 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentSense: Virtual Sensor Data Generation Using LLM Agents in Simulated Home Environments
Jun 16, 2025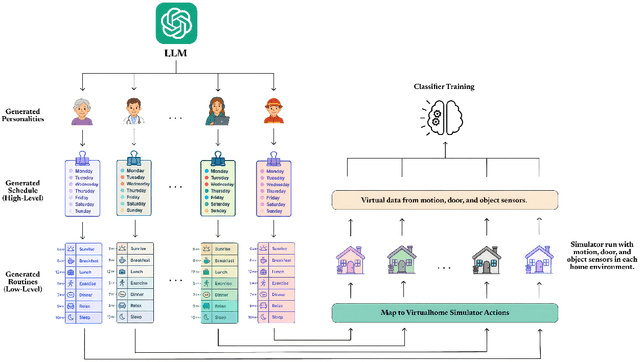
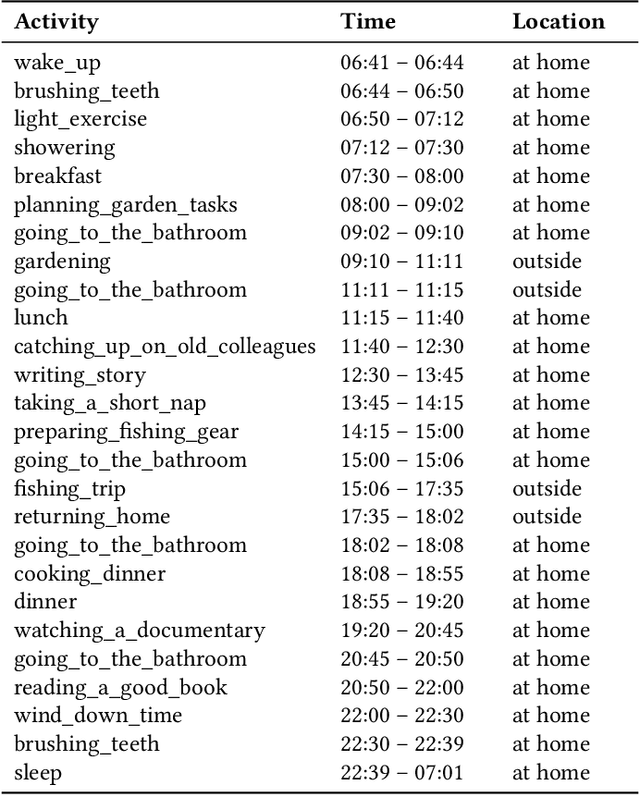
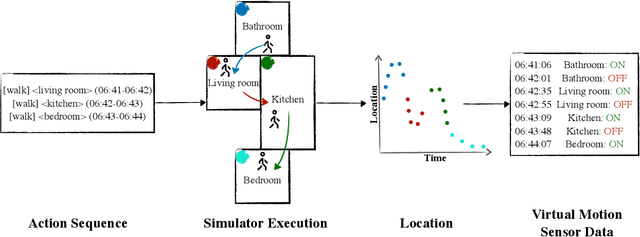
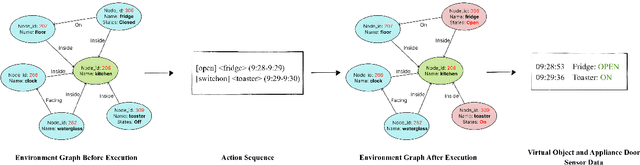
A major obstacle in developing robust and generalizable smart home-based Human Activity Recognition (HAR) systems is the lack of large-scale, diverse labeled datasets. Variability in home layouts, sensor configurations, and user behavior adds further complexity, as individuals follow varied routines and perform activities in distinct ways. Building HAR systems that generalize well requires training data that captures the diversity across users and environments. To address these challenges, we introduce AgentSense, a virtual data generation pipeline where diverse personas are generated by leveraging Large Language Models. These personas are used to create daily routines, which are then decomposed into low-level action sequences. Subsequently, the actions are executed in a simulated home environment called VirtualHome that we extended with virtual ambient sensors capable of recording the agents activities as they unfold. Overall, AgentSense enables the generation of rich, virtual sensor datasets that represent a wide range of users and home settings. Across five benchmark HAR datasets, we show that leveraging our virtual sensor data substantially improves performance, particularly when real data are limited. Notably, models trained on a combination of virtual data and just a few days of real data achieve performance comparable to those trained on the entire real datasets. These results demonstrate and prove the potential of virtual data to address one of the most pressing challenges in ambient sensing, which is the distinct lack of large-scale, annotated datasets without requiring any manual data collection efforts.
Scaling Human Activity Recognition: A Comparative Evaluation of Synthetic Data Generation and Augmentation Techniques
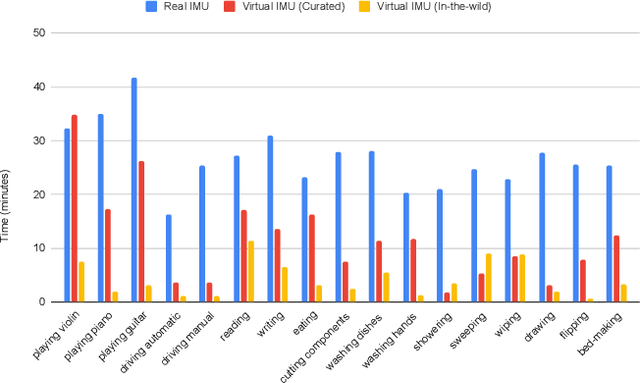
Jun 09, 2025Human activity recognition (HAR) is often limited by the scarcity of labeled datasets due to the high cost and complexity of real-world data collection. To mitigate this, recent work has explored generating virtual inertial measurement unit (IMU) data via cross-modality transfer. While video-based and language-based pipelines have each shown promise, they differ in assumptions and computational cost. Moreover, their effectiveness relative to traditional sensor-level data augmentation remains unclear. In this paper, we present a direct comparison between these two virtual IMU generation approaches against classical data augmentation techniques. We construct a large-scale virtual IMU dataset spanning 100 diverse activities from Kinetics-400 and simulate sensor signals at 22 body locations. The three data generation strategies are evaluated on benchmark HAR datasets (UTD-MHAD, PAMAP2, HAD-AW) using four popular models. Results show that virtual IMU data significantly improves performance over real or augmented data alone, particularly under limited-data conditions. We offer practical guidance on choosing data generation strategies and highlight the distinct advantages and disadvantages of each approach.
IMUGPT 2.0: Language-Based Cross Modality Transfer for Sensor-Based Human Activity Recognition
Feb 01, 2024One of the primary challenges in the field of human activity recognition (HAR) is the lack of large labeled datasets. This hinders the development of robust and generalizable models. Recently, cross modality transfer approaches have been explored that can alleviate the problem of data scarcity. These approaches convert existing datasets from a source modality, such as video, to a target modality (IMU). With the emergence of generative AI models such as large language models (LLMs) and text-driven motion synthesis models, language has become a promising source data modality as well as shown in proof of concepts such as IMUGPT. In this work, we conduct a large-scale evaluation of language-based cross modality transfer to determine their effectiveness for HAR. Based on this study, we introduce two new extensions for IMUGPT that enhance its use for practical HAR application scenarios: a motion filter capable of filtering out irrelevant motion sequences to ensure the relevance of the generated virtual IMU data, and a set of metrics that measure the diversity of the generated data facilitating the determination of when to stop generating virtual IMU data for both effective and efficient processing. We demonstrate that our diversity metrics can reduce the effort needed for the generation of virtual IMU data by at least 50%, which open up IMUGPT for practical use cases beyond a mere proof of concept.
Know Thy Neighbors: A Graph Based Approach for Effective Sensor-Based Human Activity Recognition in Smart Homes
Nov 16, 2023There has been a resurgence of applications focused on Human Activity Recognition (HAR) in smart homes, especially in the field of ambient intelligence and assisted living technologies. However, such applications present numerous significant challenges to any automated analysis system operating in the real world, such as variability, sparsity, and noise in sensor measurements. Although state-of-the-art HAR systems have made considerable strides in addressing some of these challenges, they especially suffer from a practical limitation: they require successful pre-segmentation of continuous sensor data streams before automated recognition, i.e., they assume that an oracle is present during deployment, which is capable of identifying time windows of interest across discrete sensor events. To overcome this limitation, we propose a novel graph-guided neural network approach that performs activity recognition by learning explicit co-firing relationships between sensors. We accomplish this by learning a more expressive graph structure representing the sensor network in a smart home, in a data-driven manner. Our approach maps discrete input sensor measurements to a feature space through the application of attention mechanisms and hierarchical pooling of node embeddings. We demonstrate the effectiveness of our proposed approach by conducting several experiments on CASAS datasets, showing that the resulting graph-guided neural network outperforms the state-of-the-art method for HAR in smart homes across multiple datasets and by large margins. These results are promising because they push HAR for smart homes closer to real-world applications.
On the Benefit of Generative Foundation Models for Human Activity Recognition
Oct 18, 2023In human activity recognition (HAR), the limited availability of annotated data presents a significant challenge. Drawing inspiration from the latest advancements in generative AI, including Large Language Models (LLMs) and motion synthesis models, we believe that generative AI can address this data scarcity by autonomously generating virtual IMU data from text descriptions. Beyond this, we spotlight several promising research pathways that could benefit from generative AI for the community, including the generating benchmark datasets, the development of foundational models specific to HAR, the exploration of hierarchical structures within HAR, breaking down complex activities, and applications in health sensing and activity summarization.
Generating Virtual On-body Accelerometer Data from Virtual Textual Descriptions for Human Activity Recognition
May 04, 2023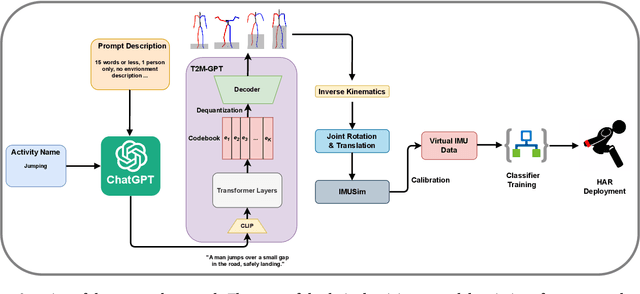
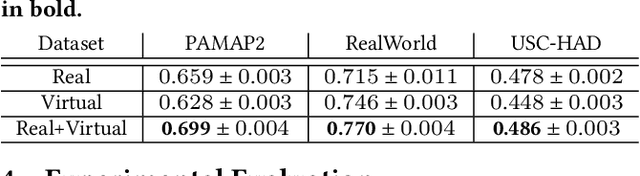
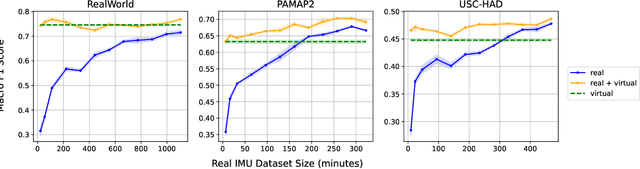
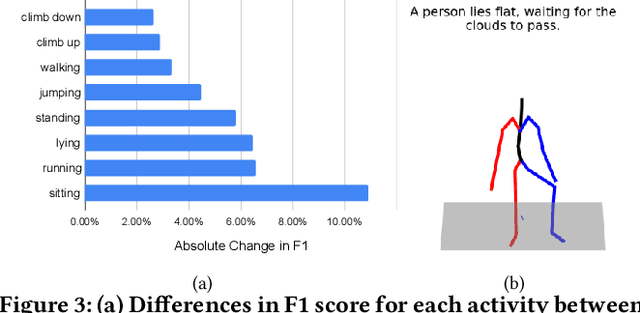
The development of robust, generalized models in human activity recognition (HAR) has been hindered by the scarcity of large-scale, labeled data sets. Recent work has shown that virtual IMU data extracted from videos using computer vision techniques can lead to substantial performance improvements when training HAR models combined with small portions of real IMU data. Inspired by recent advances in motion synthesis from textual descriptions and connecting Large Language Models (LLMs) to various AI models, we introduce an automated pipeline that first uses ChatGPT to generate diverse textual descriptions of activities. These textual descriptions are then used to generate 3D human motion sequences via a motion synthesis model, T2M-GPT, and later converted to streams of virtual IMU data. We benchmarked our approach on three HAR datasets (RealWorld, PAMAP2, and USC-HAD) and demonstrate that the use of virtual IMU training data generated using our new approach leads to significantly improved HAR model performance compared to only using real IMU data. Our approach contributes to the growing field of cross-modality transfer methods and illustrate how HAR models can be improved through the generation of virtual training data that do not require any manual effort.
Fine-grained Human Activity Recognition Using Virtual On-body Acceleration Data
Nov 02, 2022
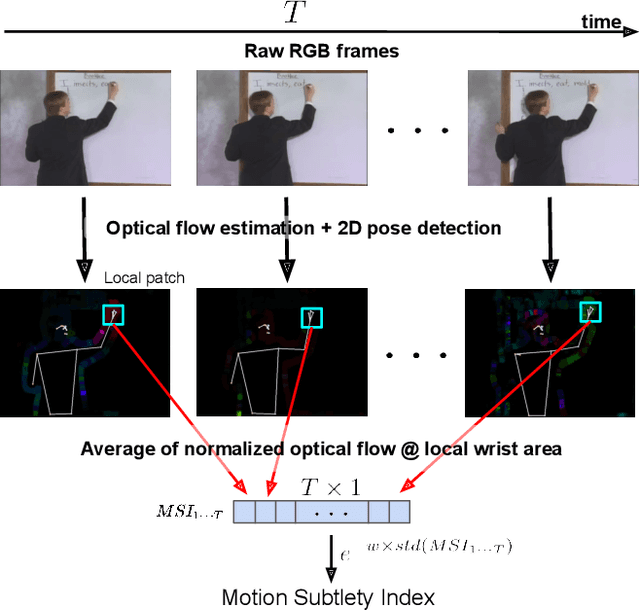

Previous work has demonstrated that virtual accelerometry data, extracted from videos using cross-modality transfer approaches like IMUTube, is beneficial for training complex and effective human activity recognition (HAR) models. Systems like IMUTube were originally designed to cover activities that are based on substantial body (part) movements. Yet, life is complex, and a range of activities of daily living is based on only rather subtle movements, which bears the question to what extent systems like IMUTube are of value also for fine-grained HAR, i.e., When does IMUTube break? In this work we first introduce a measure to quantitatively assess the subtlety of human movements that are underlying activities of interest--the motion subtlety index (MSI)--which captures local pixel movements and pose changes in the vicinity of target virtual sensor locations, and correlate it to the eventual activity recognition accuracy. We then perform a "stress-test" on IMUTube and explore for which activities with underlying subtle movements a cross-modality transfer approach works, and for which not. As such, the work presented in this paper allows us to map out the landscape for IMUTube applications in practical scenarios.
Assessing the State of Self-Supervised Human Activity Recognition using Wearables
Feb 22, 2022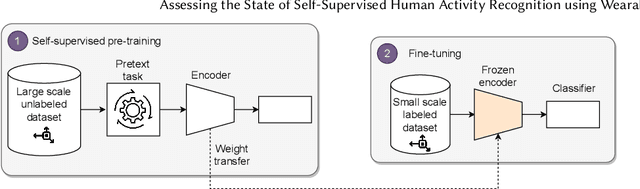

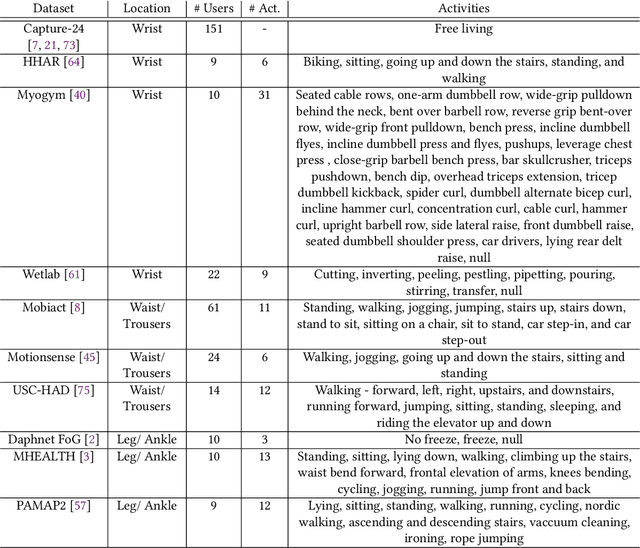
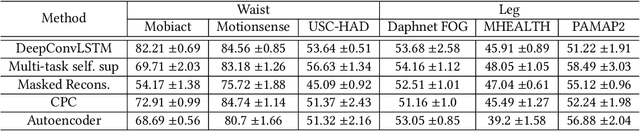
The emergence of self-supervised learning in the field of wearables-based human activity recognition (HAR) has opened up opportunities to tackle the most pressing challenges in the field, namely to exploit unlabeled data to derive reliable recognition systems from only small amounts of labeled training samples. Furthermore, self-supervised methods enable a host of new application domains such as, for example, domain adaptation and transfer across sensor positions, activities etc. As such, self-supervision, i.e., the paradigm of 'pretrain-then-finetune' has the potential to become a strong alternative to the predominant end-to-end training approaches, let alone the classic activity recognition chain with hand-crafted features of sensor data. Recently a number of contributions have been made that introduced self-supervised learning into the field of HAR, including, Multi-task self-supervision, Masked Reconstruction, CPC to name but a few. With the initial success of these methods, the time has come for a systematic inventory and analysis of the potential self-supervised learning has for the field. This paper provides exactly that. We assess the progress of self-supervised HAR research by introducing a framework that performs a multi-faceted exploration of model performance. We organize the framework into three dimensions, each containing three constituent criteria, and utilize it to assess state-of-the-art self-supervised learning methods in a large empirical study on a curated set of nine diverse benchmarks. This exploration leads us to the formulation of insights into the properties of these techniques and to establish their value towards learning representations for diverse scenarios. Based on our findings we call upon the community to join our efforts and to contribute towards shaping the evaluation of the ongoing paradigm change in modeling human activities from body-worn sensor data.
Towards Using Unlabeled Data in a Sparse-coding Framework for Human Activity Recognition
Jul 23, 2014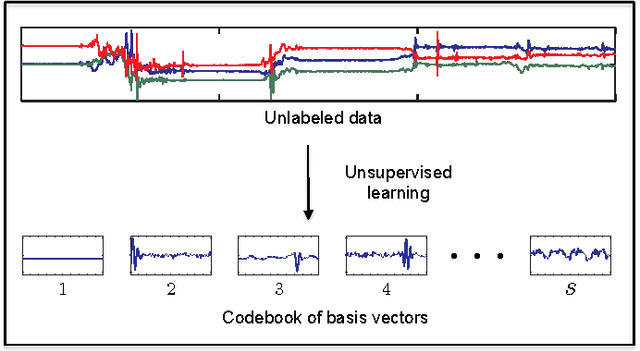

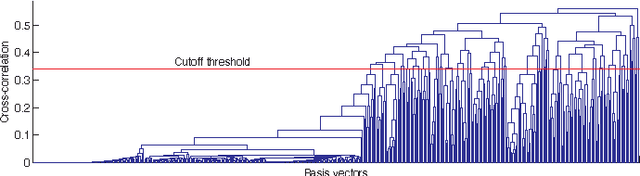

We propose a sparse-coding framework for activity recognition in ubiquitous and mobile computing that alleviates two fundamental problems of current supervised learning approaches. (i) It automatically derives a compact, sparse and meaningful feature representation of sensor data that does not rely on prior expert knowledge and generalizes extremely well across domain boundaries. (ii) It exploits unlabeled sample data for bootstrapping effective activity recognizers, i.e., substantially reduces the amount of ground truth annotation required for model estimation. Such unlabeled data is trivial to obtain, e.g., through contemporary smartphones carried by users as they go about their everyday activities. Based on the self-taught learning paradigm we automatically derive an over-complete set of basis vectors from unlabeled data that captures inherent patterns present within activity data. Through projecting raw sensor data onto the feature space defined by such over-complete sets of basis vectors effective feature extraction is pursued. Given these learned feature representations, classification backends are then trained using small amounts of labeled training data. We study the new approach in detail using two datasets which differ in terms of the recognition tasks and sensor modalities. Primarily we focus on transportation mode analysis task, a popular task in mobile-phone based sensing. The sparse-coding framework significantly outperforms the state-of-the-art in supervised learning approaches. Furthermore, we demonstrate the great practical potential of the new approach by successfully evaluating its generalization capabilities across both domain and sensor modalities by considering the popular Opportunity dataset. Our feature learning approach outperforms state-of-the-art approaches to analyzing activities in daily living.