 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentSense: Virtual Sensor Data Generation Using LLM Agents in Simulated Home Environments
Jun 16, 2025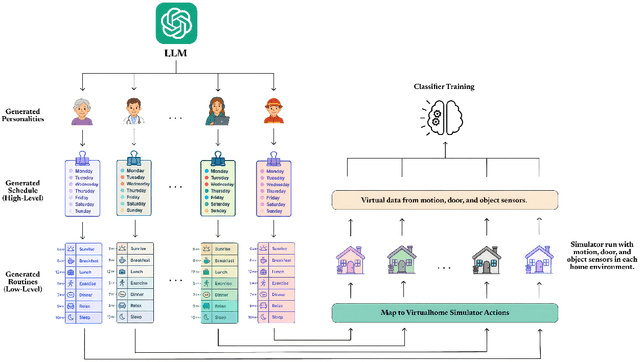
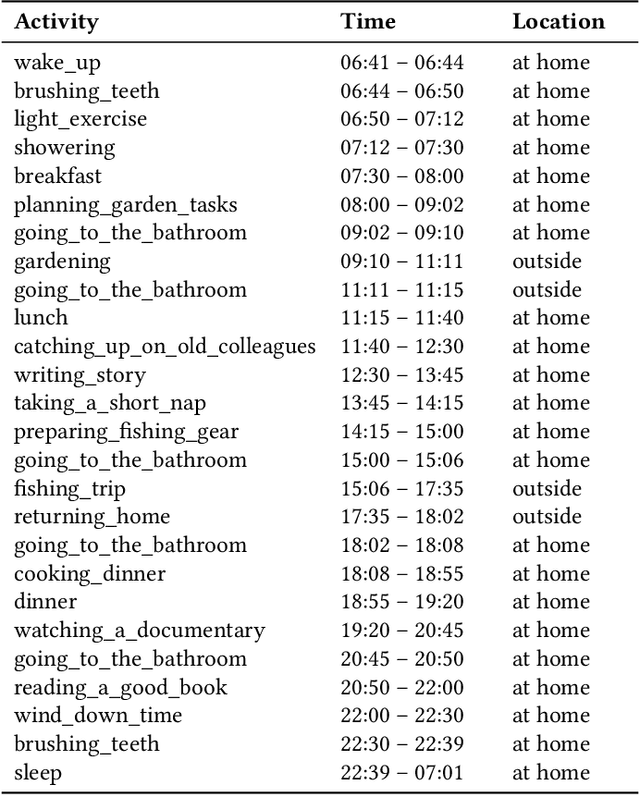
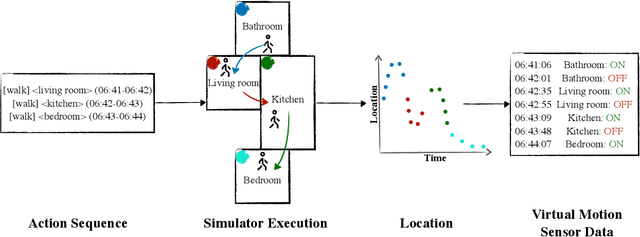
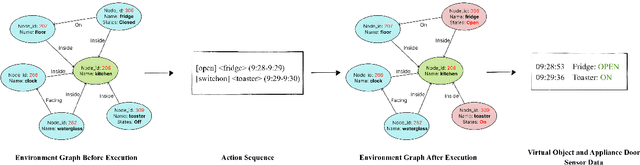
A major obstacle in developing robust and generalizable smart home-based Human Activity Recognition (HAR) systems is the lack of large-scale, diverse labeled datasets. Variability in home layouts, sensor configurations, and user behavior adds further complexity, as individuals follow varied routines and perform activities in distinct ways. Building HAR systems that generalize well requires training data that captures the diversity across users and environments. To address these challenges, we introduce AgentSense, a virtual data generation pipeline where diverse personas are generated by leveraging Large Language Models. These personas are used to create daily routines, which are then decomposed into low-level action sequences. Subsequently, the actions are executed in a simulated home environment called VirtualHome that we extended with virtual ambient sensors capable of recording the agents activities as they unfold. Overall, AgentSense enables the generation of rich, virtual sensor datasets that represent a wide range of users and home settings. Across five benchmark HAR datasets, we show that leveraging our virtual sensor data substantially improves performance, particularly when real data are limited. Notably, models trained on a combination of virtual data and just a few days of real data achieve performance comparable to those trained on the entire real datasets. These results demonstrate and prove the potential of virtual data to address one of the most pressing challenges in ambient sensing, which is the distinct lack of large-scale, annotated datasets without requiring any manual data collection efforts.
Large Language Models Memorize Sensor Datasets! Implications on Human Activity Recognition Research
Jun 09, 2024



The astonishing success of Large Language Models (LLMs) in Natural Language Processing (NLP) has spurred their use in many application domains beyond text analysis, including wearable sensor-based Human Activity Recognition (HAR). In such scenarios, often sensor data are directly fed into an LLM along with text instructions for the model to perform activity classification. Seemingly remarkable results have been reported for such LLM-based HAR systems when they are evaluated on standard benchmarks from the field. Yet, we argue, care has to be taken when evaluating LLM-based HAR systems in such a traditional way. Most contemporary LLMs are trained on virtually the entire (accessible) internet -- potentially including standard HAR datasets. With that, it is not unlikely that LLMs actually had access to the test data used in such benchmark experiments.The resulting contamination of training data would render these experimental evaluations meaningless. In this paper we investigate whether LLMs indeed have had access to standard HAR datasets during training. We apply memorization tests to LLMs, which involves instructing the models to extend given snippets of data. When comparing the LLM-generated output to the original data we found a non-negligible amount of matches which suggests that the LLM under investigation seems to indeed have seen wearable sensor data from the benchmark datasets during training. For the Daphnet dataset in particular, GPT-4 is able to reproduce blocks of sensor readings. We report on our investigations and discuss potential implications on HAR research, especially with regards to reporting results on experimental evaluation
IMUGPT 2.0: Language-Based Cross Modality Transfer for Sensor-Based Human Activity Recognition
Feb 01, 2024One of the primary challenges in the field of human activity recognition (HAR) is the lack of large labeled datasets. This hinders the development of robust and generalizable models. Recently, cross modality transfer approaches have been explored that can alleviate the problem of data scarcity. These approaches convert existing datasets from a source modality, such as video, to a target modality (IMU). With the emergence of generative AI models such as large language models (LLMs) and text-driven motion synthesis models, language has become a promising source data modality as well as shown in proof of concepts such as IMUGPT. In this work, we conduct a large-scale evaluation of language-based cross modality transfer to determine their effectiveness for HAR. Based on this study, we introduce two new extensions for IMUGPT that enhance its use for practical HAR application scenarios: a motion filter capable of filtering out irrelevant motion sequences to ensure the relevance of the generated virtual IMU data, and a set of metrics that measure the diversity of the generated data facilitating the determination of when to stop generating virtual IMU data for both effective and efficient processing. We demonstrate that our diversity metrics can reduce the effort needed for the generation of virtual IMU data by at least 50%, which open up IMUGPT for practical use cases beyond a mere proof of concept.