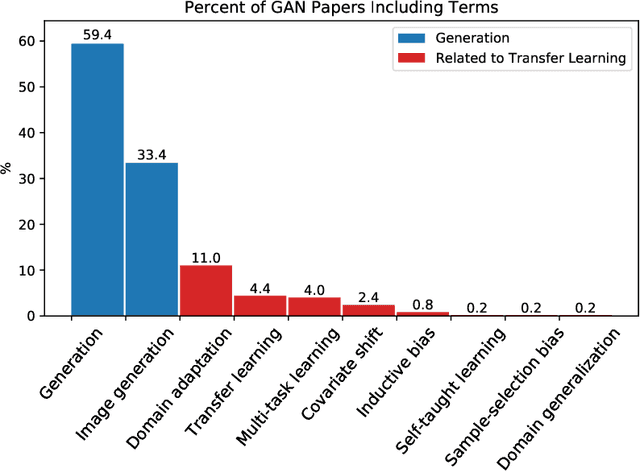


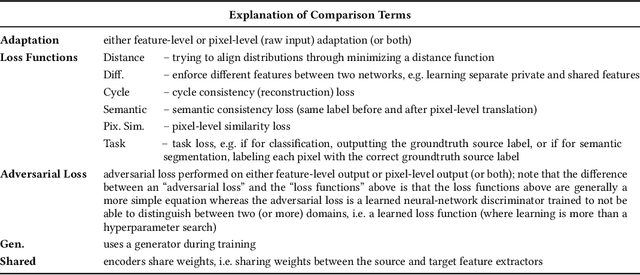
There is a recent large and growing interest in generative adversarial networks (GANs), which offer powerful features for generative modeling, density estimation, and energy function learning. GANs are difficult to train and evaluate but are capable of creating amazingly realistic, though synthetic, image data. Ideas stemming from GANs such as adversarial losses are creating research opportunities for other challenges such as domain adaptation. In this paper, we look at the field of GANs with emphasis on these areas of emerging research. To provide background for adversarial techniques, we survey the field of GANs, looking at the original formulation, training variants, evaluation methods, and extensions. Then we survey recent work on transfer learning, focusing on comparing different adversarial domain adaptation methods. Finally, we take a look forward to identify open research directions for GANs and domain adaptation, including some promising applications such as sensor-based human behavior modeling.