 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Stutter-TTS: Controlled Synthesis and Improved Recognition of Stuttered Speech
Nov 04, 2022



Stuttering is a speech disorder where the natural flow of speech is interrupted by blocks, repetitions or prolongations of syllables, words and phrases. The majority of existing automatic speech recognition (ASR) interfaces perform poorly on utterances with stutter, mainly due to lack of matched training data. Synthesis of speech with stutter thus presents an opportunity to improve ASR for this type of speech. We describe Stutter-TTS, an end-to-end neural text-to-speech model capable of synthesizing diverse types of stuttering utterances. We develop a simple, yet effective prosody-control strategy whereby additional tokens are introduced into source text during training to represent specific stuttering characteristics. By choosing the position of the stutter tokens, Stutter-TTS allows word-level control of where stuttering occurs in the synthesized utterance. We are able to synthesize stutter events with high accuracy (F1-scores between 0.63 and 0.84, depending on stutter type). By fine-tuning an ASR model on synthetic stuttered speech we are able to reduce word error by 5.7% relative on stuttered utterances, with only minor (<0.2% relative) degradation for fluent utterances.
* 8 pages, 3 figures, 2 tables
Peking Opera Synthesis via Duration Informed Attention Network
Aug 07, 2020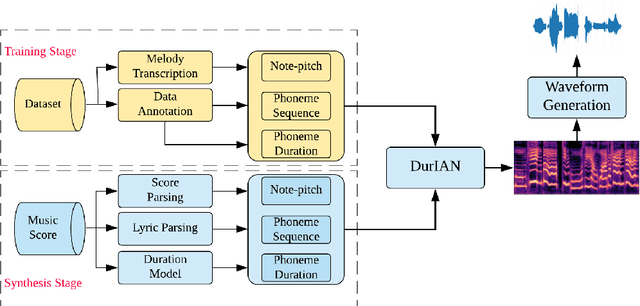
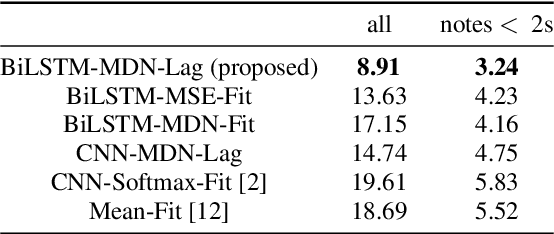
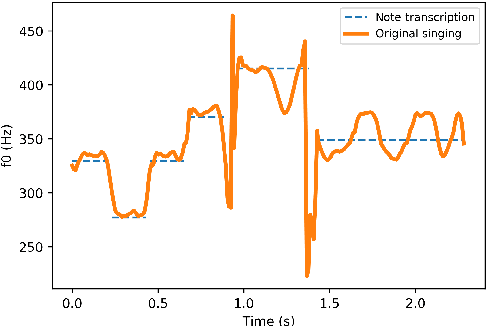
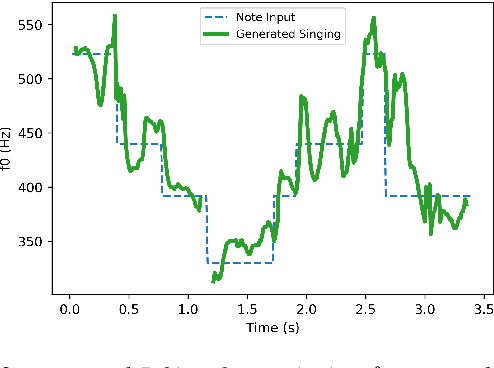
Peking Opera has been the most dominant form of Chinese performing art since around 200 years ago. A Peking Opera singer usually exhibits a very strong personal style via introducing improvisation and expressiveness on stage which leads the actual rhythm and pitch contour to deviate significantly from the original music score. This inconsistency poses a great challenge in Peking Opera singing voice synthesis from a music score. In this work, we propose to deal with this issue and synthesize expressive Peking Opera singing from the music score based on the Duration Informed Attention Network (DurIAN) framework. To tackle the rhythm mismatch, Lagrange multiplier is used to find the optimal output phoneme duration sequence with the constraint of the given note duration from music score. As for the pitch contour mismatch, instead of directly inferring from music score, we adopt a pseudo music score generated from the real singing and feed it as input during training. The experiments demonstrate that with the proposed system we can synthesize Peking Opera singing voice with high-quality timbre, pitch and expressiveness.
Synthesising Expressiveness in Peking Opera via Duration Informed Attention Network
Dec 27, 2019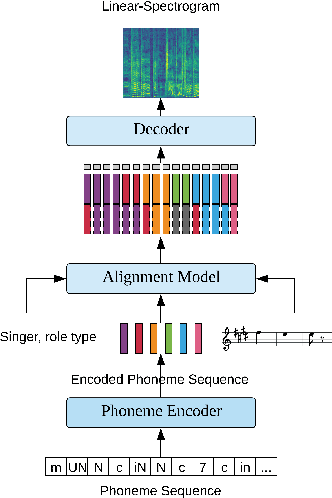
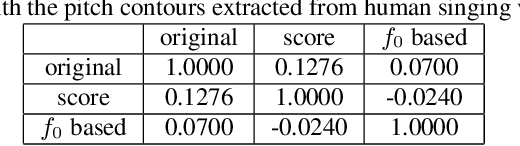
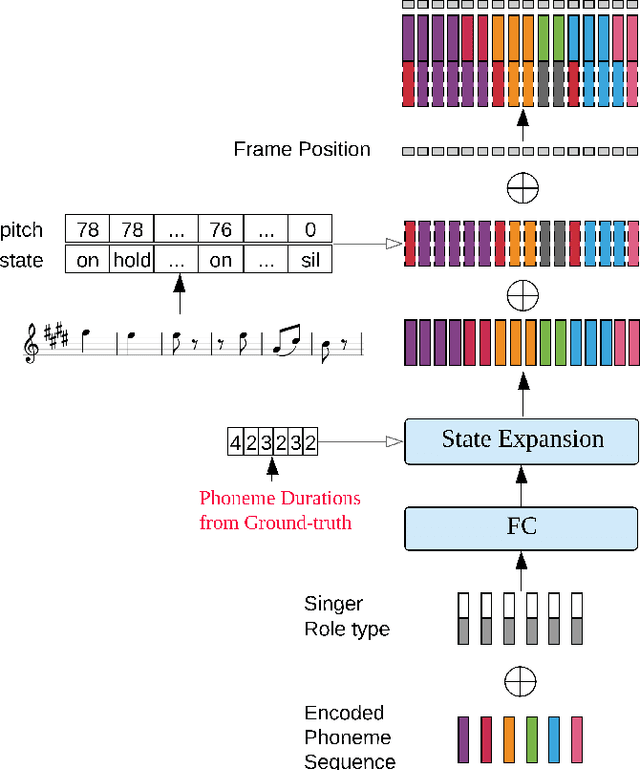

This paper presents a method that generates expressive singing voice of Peking opera. The synthesis of expressive opera singing usually requires pitch contours to be extracted as the training data, which relies on techniques and is not able to be manually labeled. With the Duration Informed Attention Network (DurIAN), this paper makes use of musical note instead of pitch contours for expressive opera singing synthesis. The proposed method enables human annotation being combined with automatic extracted features to be used as training data thus the proposed method gives extra flexibility in data collection for Peking opera singing synthesis. Comparing with the expressive singing voice of Peking opera synthesised by pitch contour based system, the proposed musical note based system produces comparable singing voice in Peking opera with expressiveness in various aspects.
Learning Singing From Speech
Dec 20, 2019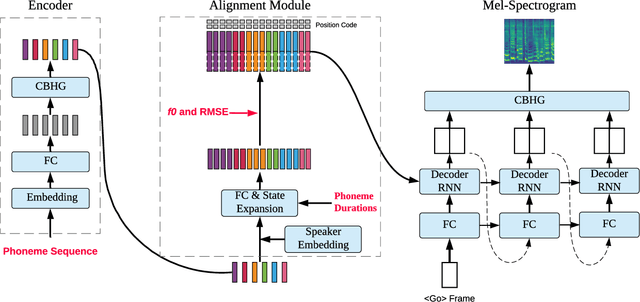
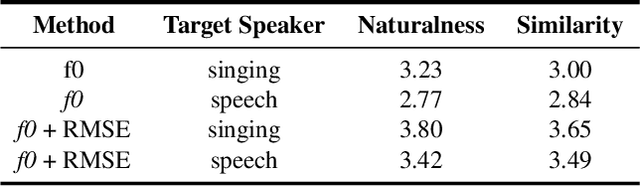
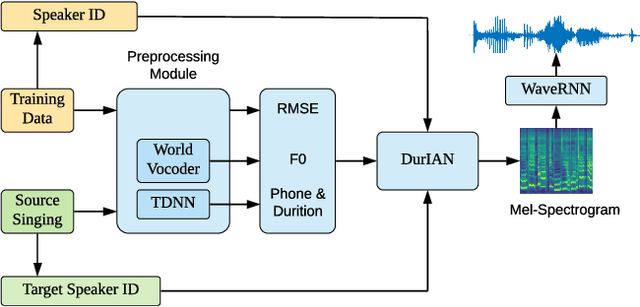
We propose an algorithm that is capable of synthesizing high quality target speaker's singing voice given only their normal speech samples. The proposed algorithm first integrate speech and singing synthesis into a unified framework, and learns universal speaker embeddings that are shareable between speech and singing synthesis tasks. Specifically, the speaker embeddings learned from normal speech via the speech synthesis objective are shared with those learned from singing samples via the singing synthesis objective in the unified training framework. This makes the learned speaker embedding a transferable representation for both speaking and singing. We evaluate the proposed algorithm on singing voice conversion task where the content of original singing is covered with the timbre of another speaker's voice learned purely from their normal speech samples. Our experiments indicate that the proposed algorithm generates high-quality singing voices that sound highly similar to target speaker's voice given only his or her normal speech samples. We believe that proposed algorithm will open up new opportunities for singing synthesis and conversion for broader users and applications.
PitchNet: Unsupervised Singing Voice Conversion with Pitch Adversarial Network
Dec 04, 2019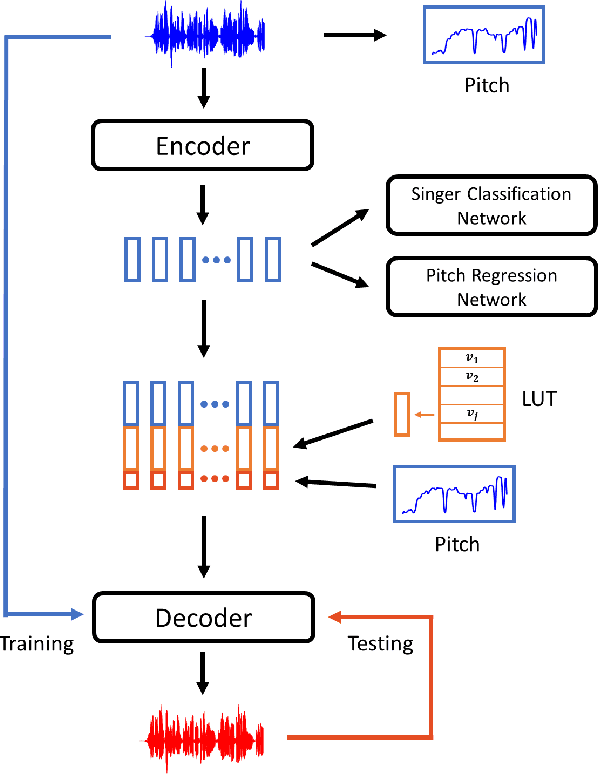
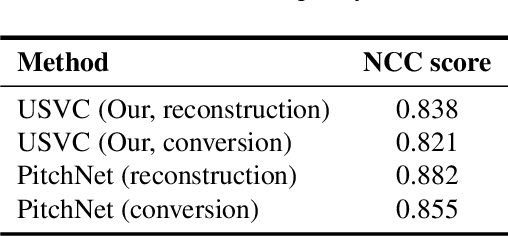
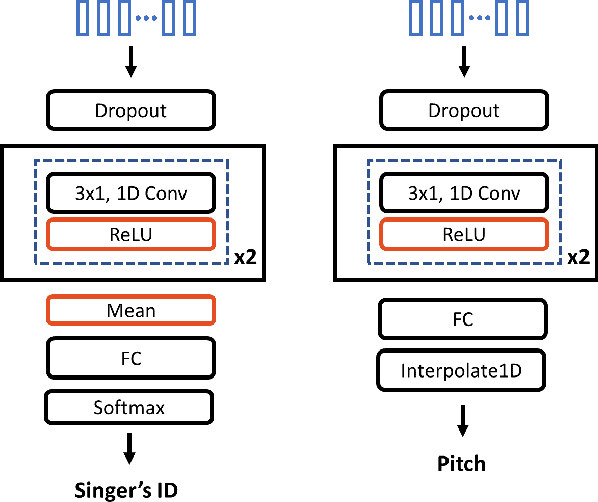
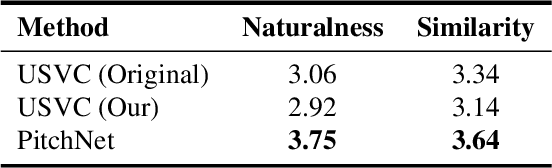
Singing voice conversion is to convert a singer's voice to another one's voice without changing singing content. Recent work shows that unsupervised singing voice conversion can be achieved with an autoencoder-based approach [1]. However, the converted singing voice can be easily out of key, showing that the existing approach can not model the pitch information precisely. In this paper, we propose to advance the existing unsupervised singing voice conversion method proposed in [1] to achieve more accurate pitch translation and flexible pitch manipulation. Specifically, the proposed PitchNet added an adversarially trained pitch regression network to enforce the encoder network to learn pitch invariant phoneme representation, and a separate module to feed pitch extracted from the source audio to the decoder network. Our evaluation shows that the proposed method can greatly improve the quality of the converted singing voice (2.92 vs 3.75 in MOS). We also demonstrate that the pitch of converted singing can be easily controlled during generation by changing the levels of extracted pitch before passing it to the decoder network.
Minimum Bayes Risk Training of RNN-Transducer for End-to-End Speech Recognition
Nov 28, 2019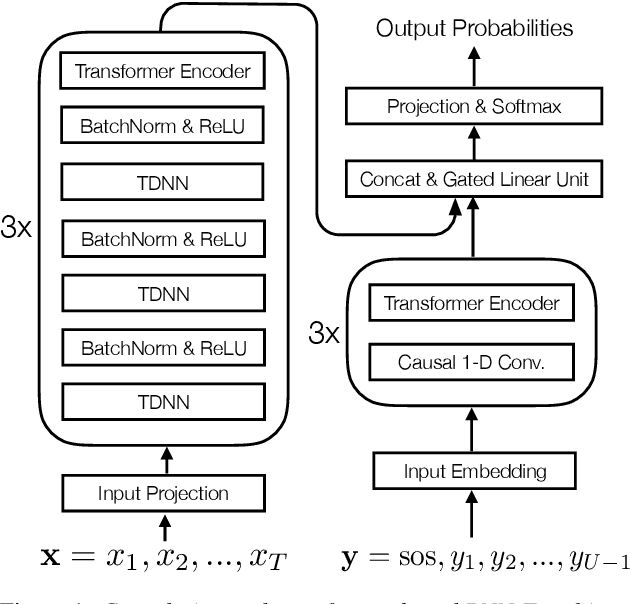
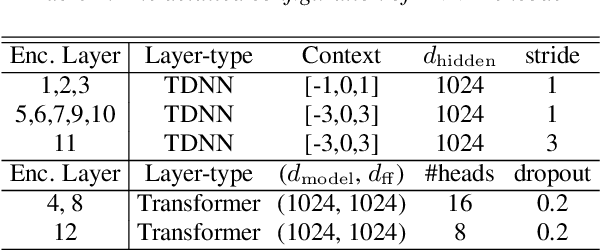
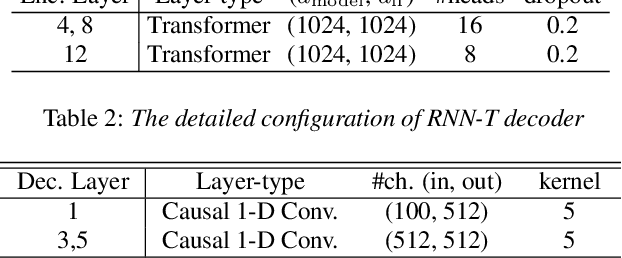
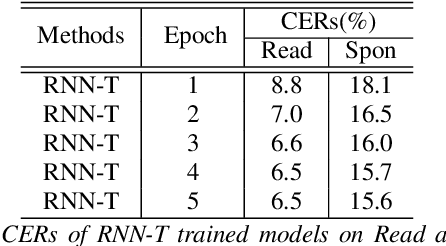
In this work, we propose minimum Bayes risk (MBR) training of RNN-Transducer (RNN-T) for end-to-end speech recognition. Specifically, initialized with a RNN-T trained model, MBR training is conducted via minimizing the expected edit distance between the reference label sequence and on-the-fly generated N-best hypothesis. We also introduce a heuristic to incorporate an external neural network language model (NNLM) in RNN-T beam search decoding and explore MBR training with the external NNLM. Experimental results demonstrate an MBR trained model outperforms a RNN-T trained model substantially and further improvements can be achieved if trained with an external NNLM. Our best MBR trained system achieves absolute character error rate (CER) reductions of 1.2% and 0.5% on read and spontaneous Mandarin speech respectively over a strong convolution and transformer based RNN-T baseline trained on ~21,000 hours of speech.
DurIAN: Duration Informed Attention Network For Multimodal Synthesis
Sep 05, 2019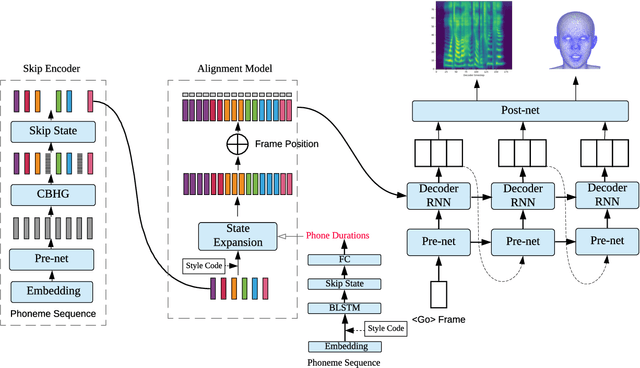
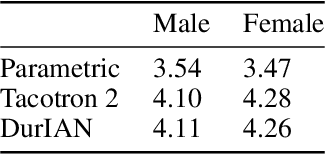
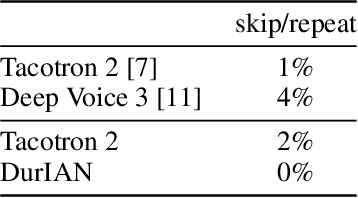
In this paper, we present a generic and robust multimodal synthesis system that produces highly natural speech and facial expression simultaneously. The key component of this system is the Duration Informed Attention Network (DurIAN), an autoregressive model in which the alignments between the input text and the output acoustic features are inferred from a duration model. This is different from the end-to-end attention mechanism used, and accounts for various unavoidable artifacts, in existing end-to-end speech synthesis systems such as Tacotron. Furthermore, DurIAN can be used to generate high quality facial expression which can be synchronized with generated speech with/without parallel speech and face data. To improve the efficiency of speech generation, we also propose a multi-band parallel generation strategy on top of the WaveRNN model. The proposed Multi-band WaveRNN effectively reduces the total computational complexity from 9.8 to 5.5 GFLOPS, and is able to generate audio that is 6 times faster than real time on a single CPU core. We show that DurIAN could generate highly natural speech that is on par with current state of the art end-to-end systems, while at the same time avoid word skipping/repeating errors in those systems. Finally, a simple yet effective approach for fine-grained control of expressiveness of speech and facial expression is introduced.
Unsupervised Speech Recognition via Segmental Empirical Output Distribution Matching
Dec 23, 2018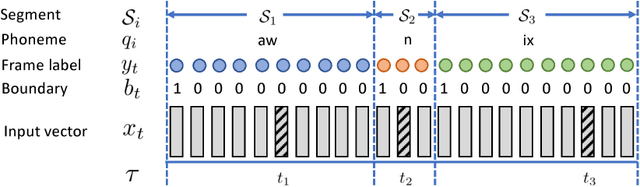
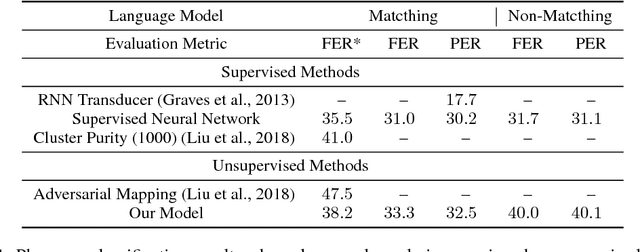
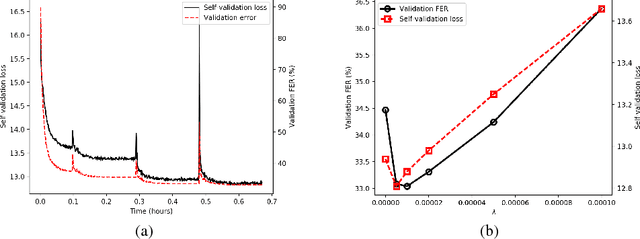
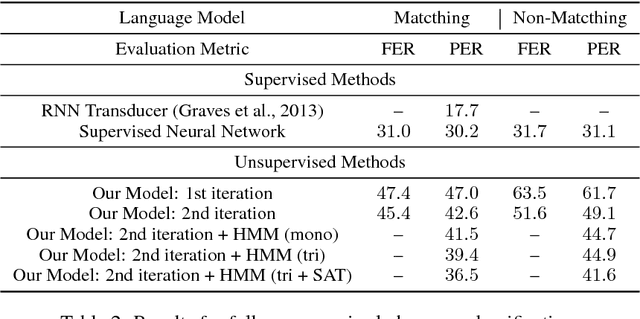
We consider the problem of training speech recognition systems without using any labeled data, under the assumption that the learner can only access to the input utterances and a phoneme language model estimated from a non-overlapping corpus. We propose a fully unsupervised learning algorithm that alternates between solving two sub-problems: (i) learn a phoneme classifier for a given set of phoneme segmentation boundaries, and (ii) refining the phoneme boundaries based on a given classifier. To solve the first sub-problem, we introduce a novel unsupervised cost function named Segmental Empirical Output Distribution Matching, which generalizes the work in (Liu et al., 2017) to segmental structures. For the second sub-problem, we develop an approximate MAP approach to refining the boundaries obtained from Wang et al. (2017). Experimental results on TIMIT dataset demonstrate the success of this fully unsupervised phoneme recognition system, which achieves a phone error rate (PER) of 41.6%. Although it is still far away from the state-of-the-art supervised systems, we show that with oracle boundaries and matching language model, the PER could be improved to 32.5%.This performance approaches the supervised system of the same model architecture, demonstrating the great potential of the proposed method.
UTD-CRSS Systems for 2016 NIST Speaker Recognition Evaluation
Oct 24, 2016
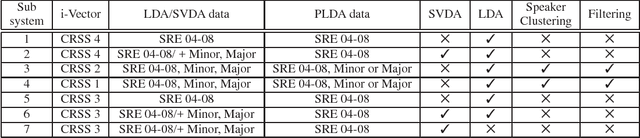
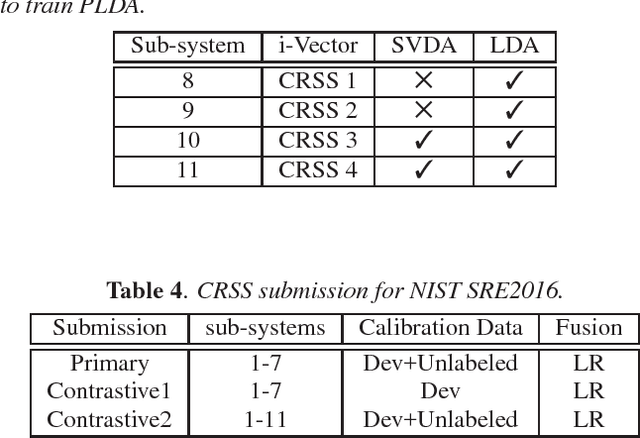
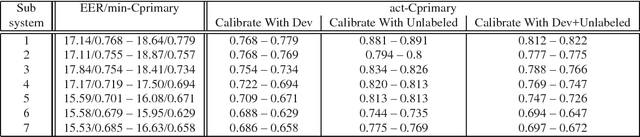
This document briefly describes the systems submitted by the Center for Robust Speech Systems (CRSS) from The University of Texas at Dallas (UTD) to the 2016 National Institute of Standards and Technology (NIST) Speaker Recognition Evaluation (SRE). We developed several UBM and DNN i-Vector based speaker recognition systems with different data sets and feature representations. Given that the emphasis of the NIST SRE 2016 is on language mismatch between training and enrollment/test data, so-called domain mismatch, in our system development we focused on: (1) using unlabeled in-domain data for centralizing data to alleviate the domain mismatch problem, (2) finding the best data set for training LDA/PLDA, (3) using newly proposed dimension reduction technique incorporating unlabeled in-domain data before PLDA training, (4) unsupervised speaker clustering of unlabeled data and using them alone or with previous SREs for PLDA training, (5) score calibration using only unlabeled data and combination of unlabeled and development (Dev) data as separate experiments.