 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing normalizing flows and diffusion models for prosody and acoustic modelling in text-to-speech
Jul 31, 2023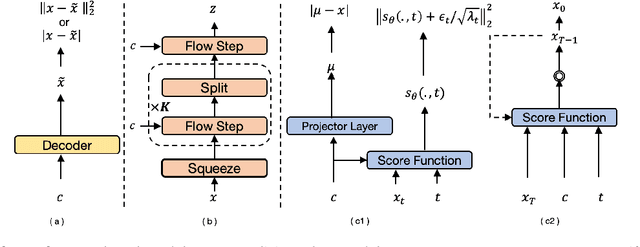
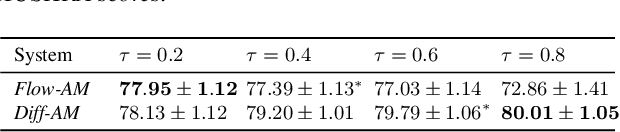
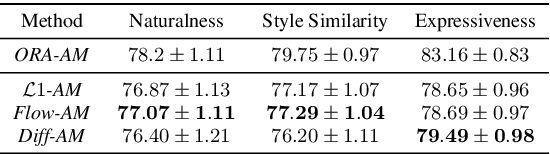
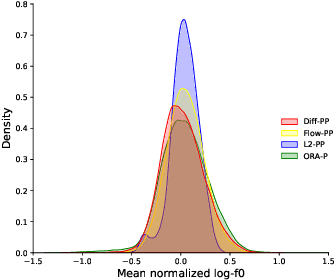
Neural text-to-speech systems are often optimized on L1/L2 losses, which make strong assumptions about the distributions of the target data space. Aiming to improve those assumptions, Normalizing Flows and Diffusion Probabilistic Models were recently proposed as alternatives. In this paper, we compare traditional L1/L2-based approaches to diffusion and flow-based approaches for the tasks of prosody and mel-spectrogram prediction for text-to-speech synthesis. We use a prosody model to generate log-f0 and duration features, which are used to condition an acoustic model that generates mel-spectrograms. Experimental results demonstrate that the flow-based model achieves the best performance for spectrogram prediction, improving over equivalent diffusion and L1 models. Meanwhile, both diffusion and flow-based prosody predictors result in significant improvements over a typical L2-trained prosody models.
Improving grapheme-to-phoneme conversion by learning pronunciations from speech recordings
Jul 31, 2023The Grapheme-to-Phoneme (G2P) task aims to convert orthographic input into a discrete phonetic representation. G2P conversion is beneficial to various speech processing applications, such as text-to-speech and speech recognition. However, these tend to rely on manually-annotated pronunciation dictionaries, which are often time-consuming and costly to acquire. In this paper, we propose a method to improve the G2P conversion task by learning pronunciation examples from audio recordings. Our approach bootstraps a G2P with a small set of annotated examples. The G2P model is used to train a multilingual phone recognition system, which then decodes speech recordings with a phonetic representation. Given hypothesized phoneme labels, we learn pronunciation dictionaries for out-of-vocabulary words, and we use those to re-train the G2P system. Results indicate that our approach consistently improves the phone error rate of G2P systems across languages and amount of available data.
Multilingual context-based pronunciation learning for Text-to-Speech
Jul 31, 2023Phonetic information and linguistic knowledge are an essential component of a Text-to-speech (TTS) front-end. Given a language, a lexicon can be collected offline and Grapheme-to-Phoneme (G2P) relationships are usually modeled in order to predict the pronunciation for out-of-vocabulary (OOV) words. Additionally, post-lexical phonology, often defined in the form of rule-based systems, is used to correct pronunciation within or between words. In this work we showcase a multilingual unified front-end system that addresses any pronunciation related task, typically handled by separate modules. We evaluate the proposed model on G2P conversion and other language-specific challenges, such as homograph and polyphones disambiguation, post-lexical rules and implicit diacritization. We find that the multilingual model is competitive across languages and tasks, however, some trade-offs exists when compared to equivalent monolingual solutions.
Predicting pairwise preferences between TTS audio stimuli using parallel ratings data and anti-symmetric twin neural networks
Sep 22, 2022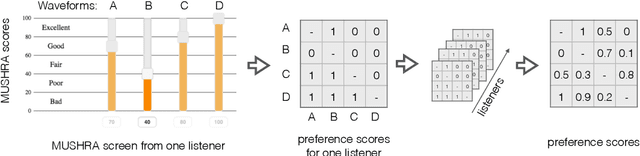
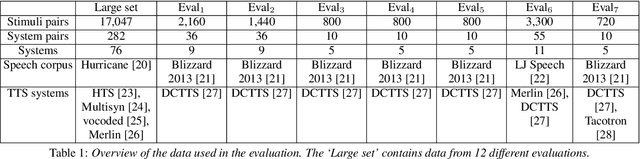
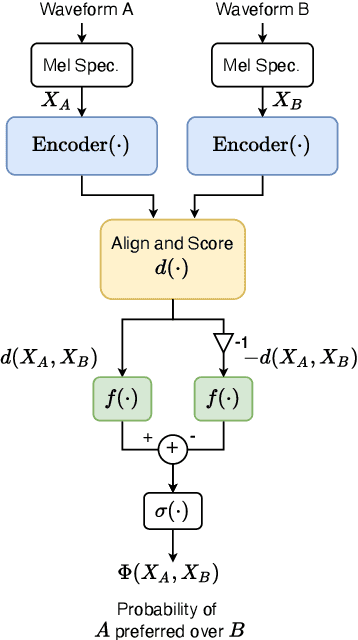
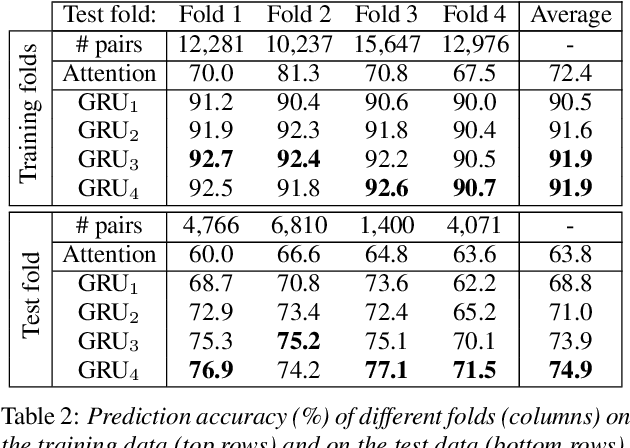
Automatically predicting the outcome of subjective listening tests is a challenging task. Ratings may vary from person to person even if preferences are consistent across listeners. While previous work has focused on predicting listeners' ratings (mean opinion scores) of individual stimuli, we focus on the simpler task of predicting subjective preference given two speech stimuli for the same text. We propose a model based on anti-symmetric twin neural networks, trained on pairs of waveforms and their corresponding preference scores. We explore both attention and recurrent neural nets to account for the fact that stimuli in a pair are not time aligned. To obtain a large training set we convert listeners' ratings from MUSHRA tests to values that reflect how often one stimulus in the pair was rated higher than the other. Specifically, we evaluate performance on data obtained from twelve MUSHRA evaluations conducted over five years, containing different TTS systems, built from data of different speakers. Our results compare favourably to a state-of-the-art model trained to predict MOS scores.
Low-data? No problem: low-resource, language-agnostic conversational text-to-speech via F0-conditioned data augmentation
Jul 29, 2022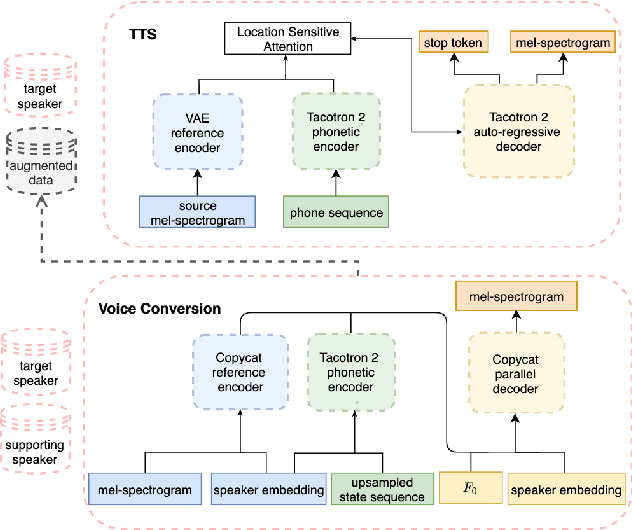

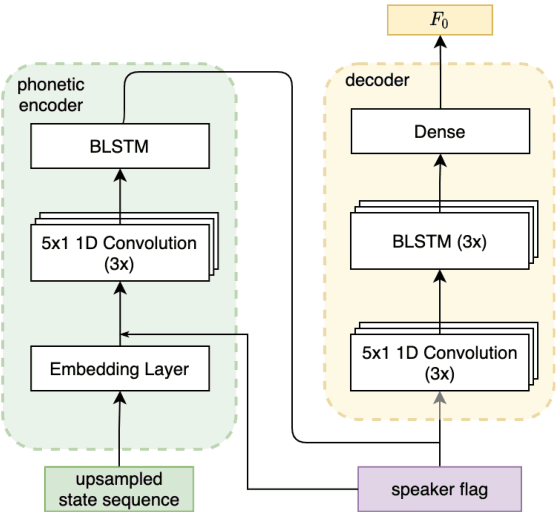
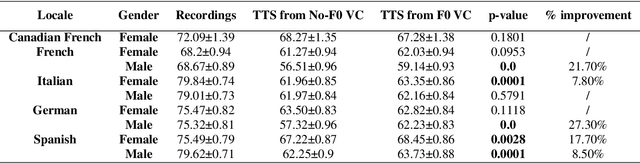
The availability of data in expressive styles across languages is limited, and recording sessions are costly and time consuming. To overcome these issues, we demonstrate how to build low-resource, neural text-to-speech (TTS) voices with only 1 hour of conversational speech, when no other conversational data are available in the same language. Assuming the availability of non-expressive speech data in that language, we propose a 3-step technology: 1) we train an F0-conditioned voice conversion (VC) model as data augmentation technique; 2) we train an F0 predictor to control the conversational flavour of the voice-converted synthetic data; 3) we train a TTS system that consumes the augmented data. We prove that our technology enables F0 controllability, is scalable across speakers and languages and is competitive in terms of naturalness over a state-of-the-art baseline model, another augmented method which does not make use of F0 information.
Voice Filter: Few-shot text-to-speech speaker adaptation using voice conversion as a post-processing module
Feb 16, 2022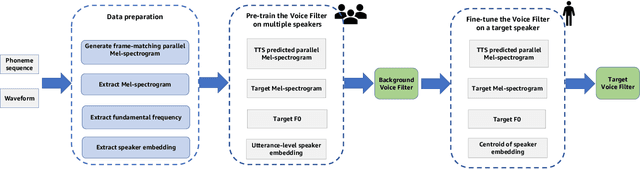

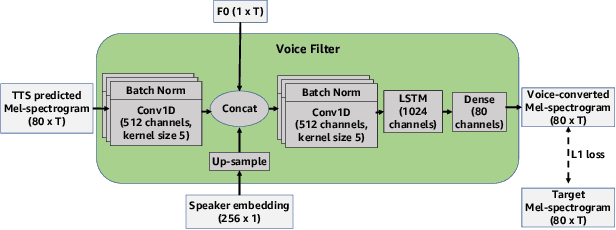

State-of-the-art text-to-speech (TTS) systems require several hours of recorded speech data to generate high-quality synthetic speech. When using reduced amounts of training data, standard TTS models suffer from speech quality and intelligibility degradations, making training low-resource TTS systems problematic. In this paper, we propose a novel extremely low-resource TTS method called Voice Filter that uses as little as one minute of speech from a target speaker. It uses voice conversion (VC) as a post-processing module appended to a pre-existing high-quality TTS system and marks a conceptual shift in the existing TTS paradigm, framing the few-shot TTS problem as a VC task. Furthermore, we propose to use a duration-controllable TTS system to create a parallel speech corpus to facilitate the VC task. Results show that the Voice Filter outperforms state-of-the-art few-shot speech synthesis techniques in terms of objective and subjective metrics on one minute of speech on a diverse set of voices, while being competitive against a TTS model built on 30 times more data.
Cross-speaker style transfer for text-to-speech using data augmentation
Feb 10, 2022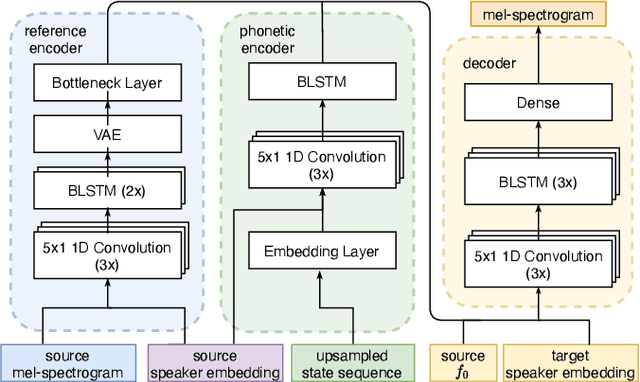
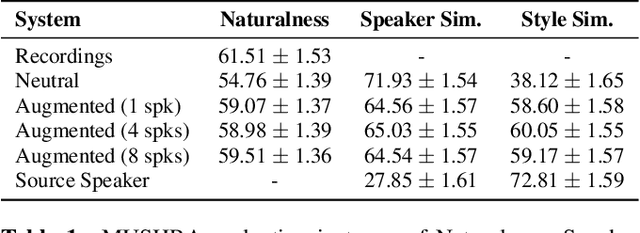
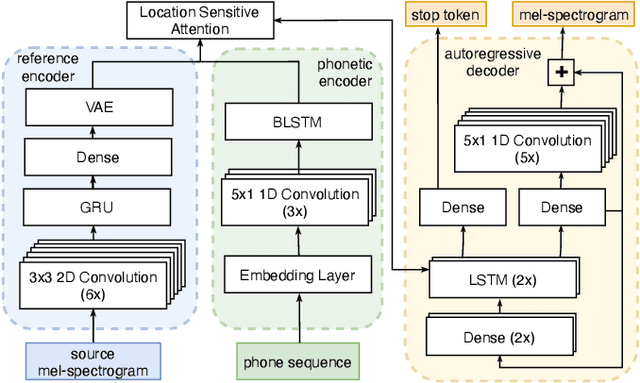
We address the problem of cross-speaker style transfer for text-to-speech (TTS) using data augmentation via voice conversion. We assume to have a corpus of neutral non-expressive data from a target speaker and supporting conversational expressive data from different speakers. Our goal is to build a TTS system that is expressive, while retaining the target speaker's identity. The proposed approach relies on voice conversion to first generate high-quality data from the set of supporting expressive speakers. The voice converted data is then pooled with natural data from the target speaker and used to train a single-speaker multi-style TTS system. We provide evidence that this approach is efficient, flexible, and scalable. The method is evaluated using one or more supporting speakers, as well as a variable amount of supporting data. We further provide evidence that this approach allows some controllability of speaking style, when using multiple supporting speakers. We conclude by scaling our proposed technology to a set of 14 speakers across 7 languages. Results indicate that our technology consistently improves synthetic samples in terms of style similarity, while retaining the target speaker's identity.
Automatic audiovisual synchronisation for ultrasound tongue imaging
May 31, 2021

Ultrasound tongue imaging is used to visualise the intra-oral articulators during speech production. It is utilised in a range of applications, including speech and language therapy and phonetics research. Ultrasound and speech audio are recorded simultaneously, and in order to correctly use this data, the two modalities should be correctly synchronised. Synchronisation is achieved using specialised hardware at recording time, but this approach can fail in practice resulting in data of limited usability. In this paper, we address the problem of automatically synchronising ultrasound and audio after data collection. We first investigate the tolerance of expert ultrasound users to synchronisation errors in order to find the thresholds for error detection. We use these thresholds to define accuracy scoring boundaries for evaluating our system. We then describe our approach for automatic synchronisation, which is driven by a self-supervised neural network, exploiting the correlation between the two signals to synchronise them. We train our model on data from multiple domains with different speaker characteristics, different equipment, and different recording environments, and achieve an accuracy >92.4% on held-out in-domain data. Finally, we introduce a novel resource, the Cleft dataset, which we gathered with a new clinical subgroup and for which hardware synchronisation proved unreliable. We apply our model to this out-of-domain data, and evaluate its performance subjectively with expert users. Results show that users prefer our model's output over the original hardware output 79.3% of the time. Our results demonstrate the strength of our approach and its ability to generalise to data from new domains.
Silent versus modal multi-speaker speech recognition from ultrasound and video
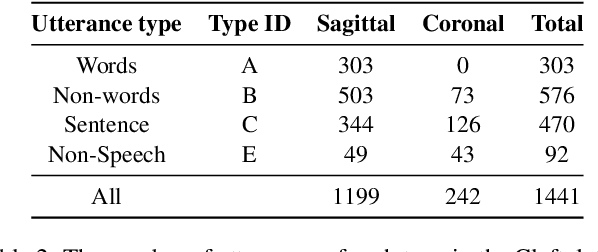
Feb 27, 2021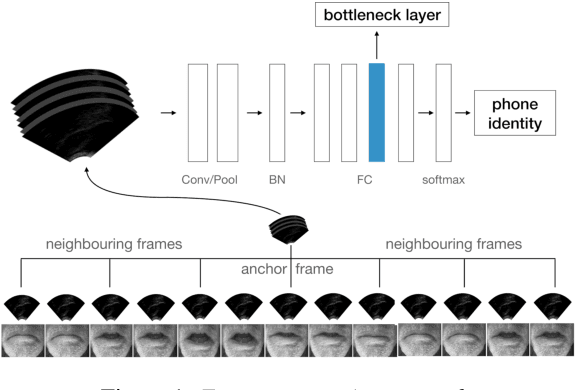
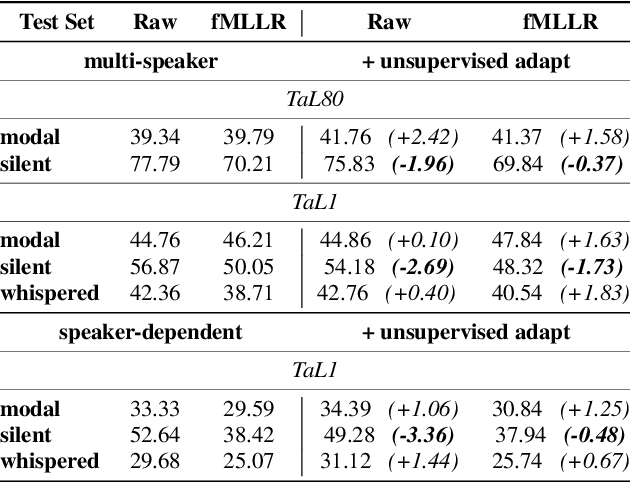
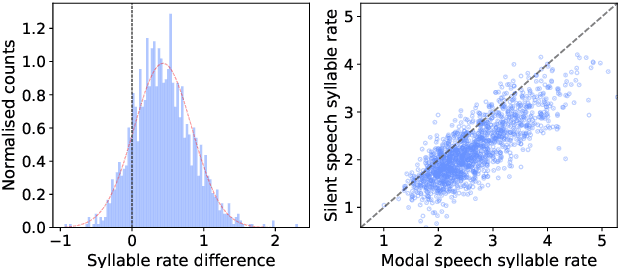

We investigate multi-speaker speech recognition from ultrasound images of the tongue and video images of the lips. We train our systems on imaging data from modal speech, and evaluate on matched test sets of two speaking modes: silent and modal speech. We observe that silent speech recognition from imaging data underperforms compared to modal speech recognition, likely due to a speaking-mode mismatch between training and testing. We improve silent speech recognition performance using techniques that address the domain mismatch, such as fMLLR and unsupervised model adaptation. We also analyse the properties of silent and modal speech in terms of utterance duration and the size of the articulatory space. To estimate the articulatory space, we compute the convex hull of tongue splines, extracted from ultrasound tongue images. Overall, we observe that the duration of silent speech is longer than that of modal speech, and that silent speech covers a smaller articulatory space than modal speech. Although these two properties are statistically significant across speaking modes, they do not directly correlate with word error rates from speech recognition.
Exploiting ultrasound tongue imaging for the automatic detection of speech articulation errors
Feb 27, 2021

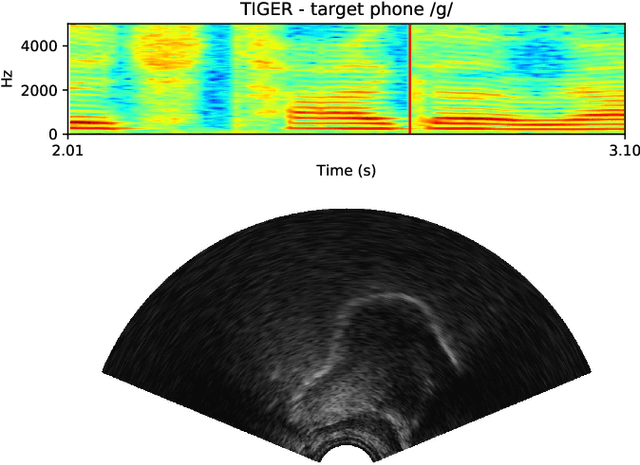
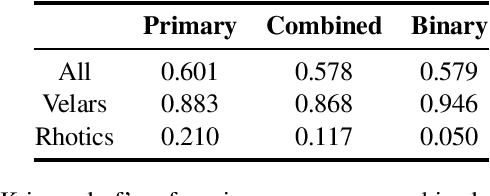
Speech sound disorders are a common communication impairment in childhood. Because speech disorders can negatively affect the lives and the development of children, clinical intervention is often recommended. To help with diagnosis and treatment, clinicians use instrumented methods such as spectrograms or ultrasound tongue imaging to analyse speech articulations. Analysis with these methods can be laborious for clinicians, therefore there is growing interest in its automation. In this paper, we investigate the contribution of ultrasound tongue imaging for the automatic detection of speech articulation errors. Our systems are trained on typically developing child speech and augmented with a database of adult speech using audio and ultrasound. Evaluation on typically developing speech indicates that pre-training on adult speech and jointly using ultrasound and audio gives the best results with an accuracy of 86.9%. To evaluate on disordered speech, we collect pronunciation scores from experienced speech and language therapists, focusing on cases of velar fronting and gliding of /r/. The scores show good inter-annotator agreement for velar fronting, but not for gliding errors. For automatic velar fronting error detection, the best results are obtained when jointly using ultrasound and audio. The best system correctly detects 86.6% of the errors identified by experienced clinicians. Out of all the segments identified as errors by the best system, 73.2% match errors identified by clinicians. Results on automatic gliding detection are harder to interpret due to poor inter-annotator agreement, but appear promising. Overall findings suggest that automatic detection of speech articulation errors has potential to be integrated into ultrasound intervention software for automatically quantifying progress during speech therapy.
* 15 pages, 9 figures, 6 tables