 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModels Got Talent: Identifying High Performing Wearable Human Activity Recognition Models Without Training
Nov 19, 2025A promising alternative to the computationally expensive Neural Architecture Search (NAS) involves the development of Zero Cost Proxies (ZCPs), which correlate well with trained performance, but can be computed through a single forward/backward pass on a randomly sampled batch of data. In this paper, we investigate the effectiveness of ZCPs for HAR on six benchmark datasets, and demonstrate that they discover network architectures that obtain within 5% of performance attained by full-scale training involving 1500 randomly sampled architectures. This results in substantial computational savings as high-performing architectures can be discovered with minimal training. Our experiments not only introduce ZCPs to sensor-based HAR, but also demonstrate that they are robust to data noise, further showcasing their suitability for practical scenarios.
Thou Shalt Not Prompt: Zero-Shot Human Activity Recognition in Smart Homes via Language Modeling of Sensor Data & Activities
Jul 29, 2025Developing zero-shot human activity recognition (HAR) methods is a critical direction in smart home research -- considering its impact on making HAR systems work across smart homes having diverse sensing modalities, layouts, and activities of interest. The state-of-the-art solutions along this direction are based on generating natural language descriptions of the sensor data and feeding it via a carefully crafted prompt to the LLM to perform classification. Despite their performance guarantees, such ``prompt-the-LLM'' approaches carry several risks, including privacy invasion, reliance on an external service, and inconsistent predictions due to version changes, making a case for alternative zero-shot HAR methods that do not require prompting the LLMs. In this paper, we propose one such solution that models sensor data and activities using natural language, leveraging its embeddings to perform zero-shot classification and thereby bypassing the need to prompt the LLMs for activity predictions. The impact of our work lies in presenting a detailed case study on six datasets, highlighting how language modeling can bolster HAR systems in zero-shot recognition.
Past, Present, and Future of Sensor-based Human Activity Recognition using Wearables: A Surveying Tutorial on a Still Challenging Task
Nov 11, 2024In the many years since the inception of wearable sensor-based Human Activity Recognition (HAR), a wide variety of methods have been introduced and evaluated for their ability to recognize activities. Substantial gains have been made since the days of hand-crafting heuristics as features, yet, progress has seemingly stalled on many popular benchmarks, with performance falling short of what may be considered 'sufficient'-- despite the increase in computational power and scale of sensor data, as well as rising complexity in techniques being employed. The HAR community approaches a new paradigm shift, this time incorporating world knowledge from foundational models. In this paper, we take stock of sensor-based HAR -- surveying it from its beginnings to the current state of the field, and charting its future. This is accompanied by a hands-on tutorial, through which we guide practitioners in developing HAR systems for real-world application scenarios. We provide a compendium for novices and experts alike, of methods that aim at finally solving the activity recognition problem.
Limitations in Employing Natural Language Supervision for Sensor-Based Human Activity Recognition -- And Ways to Overcome Them
Aug 21, 2024Cross-modal contrastive pre-training between natural language and other modalities, e.g., vision and audio, has demonstrated astonishing performance and effectiveness across a diverse variety of tasks and domains. In this paper, we investigate whether such natural language supervision can be used for wearable sensor based Human Activity Recognition (HAR), and discover that-surprisingly-it performs substantially worse than standard end-to-end training and self-supervision. We identify the primary causes for this as: sensor heterogeneity and the lack of rich, diverse text descriptions of activities. To mitigate their impact, we also develop strategies and assess their effectiveness through an extensive experimental evaluation. These strategies lead to significant increases in activity recognition, bringing performance closer to supervised and self-supervised training, while also enabling the recognition of unseen activities and cross modal retrieval of videos. Overall, our work paves the way for better sensor-language learning, ultimately leading to the development of foundational models for HAR using wearables.
Maintenance Required: Updating and Extending Bootstrapped Human Activity Recognition Systems for Smart Homes
Jun 20, 2024



Developing human activity recognition (HAR) systems for smart homes is not straightforward due to varied layouts of the homes and their personalized settings, as well as idiosyncratic behaviors of residents. As such, off-the-shelf HAR systems are effective in limited capacity for an individual home, and HAR systems often need to be derived "from scratch", which comes with substantial efforts and often is burdensome to the resident. Previous work has successfully targeted the initial phase. At the end of this initial phase, we identify seed points. We build on bootstrapped HAR systems and introduce an effective updating and extension procedure for continuous improvement of HAR systems with the aim of keeping up with ever changing life circumstances. Our method makes use of the seed points identified at the end of the initial bootstrapping phase. A contrastive learning framework is trained using these seed points and labels obtained for the same. This model is then used to improve the segmentation accuracy of the identified prominent activities. Improvements in the activity recognition system through this procedure help model the majority of the routine activities in the smart home. We demonstrate the effectiveness of our procedure through experiments on the CASAS datasets that show the practical value of our approach.
Game of LLMs: Discovering Structural Constructs in Activities using Large Language Models
Jun 19, 2024Human Activity Recognition is a time-series analysis problem. A popular analysis procedure used by the community assumes an optimal window length to design recognition pipelines. However, in the scenario of smart homes, where activities are of varying duration and frequency, the assumption of a constant sized window does not hold. Additionally, previous works have shown these activities to be made up of building blocks. We focus on identifying these underlying building blocks--structural constructs, with the use of large language models. Identifying these constructs can be beneficial especially in recognizing short-duration and infrequent activities. We also propose the development of an activity recognition procedure that uses these building blocks to model activities, thus helping the downstream task of activity monitoring in smart homes.
Large Language Models Memorize Sensor Datasets! Implications on Human Activity Recognition Research
Jun 09, 2024



The astonishing success of Large Language Models (LLMs) in Natural Language Processing (NLP) has spurred their use in many application domains beyond text analysis, including wearable sensor-based Human Activity Recognition (HAR). In such scenarios, often sensor data are directly fed into an LLM along with text instructions for the model to perform activity classification. Seemingly remarkable results have been reported for such LLM-based HAR systems when they are evaluated on standard benchmarks from the field. Yet, we argue, care has to be taken when evaluating LLM-based HAR systems in such a traditional way. Most contemporary LLMs are trained on virtually the entire (accessible) internet -- potentially including standard HAR datasets. With that, it is not unlikely that LLMs actually had access to the test data used in such benchmark experiments.The resulting contamination of training data would render these experimental evaluations meaningless. In this paper we investigate whether LLMs indeed have had access to standard HAR datasets during training. We apply memorization tests to LLMs, which involves instructing the models to extend given snippets of data. When comparing the LLM-generated output to the original data we found a non-negligible amount of matches which suggests that the LLM under investigation seems to indeed have seen wearable sensor data from the benchmark datasets during training. For the Daphnet dataset in particular, GPT-4 is able to reproduce blocks of sensor readings. We report on our investigations and discuss potential implications on HAR research, especially with regards to reporting results on experimental evaluation
Layout Agnostic Human Activity Recognition in Smart Homes through Textual Descriptions Of Sensor Triggers (TDOST)
May 20, 2024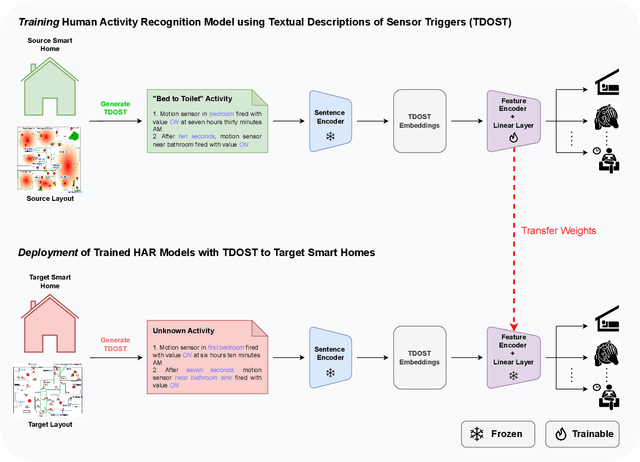
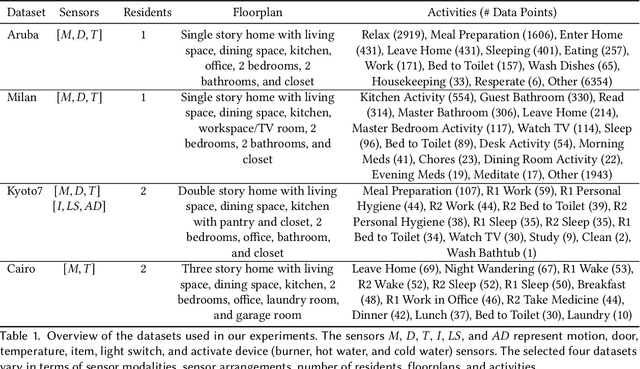
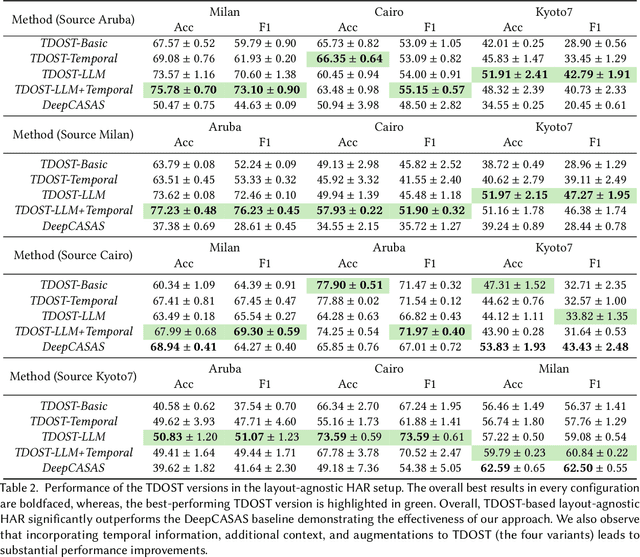
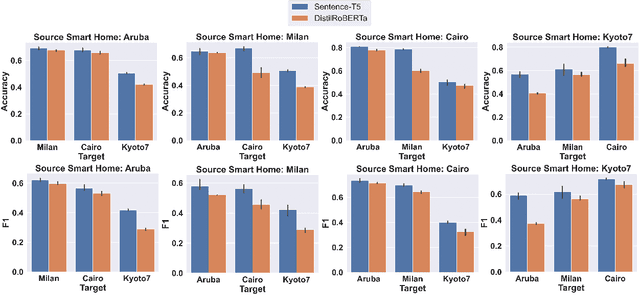
Human activity recognition (HAR) using ambient sensors in smart homes has numerous applications for human healthcare and wellness. However, building general-purpose HAR models that can be deployed to new smart home environments requires a significant amount of annotated sensor data and training overhead. Most smart homes vary significantly in their layouts, i.e., floor plans and the specifics of sensors embedded, resulting in low generalizability of HAR models trained for specific homes. We address this limitation by introducing a novel, layout-agnostic modeling approach for HAR systems in smart homes that utilizes the transferrable representational capacity of natural language descriptions of raw sensor data. To this end, we generate Textual Descriptions Of Sensor Triggers (TDOST) that encapsulate the surrounding trigger conditions and provide cues for underlying activities to the activity recognition models. Leveraging textual embeddings, rather than raw sensor data, we create activity recognition systems that predict standard activities across homes without either (re-)training or adaptation on target homes. Through an extensive evaluation, we demonstrate the effectiveness of TDOST-based models in unseen smart homes through experiments on benchmarked CASAS datasets. Furthermore, we conduct a detailed analysis of how the individual components of our approach affect downstream activity recognition performance.
Transfer Learning in Human Activity Recognition: A Survey
Jan 18, 2024



Sensor-based human activity recognition (HAR) has been an active research area, owing to its applications in smart environments, assisted living, fitness, healthcare, etc. Recently, deep learning based end-to-end training has resulted in state-of-the-art performance in domains such as computer vision and natural language, where large amounts of annotated data are available. However, large quantities of annotated data are not available for sensor-based HAR. Moreover, the real-world settings on which the HAR is performed differ in terms of sensor modalities, classification tasks, and target users. To address this problem, transfer learning has been employed extensively. In this survey, we focus on these transfer learning methods in the application domains of smart home and wearables-based HAR. In particular, we provide a problem-solution perspective by categorizing and presenting the works in terms of their contributions and the challenges they address. We also present an updated view of the state-of-the-art for both application domains. Based on our analysis of 205 papers, we highlight the gaps in the literature and provide a roadmap for addressing them. This survey provides a reference to the HAR community, by summarizing the existing works and providing a promising research agenda.
Cross-Domain HAR: Few Shot Transfer Learning for Human Activity Recognition
Oct 22, 2023



The ubiquitous availability of smartphones and smartwatches with integrated inertial measurement units (IMUs) enables straightforward capturing of human activities. For specific applications of sensor based human activity recognition (HAR), however, logistical challenges and burgeoning costs render especially the ground truth annotation of such data a difficult endeavor, resulting in limited scale and diversity of datasets. Transfer learning, i.e., leveraging publicly available labeled datasets to first learn useful representations that can then be fine-tuned using limited amounts of labeled data from a target domain, can alleviate some of the performance issues of contemporary HAR systems. Yet they can fail when the differences between source and target conditions are too large and/ or only few samples from a target application domain are available, each of which are typical challenges in real-world human activity recognition scenarios. In this paper, we present an approach for economic use of publicly available labeled HAR datasets for effective transfer learning. We introduce a novel transfer learning framework, Cross-Domain HAR, which follows the teacher-student self-training paradigm to more effectively recognize activities with very limited label information. It bridges conceptual gaps between source and target domains, including sensor locations and type of activities. Through our extensive experimental evaluation on a range of benchmark datasets, we demonstrate the effectiveness of our approach for practically relevant few shot activity recognition scenarios. We also present a detailed analysis into how the individual components of our framework affect downstream performance.