 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecture-Sensitive Supervised Fine-Tuning for Screen-Conditioned Action Prediction: A PiSAR Benchmark
May 28, 2026We benchmark three supervised fine-tuned models against frontier zero-shot baselines on a 661-row held-out slice of PiSAR (Persona, intent, Screen, Action, Rationale), a 12,929-tuple corpus of screen-anchored behavioural rationales curated from public app-store reviews, Pew American Trends Panel demographics, and the OPeRA shopper traces. Every model, frontier or fine-tuned, is evaluated on the same 661-row slice with the same scoring pipeline. Two findings. First, frontier zero-shot baselines (Claude Opus 4.7 and GPT-5.5) reach sem_sim 0.459 and 0.482 respectively; a fine-tuned Qwen3-VL-8B-Instruct reaches 0.783 and clears sem_sim >= 0.7 on 79% of rows, against 1-2% for either frontier baseline, a gap of 0.30 absolute on the same test set. Second, the same training data and recipe on Gemma-4-26B-A4B-IT scores only 0.441, in the same band as the frontier zero-shot baselines rather than the fine-tuned Qwen. We read this as a recipe-vs-model mismatch: the reasoning-tuned high-parameter model resists displacement and would likely need either more data or a stronger fine-tuning method.
Bayesian Inverse Games with High-Dimensional Multi-Modal Observations
Jan 02, 2026Many multi-agent interaction scenarios can be naturally modeled as noncooperative games, where each agent's decisions depend on others' future actions. However, deploying game-theoretic planners for autonomous decision-making requires a specification of all agents' objectives. To circumvent this practical difficulty, recent work develops maximum likelihood techniques for solving inverse games that can identify unknown agent objectives from interaction data. Unfortunately, these methods only infer point estimates and do not quantify estimator uncertainty; correspondingly, downstream planning decisions can overconfidently commit to unsafe actions. We present an approximate Bayesian inference approach for solving the inverse game problem, which can incorporate observation data from multiple modalities and be used to generate samples from the Bayesian posterior over the hidden agent objectives given limited sensor observations in real time. Concretely, the proposed Bayesian inverse game framework trains a structured variational autoencoder with an embedded differentiable Nash game solver on interaction datasets and does not require labels of agents' true objectives. Extensive experiments show that our framework successfully learns prior and posterior distributions, improves inference quality over maximum likelihood estimation-based inverse game approaches, and enables safer downstream decision-making without sacrificing efficiency. When trajectory information is uninformative or unavailable, multimodal inference further reduces uncertainty by exploiting additional observation modalities.
Local Prompt Optimization
Apr 29, 2025



In recent years, the use of prompts to guide the output of Large Language Models have increased dramatically. However, even the best of experts struggle to choose the correct words to stitch up a prompt for the desired task. To solve this, LLM driven prompt optimization emerged as an important problem. Existing prompt optimization methods optimize a prompt globally, where in all the prompt tokens have to be optimized over a large vocabulary while solving a complex task. The large optimization space (tokens) leads to insufficient guidance for a better prompt. In this work, we introduce Local Prompt Optimization (LPO) that integrates with any general automatic prompt engineering method. We identify the optimization tokens in a prompt and nudge the LLM to focus only on those tokens in its optimization step. We observe remarkable performance improvements on Math Reasoning (GSM8k and MultiArith) and BIG-bench Hard benchmarks across various automatic prompt engineering methods. Further, we show that LPO converges to the optimal prompt faster than global methods.
RiTTA: Modeling Event Relations in Text-to-Audio Generation
Dec 20, 2024
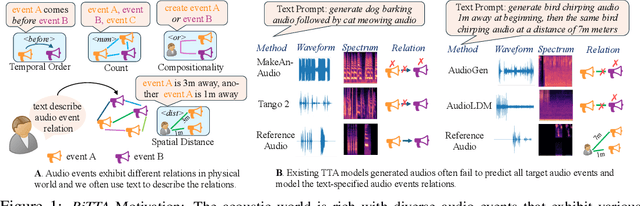
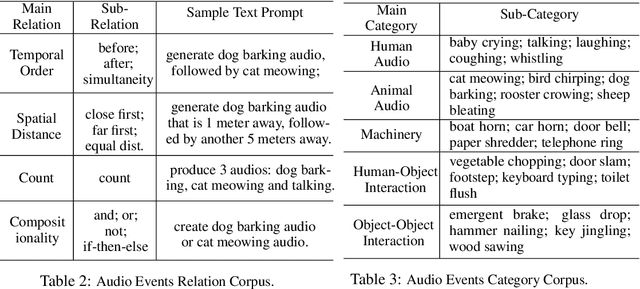
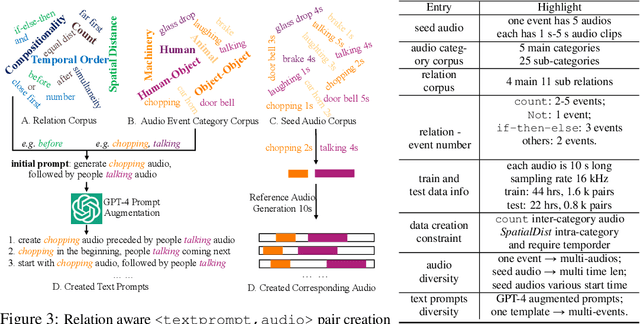
Despite significant advancements in Text-to-Audio (TTA) generation models achieving high-fidelity audio with fine-grained context understanding, they struggle to model the relations between audio events described in the input text. However, previous TTA methods have not systematically explored audio event relation modeling, nor have they proposed frameworks to enhance this capability. In this work, we systematically study audio event relation modeling in TTA generation models. We first establish a benchmark for this task by: 1. proposing a comprehensive relation corpus covering all potential relations in real-world scenarios; 2. introducing a new audio event corpus encompassing commonly heard audios; and 3. proposing new evaluation metrics to assess audio event relation modeling from various perspectives. Furthermore, we propose a finetuning framework to enhance existing TTA models ability to model audio events relation. Code is available at: https://github.com/yuhanghe01/RiTTA
DH-Bench: Probing Depth and Height Perception of Large Visual-Language Models
Aug 21, 2024



Geometric understanding is crucial for navigating and interacting with our environment. While large Vision Language Models (VLMs) demonstrate impressive capabilities, deploying them in real-world scenarios necessitates a comparable geometric understanding in visual perception. In this work, we focus on the geometric comprehension of these models; specifically targeting the depths and heights of objects within a scene. Our observations reveal that, although VLMs excel in basic geometric properties perception such as shape and size, they encounter significant challenges in reasoning about the depth and height of objects. To address this, we introduce a suite of benchmark datasets encompassing Synthetic 2D, Synthetic 3D, and Real-World scenarios to rigorously evaluate these aspects. We benchmark 17 state-of-the-art VLMs using these datasets and find that they consistently struggle with both depth and height perception. Our key insights include detailed analyses of the shortcomings in depth and height reasoning capabilities of VLMs and the inherent bias present in these models. This study aims to pave the way for the development of VLMs with enhanced geometric understanding, crucial for real-world applications. The code and datasets for our benchmarks will be available at \url{https://tinyurl.com/DH-Bench1}.
Multi-Stage Multi-Modal Pre-Training for Automatic Speech Recognition
Mar 28, 2024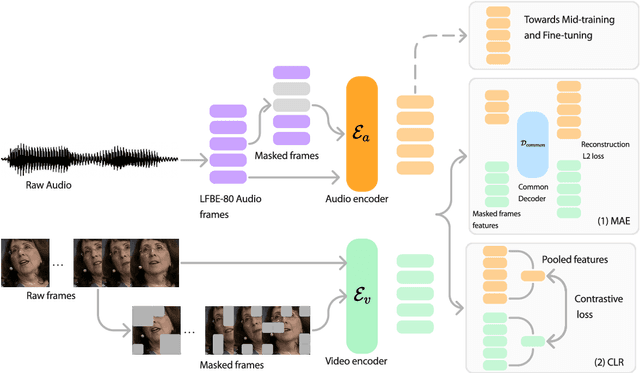
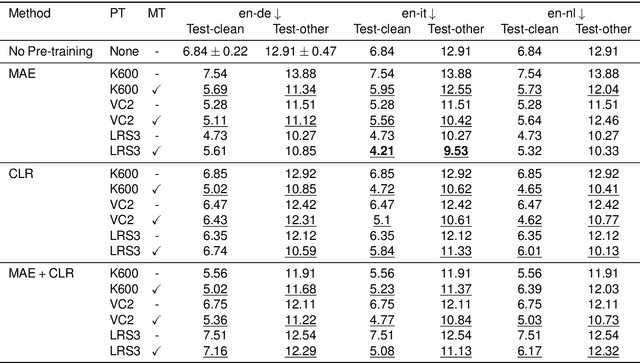
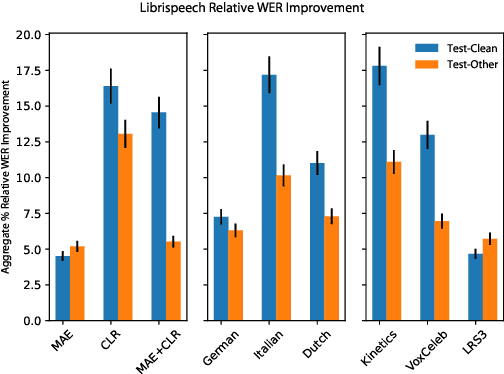
Recent advances in machine learning have demonstrated that multi-modal pre-training can improve automatic speech recognition (ASR) performance compared to randomly initialized models, even when models are fine-tuned on uni-modal tasks. Existing multi-modal pre-training methods for the ASR task have primarily focused on single-stage pre-training where a single unsupervised task is used for pre-training followed by fine-tuning on the downstream task. In this work, we introduce a novel method combining multi-modal and multi-task unsupervised pre-training with a translation-based supervised mid-training approach. We empirically demonstrate that such a multi-stage approach leads to relative word error rate (WER) improvements of up to 38.45% over baselines on both Librispeech and SUPERB. Additionally, we share several important findings for choosing pre-training methods and datasets.
PEEKABOO: Interactive Video Generation via Masked-Diffusion
Dec 12, 2023Recently there has been a lot of progress in text-to-video generation, with state-of-the-art models being capable of generating high quality, realistic videos. However, these models lack the capability for users to interactively control and generate videos, which can potentially unlock new areas of application. As a first step towards this goal, we tackle the problem of endowing diffusion-based video generation models with interactive spatio-temporal control over their output. To this end, we take inspiration from the recent advances in segmentation literature to propose a novel spatio-temporal masked attention module - Peekaboo. This module is a training-free, no-inference-overhead addition to off-the-shelf video generation models which enables spatio-temporal control. We also propose an evaluation benchmark for the interactive video generation task. Through extensive qualitative and quantitative evaluation, we establish that Peekaboo enables control video generation and even obtains a gain of upto 3.8x in mIoU over baseline models.
Signed Binarization: Unlocking Efficiency Through Repetition-Sparsity Trade-Off
Dec 04, 2023



Efficient inference of Deep Neural Networks (DNNs) on resource-constrained edge devices is essential. Quantization and sparsity are key algorithmic techniques that translate to repetition and sparsity within tensors at the hardware-software interface. This paper introduces the concept of repetition-sparsity trade-off that helps explain computational efficiency during inference. We propose Signed Binarization, a unified co-design framework that synergistically integrates hardware-software systems, quantization functions, and representation learning techniques to address this trade-off. Our results demonstrate that Signed Binarization is more accurate than binarization with the same number of non-zero weights. Detailed analysis indicates that signed binarization generates a smaller distribution of effectual (non-zero) parameters nested within a larger distribution of total parameters, both of the same type, for a DNN block. Finally, our approach achieves a 26% speedup on real hardware, doubles energy efficiency, and reduces density by 2.8x compared to binary methods for ResNet 18, presenting an alternative solution for deploying efficient models in resource-limited environments.
DAMEX: Dataset-aware Mixture-of-Experts for visual understanding of mixture-of-datasets
Nov 08, 2023



Construction of a universal detector poses a crucial question: How can we most effectively train a model on a large mixture of datasets? The answer lies in learning dataset-specific features and ensembling their knowledge but do all this in a single model. Previous methods achieve this by having separate detection heads on a common backbone but that results in a significant increase in parameters. In this work, we present Mixture-of-Experts as a solution, highlighting that MoEs are much more than a scalability tool. We propose Dataset-Aware Mixture-of-Experts, DAMEX where we train the experts to become an `expert' of a dataset by learning to route each dataset tokens to its mapped expert. Experiments on Universal Object-Detection Benchmark show that we outperform the existing state-of-the-art by average +10.2 AP score and improve over our non-MoE baseline by average +2.0 AP score. We also observe consistent gains while mixing datasets with (1) limited availability, (2) disparate domains and (3) divergent label sets. Further, we qualitatively show that DAMEX is robust against expert representation collapse.
Fine-grained Human Activity Recognition Using Virtual On-body Acceleration Data
Nov 02, 2022
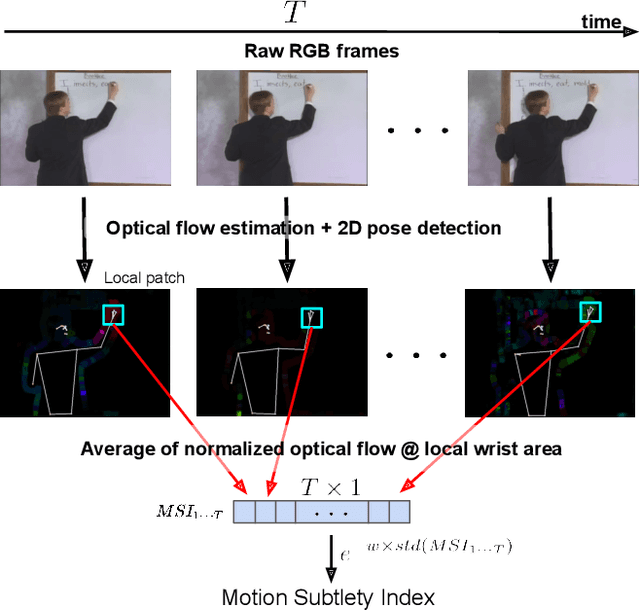
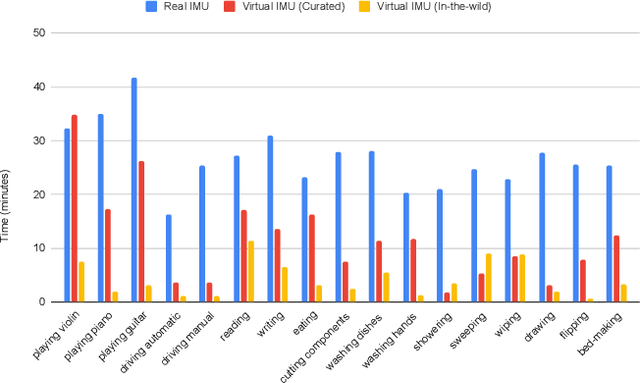

Previous work has demonstrated that virtual accelerometry data, extracted from videos using cross-modality transfer approaches like IMUTube, is beneficial for training complex and effective human activity recognition (HAR) models. Systems like IMUTube were originally designed to cover activities that are based on substantial body (part) movements. Yet, life is complex, and a range of activities of daily living is based on only rather subtle movements, which bears the question to what extent systems like IMUTube are of value also for fine-grained HAR, i.e., When does IMUTube break? In this work we first introduce a measure to quantitatively assess the subtlety of human movements that are underlying activities of interest--the motion subtlety index (MSI)--which captures local pixel movements and pose changes in the vicinity of target virtual sensor locations, and correlate it to the eventual activity recognition accuracy. We then perform a "stress-test" on IMUTube and explore for which activities with underlying subtle movements a cross-modality transfer approach works, and for which not. As such, the work presented in this paper allows us to map out the landscape for IMUTube applications in practical scenarios.