 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating self-supervised features for expressive, multilingual voice conversion
May 13, 2025



Voice conversion (VC) systems are widely used for several applications, from speaker anonymisation to personalised speech synthesis. Supervised approaches learn a mapping between different speakers using parallel data, which is expensive to produce. Unsupervised approaches are typically trained to reconstruct the input signal, which is composed of the content and the speaker information. Disentangling these components is a challenge and often leads to speaker leakage or prosodic information removal. In this paper, we explore voice conversion by leveraging the potential of self-supervised learning (SSL). A combination of the latent representations of SSL models, concatenated with speaker embeddings, is fed to a vocoder which is trained to reconstruct the input. Zero-shot voice conversion results show that this approach allows to keep the prosody and content of the source speaker while matching the speaker similarity of a VC system based on phonetic posteriorgrams (PPGs).
* Published as a conference paper at ICASSP 2024
Enhancing the Stability of LLM-based Speech Generation Systems through Self-Supervised Representations
Feb 05, 2024


Large Language Models (LLMs) are one of the most promising technologies for the next era of speech generation systems, due to their scalability and in-context learning capabilities. Nevertheless, they suffer from multiple stability issues at inference time, such as hallucinations, content skipping or speech repetitions. In this work, we introduce a new self-supervised Voice Conversion (VC) architecture which can be used to learn to encode transitory features, such as content, separately from stationary ones, such as speaker ID or recording conditions, creating speaker-disentangled representations. Using speaker-disentangled codes to train LLMs for text-to-speech (TTS) allows the LLM to generate the content and the style of the speech only from the text, similarly to humans, while the speaker identity is provided by the decoder of the VC model. Results show that LLMs trained over speaker-disentangled self-supervised representations provide an improvement of 4.7pp in speaker similarity over SOTA entangled representations, and a word error rate (WER) 5.4pp lower. Furthermore, they achieve higher naturalness than human recordings of the LibriTTS test-other dataset. Finally, we show that using explicit reference embedding negatively impacts intelligibility (stability), with WER increasing by 14pp compared to the model that only uses text to infer the style.
Creating New Voices using Normalizing Flows
Dec 22, 2023



Creating realistic and natural-sounding synthetic speech remains a big challenge for voice identities unseen during training. As there is growing interest in synthesizing voices of new speakers, here we investigate the ability of normalizing flows in text-to-speech (TTS) and voice conversion (VC) modes to extrapolate from speakers observed during training to create unseen speaker identities. Firstly, we create an approach for TTS and VC, and then we comprehensively evaluate our methods and baselines in terms of intelligibility, naturalness, speaker similarity, and ability to create new voices. We use both objective and subjective metrics to benchmark our techniques on 2 evaluation tasks: zero-shot and new voice speech synthesis. The goal of the former task is to measure the precision of the conversion to an unseen voice. The goal of the latter is to measure the ability to create new voices. Extensive evaluations demonstrate that the proposed approach systematically allows to obtain state-of-the-art performance in zero-shot speech synthesis and creates various new voices, unobserved in the training set. We consider this work to be the first attempt to synthesize new voices based on mel-spectrograms and normalizing flows, along with a comprehensive analysis and comparison of the TTS and VC modes.
* Interspeech 2022
Comparing normalizing flows and diffusion models for prosody and acoustic modelling in text-to-speech
Jul 31, 2023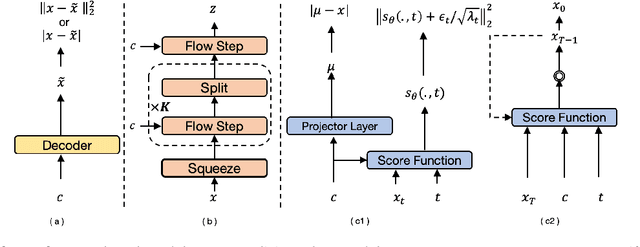
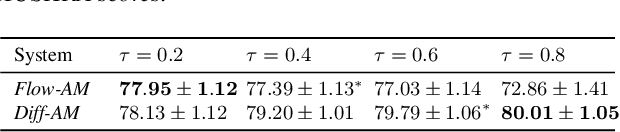
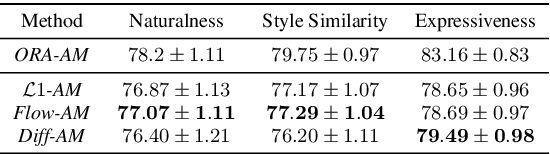
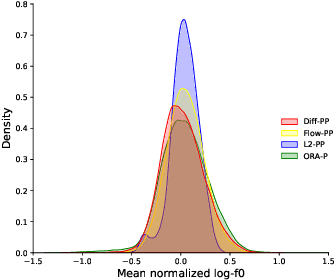
Neural text-to-speech systems are often optimized on L1/L2 losses, which make strong assumptions about the distributions of the target data space. Aiming to improve those assumptions, Normalizing Flows and Diffusion Probabilistic Models were recently proposed as alternatives. In this paper, we compare traditional L1/L2-based approaches to diffusion and flow-based approaches for the tasks of prosody and mel-spectrogram prediction for text-to-speech synthesis. We use a prosody model to generate log-f0 and duration features, which are used to condition an acoustic model that generates mel-spectrograms. Experimental results demonstrate that the flow-based model achieves the best performance for spectrogram prediction, improving over equivalent diffusion and L1 models. Meanwhile, both diffusion and flow-based prosody predictors result in significant improvements over a typical L2-trained prosody models.
SCRAPS: Speech Contrastive Representations of Acoustic and Phonetic Spaces
Jul 23, 2023



Numerous examples in the literature proved that deep learning models have the ability to work well with multimodal data. Recently, CLIP has enabled deep learning systems to learn shared latent spaces between images and text descriptions, with outstanding zero- or few-shot results in downstream tasks. In this paper we explore the same idea proposed by CLIP but applied to the speech domain, where the phonetic and acoustic spaces usually coexist. We train a CLIP-based model with the aim to learn shared representations of phonetic and acoustic spaces. The results show that the proposed model is sensible to phonetic changes, with a 91% of score drops when replacing 20% of the phonemes at random, while providing substantial robustness against different kinds of noise, with a 10% performance drop when mixing the audio with 75% of Gaussian noise. We also provide empirical evidence showing that the resulting embeddings are useful for a variety of downstream applications, such as intelligibility evaluation and the ability to leverage rich pre-trained phonetic embeddings in speech generation task. Finally, we discuss potential applications with interesting implications for the speech generation and recognition fields.
Remap, warp and attend: Non-parallel many-to-many accent conversion with Normalizing Flows
Nov 10, 2022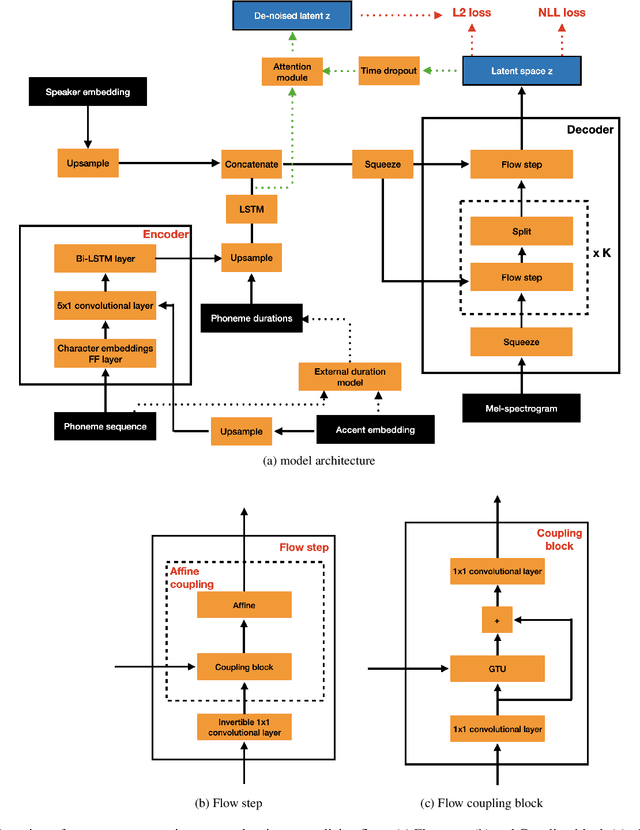

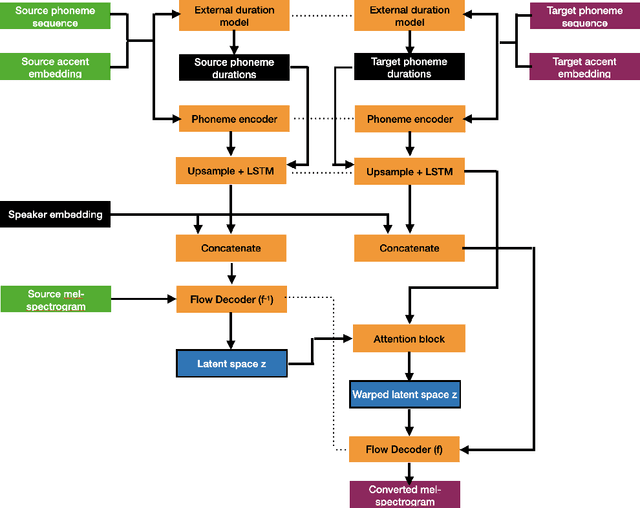

Regional accents of the same language affect not only how words are pronounced (i.e., phonetic content), but also impact prosodic aspects of speech such as speaking rate and intonation. This paper investigates a novel flow-based approach to accent conversion using normalizing flows. The proposed approach revolves around three steps: remapping the phonetic conditioning, to better match the target accent, warping the duration of the converted speech, to better suit the target phonemes, and an attention mechanism that implicitly aligns source and target speech sequences. The proposed remap-warp-attend system enables adaptation of both phonetic and prosodic aspects of speech while allowing for source and converted speech signals to be of different lengths. Objective and subjective evaluations show that the proposed approach significantly outperforms a competitive CopyCat baseline model in terms of similarity to the target accent, naturalness and intelligibility.
Stutter-TTS: Controlled Synthesis and Improved Recognition of Stuttered Speech
Nov 04, 2022



Stuttering is a speech disorder where the natural flow of speech is interrupted by blocks, repetitions or prolongations of syllables, words and phrases. The majority of existing automatic speech recognition (ASR) interfaces perform poorly on utterances with stutter, mainly due to lack of matched training data. Synthesis of speech with stutter thus presents an opportunity to improve ASR for this type of speech. We describe Stutter-TTS, an end-to-end neural text-to-speech model capable of synthesizing diverse types of stuttering utterances. We develop a simple, yet effective prosody-control strategy whereby additional tokens are introduced into source text during training to represent specific stuttering characteristics. By choosing the position of the stutter tokens, Stutter-TTS allows word-level control of where stuttering occurs in the synthesized utterance. We are able to synthesize stutter events with high accuracy (F1-scores between 0.63 and 0.84, depending on stutter type). By fine-tuning an ASR model on synthetic stuttered speech we are able to reduce word error by 5.7% relative on stuttered utterances, with only minor (<0.2% relative) degradation for fluent utterances.
* 8 pages, 3 figures, 2 tables
GlowVC: Mel-spectrogram space disentangling model for language-independent text-free voice conversion
Jul 04, 2022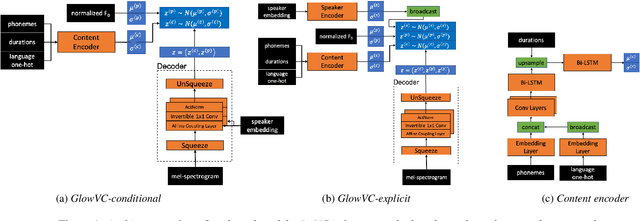

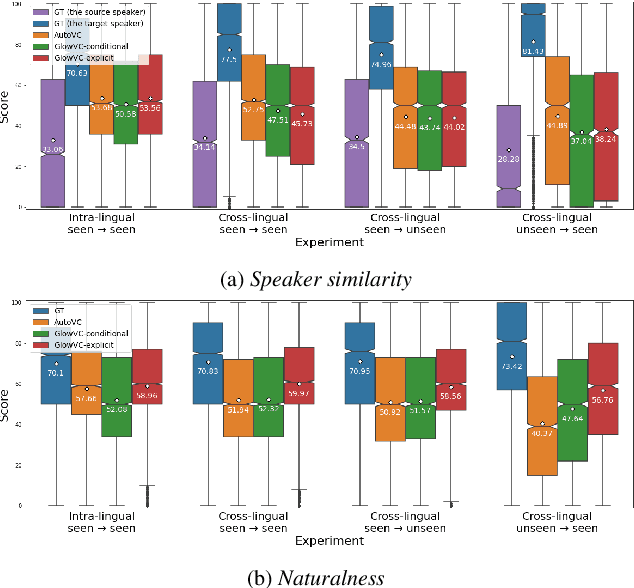
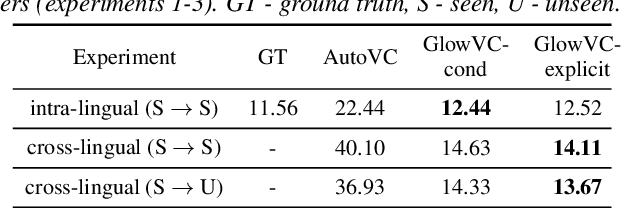
In this paper, we propose GlowVC: a multilingual multi-speaker flow-based model for language-independent text-free voice conversion. We build on Glow-TTS, which provides an architecture that enables use of linguistic features during training without the necessity of using them for VC inference. We consider two versions of our model: GlowVC-conditional and GlowVC-explicit. GlowVC-conditional models the distribution of mel-spectrograms with speaker-conditioned flow and disentangles the mel-spectrogram space into content- and pitch-relevant dimensions, while GlowVC-explicit models the explicit distribution with unconditioned flow and disentangles said space into content-, pitch- and speaker-relevant dimensions. We evaluate our models in terms of intelligibility, speaker similarity and naturalness for intra- and cross-lingual conversion in seen and unseen languages. GlowVC models greatly outperform AutoVC baseline in terms of intelligibility, while achieving just as high speaker similarity in intra-lingual VC, and slightly worse in the cross-lingual setting. Moreover, we demonstrate that GlowVC-explicit surpasses both GlowVC-conditional and AutoVC in terms of naturalness.
Prosodic Alignment for off-screen automatic dubbing
Apr 06, 2022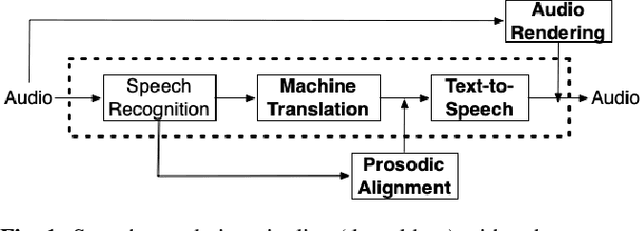

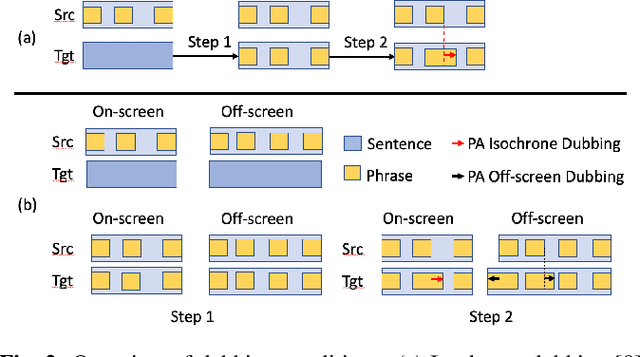
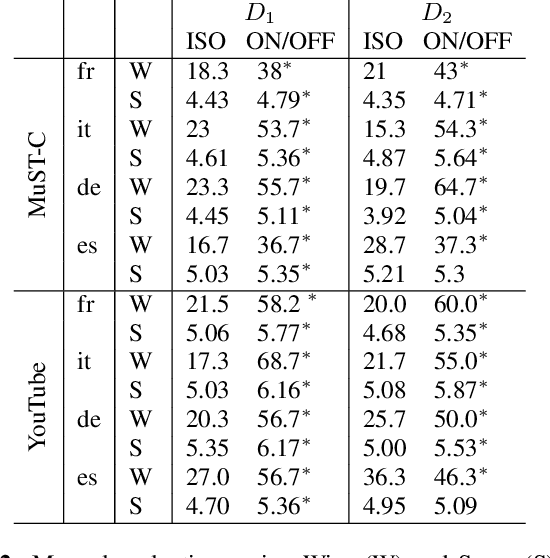
The goal of automatic dubbing is to perform speech-to-speech translation while achieving audiovisual coherence. This entails isochrony, i.e., translating the original speech by also matching its prosodic structure into phrases and pauses, especially when the speaker's mouth is visible. In previous work, we introduced a prosodic alignment model to address isochrone or on-screen dubbing. In this work, we extend the prosodic alignment model to also address off-screen dubbing that requires less stringent synchronization constraints. We conduct experiments on four dubbing directions - English to French, Italian, German and Spanish - on a publicly available collection of TED Talks and on publicly available YouTube videos. Empirical results show that compared to our previous work the extended prosodic alignment model provides significantly better subjective viewing experience on videos in which on-screen and off-screen automatic dubbing is applied for sentences with speakers mouth visible and not visible, respectively.
Text-free non-parallel many-to-many voice conversion using normalising flows
Mar 15, 2022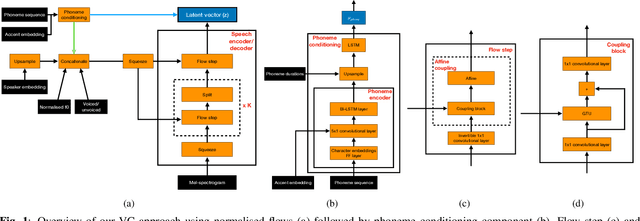
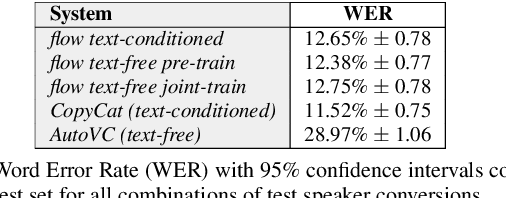
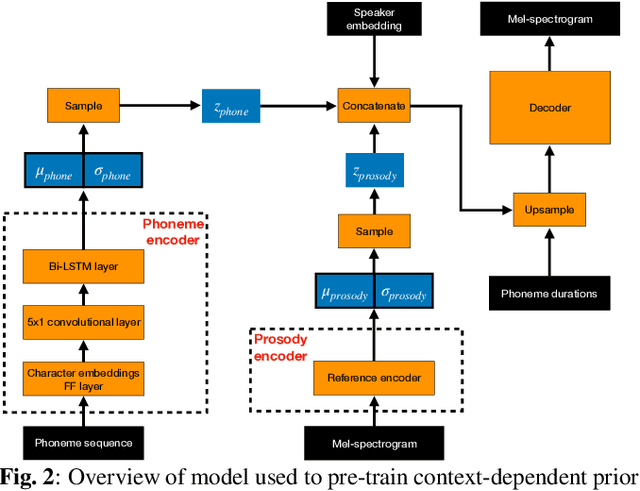
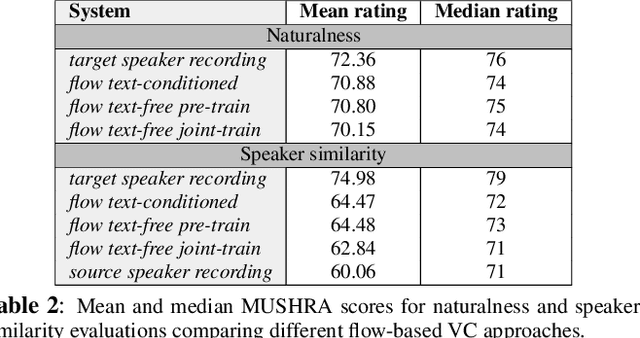
Non-parallel voice conversion (VC) is typically achieved using lossy representations of the source speech. However, ensuring only speaker identity information is dropped whilst all other information from the source speech is retained is a large challenge. This is particularly challenging in the scenario where at inference-time we have no knowledge of the text being read, i.e., text-free VC. To mitigate this, we investigate information-preserving VC approaches. Normalising flows have gained attention for text-to-speech synthesis, however have been under-explored for VC. Flows utilize invertible functions to learn the likelihood of the data, thus provide a lossless encoding of speech. We investigate normalising flows for VC in both text-conditioned and text-free scenarios. Furthermore, for text-free VC we compare pre-trained and jointly-learnt priors. Flow-based VC evaluations show no degradation between text-free and text-conditioned VC, resulting in improvements over the state-of-the-art. Also, joint-training of the prior is found to negatively impact text-free VC quality.