 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stage Multi-Modal Pre-Training for Automatic Speech Recognition
Mar 28, 2024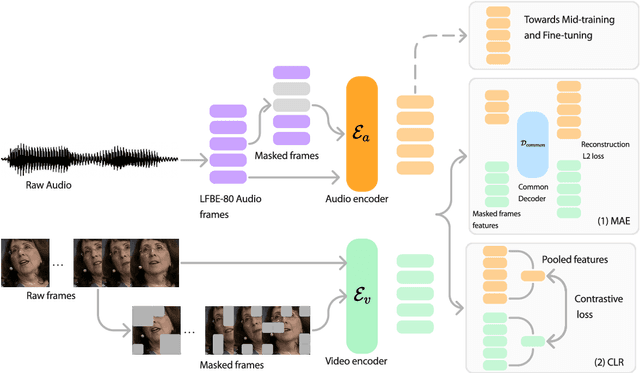
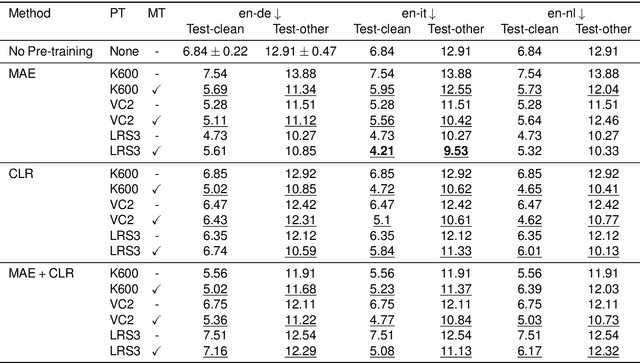
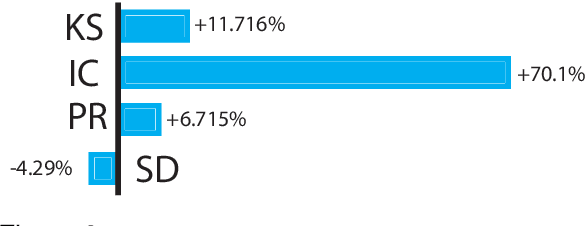
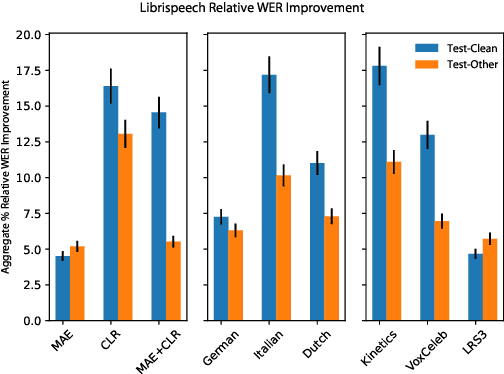
Recent advances in machine learning have demonstrated that multi-modal pre-training can improve automatic speech recognition (ASR) performance compared to randomly initialized models, even when models are fine-tuned on uni-modal tasks. Existing multi-modal pre-training methods for the ASR task have primarily focused on single-stage pre-training where a single unsupervised task is used for pre-training followed by fine-tuning on the downstream task. In this work, we introduce a novel method combining multi-modal and multi-task unsupervised pre-training with a translation-based supervised mid-training approach. We empirically demonstrate that such a multi-stage approach leads to relative word error rate (WER) improvements of up to 38.45% over baselines on both Librispeech and SUPERB. Additionally, we share several important findings for choosing pre-training methods and datasets.
Stutter-TTS: Controlled Synthesis and Improved Recognition of Stuttered Speech
Nov 04, 2022



Stuttering is a speech disorder where the natural flow of speech is interrupted by blocks, repetitions or prolongations of syllables, words and phrases. The majority of existing automatic speech recognition (ASR) interfaces perform poorly on utterances with stutter, mainly due to lack of matched training data. Synthesis of speech with stutter thus presents an opportunity to improve ASR for this type of speech. We describe Stutter-TTS, an end-to-end neural text-to-speech model capable of synthesizing diverse types of stuttering utterances. We develop a simple, yet effective prosody-control strategy whereby additional tokens are introduced into source text during training to represent specific stuttering characteristics. By choosing the position of the stutter tokens, Stutter-TTS allows word-level control of where stuttering occurs in the synthesized utterance. We are able to synthesize stutter events with high accuracy (F1-scores between 0.63 and 0.84, depending on stutter type). By fine-tuning an ASR model on synthetic stuttered speech we are able to reduce word error by 5.7% relative on stuttered utterances, with only minor (<0.2% relative) degradation for fluent utterances.
* 8 pages, 3 figures, 2 tables
Enhancing ASR for Stuttered Speech with Limited Data Using Detect and Pass
Feb 08, 2022It is estimated that around 70 million people worldwide are affected by a speech disorder called stuttering. With recent advances in Automatic Speech Recognition (ASR), voice assistants are increasingly useful in our everyday lives. Many technologies in education, retail, telecommunication and healthcare can now be operated through voice. Unfortunately, these benefits are not accessible for People Who Stutter (PWS). We propose a simple but effective method called 'Detect and Pass' to make modern ASR systems accessible for People Who Stutter in a limited data setting. The algorithm uses a context aware classifier trained on a limited amount of data, to detect acoustic frames that contain stutter. To improve robustness on stuttered speech, this extra information is passed on to the ASR model to be utilized during inference. Our experiments show a reduction of 12.18% to 71.24% in Word Error Rate (WER) across various state of the art ASR systems. Upon varying the threshold of the associated posterior probability of stutter for each stacked frame used in determining low frame rate (LFR) acoustic features, we were able to determine an optimal setting that reduced the WER by 23.93% to 71.67% across different ASR systems.
ASBERT: Siamese and Triplet network embedding for open question answering
Apr 17, 2021
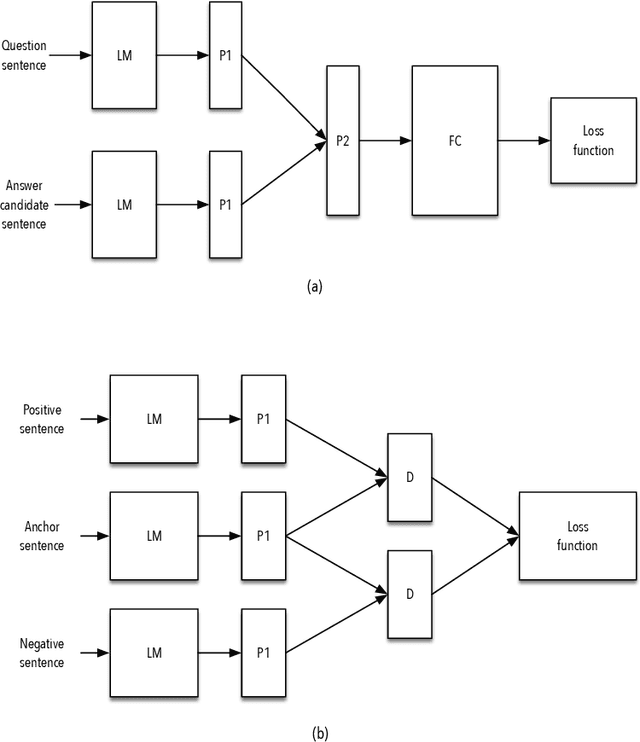
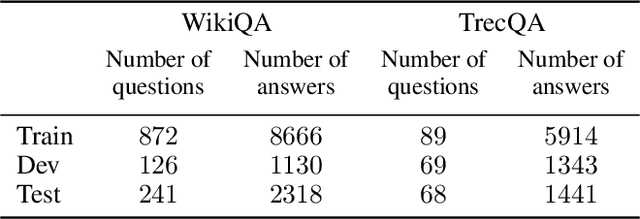
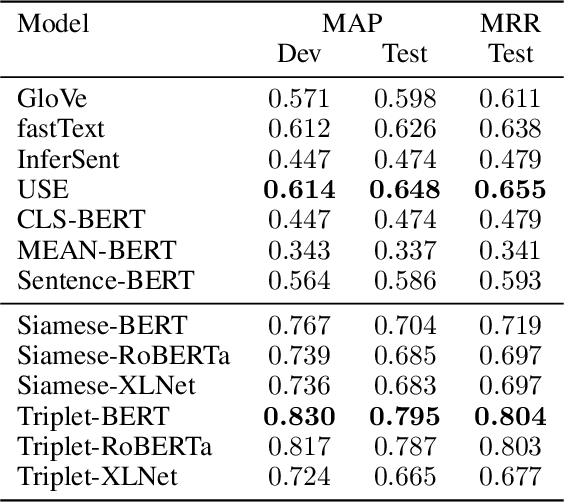
Answer selection (AS) is an essential subtask in the field of natural language processing with an objective to identify the most likely answer to a given question from a corpus containing candidate answer sentences. A common approach to address the AS problem is to generate an embedding for each candidate sentence and query. Then, select the sentence whose vector representation is closest to the query's. A key drawback is the low quality of the embeddings, hitherto, based on its performance on AS benchmark datasets. In this work, we present ASBERT, a framework built on the BERT architecture that employs Siamese and Triplet neural networks to learn an encoding function that maps a text to a fixed-size vector in an embedded space. The notion of distance between two points in this space connotes similarity in meaning between two texts. Experimental results on the WikiQA and TrecQA datasets demonstrate that our proposed approach outperforms many state-of-the-art baseline methods.