 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonetic Error Analysis of Raw Waveform Acoustic Models with Parametric and Non-Parametric CNNs
Jun 02, 2024

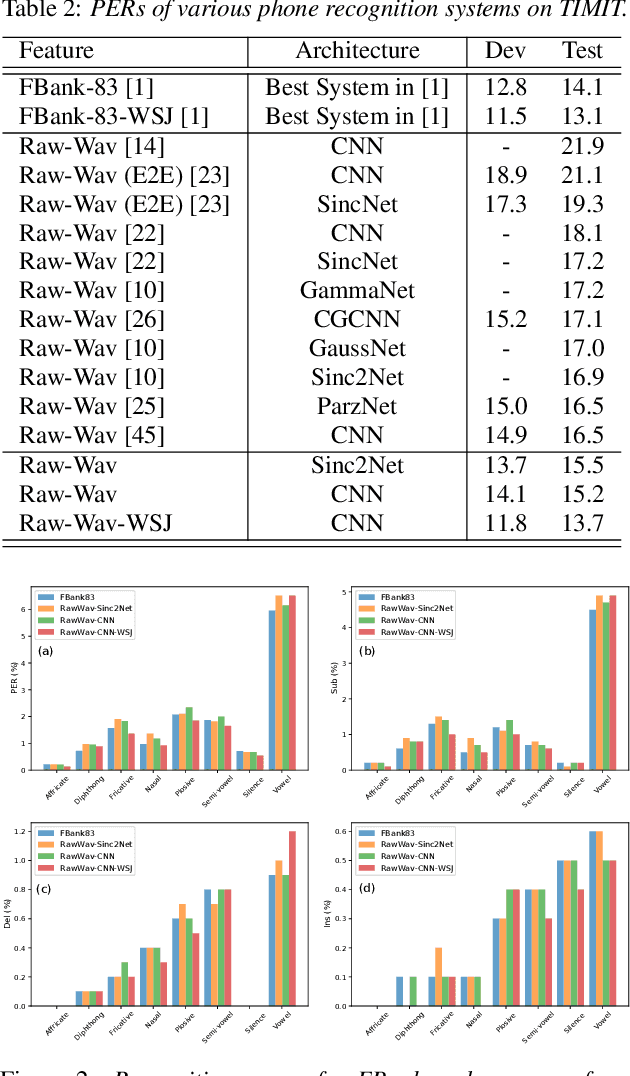

In this paper, we analyse the error patterns of the raw waveform acoustic models in TIMIT's phone recognition task. Our analysis goes beyond the conventional phone error rate (PER) metric. We categorise the phones into three groups: {affricate, diphthong, fricative, nasal, plosive, semi-vowel, vowel, silence}, {consonant, vowel+, silence}, and {voiced, unvoiced, silence} and, compute the PER for each broad phonetic class in each category. We also construct a confusion matrix for each category using the substitution errors and compare the confusion patterns with those of the Filterbank and Wav2vec 2.0 systems. Our raw waveform acoustic models consists of parametric (Sinc2Net) or non-parametric CNNs and Bidirectional LSTMs, achieving down to 13.7%/15.2% PERs on TIMIT Dev/Test sets, outperforming reported PERs for raw waveform models in the literature. We also investigate the impact of transfer learning from WSJ on the phonetic error patterns and confusion matrices. It reduces the PER to 11.8%/13.7% on the Dev/Test sets.
Towards Robust Waveform-Based Acoustic Models
Oct 16, 2021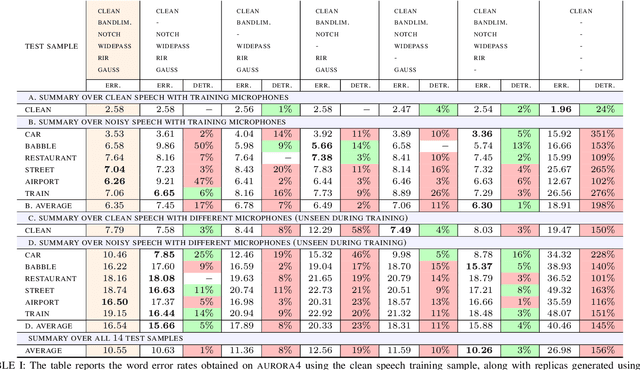
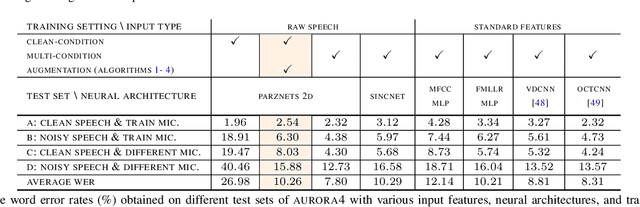
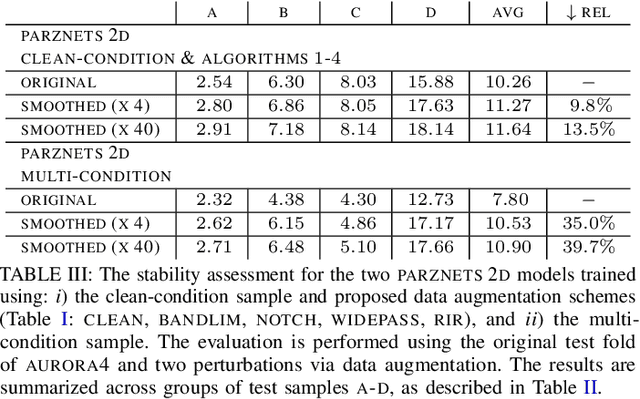
We propose an approach for learning robust acoustic models in adverse environments, characterized by a significant mismatch between training and test conditions. This problem is of paramount importance for the deployment of speech recognition systems that need to perform well in unseen environments. Our approach is an instance of vicinal risk minimization, which aims to improve risk estimates during training by replacing the delta functions that define the empirical density over the input space with an approximation of the marginal population density in the vicinity of the training samples. More specifically, we assume that local neighborhoods centered at training samples can be approximated using a mixture of Gaussians, and demonstrate theoretically that this can incorporate robust inductive bias into the learning process. We characterize the individual mixture components implicitly via data augmentation schemes, designed to address common sources of spurious correlations in acoustic models. To avoid potential confounding effects on robustness due to information loss, which has been associated with standard feature extraction techniques (e.g., FBANK and MFCC features), we focus our evaluation on the waveform-based setting. Our empirical results show that the proposed approach can generalize to unseen noise conditions, with 150% relative improvement in out-of-distribution generalization compared to training using the standard risk minimization principle. Moreover, the results demonstrate competitive performance relative to models learned using a training sample designed to match the acoustic conditions characteristic of test utterances (i.e., optimal vicinal densities).
Automatic audiovisual synchronisation for ultrasound tongue imaging
May 31, 2021

Ultrasound tongue imaging is used to visualise the intra-oral articulators during speech production. It is utilised in a range of applications, including speech and language therapy and phonetics research. Ultrasound and speech audio are recorded simultaneously, and in order to correctly use this data, the two modalities should be correctly synchronised. Synchronisation is achieved using specialised hardware at recording time, but this approach can fail in practice resulting in data of limited usability. In this paper, we address the problem of automatically synchronising ultrasound and audio after data collection. We first investigate the tolerance of expert ultrasound users to synchronisation errors in order to find the thresholds for error detection. We use these thresholds to define accuracy scoring boundaries for evaluating our system. We then describe our approach for automatic synchronisation, which is driven by a self-supervised neural network, exploiting the correlation between the two signals to synchronise them. We train our model on data from multiple domains with different speaker characteristics, different equipment, and different recording environments, and achieve an accuracy >92.4% on held-out in-domain data. Finally, we introduce a novel resource, the Cleft dataset, which we gathered with a new clinical subgroup and for which hardware synchronisation proved unreliable. We apply our model to this out-of-domain data, and evaluate its performance subjectively with expert users. Results show that users prefer our model's output over the original hardware output 79.3% of the time. Our results demonstrate the strength of our approach and its ability to generalise to data from new domains.
Silent versus modal multi-speaker speech recognition from ultrasound and video
Feb 27, 2021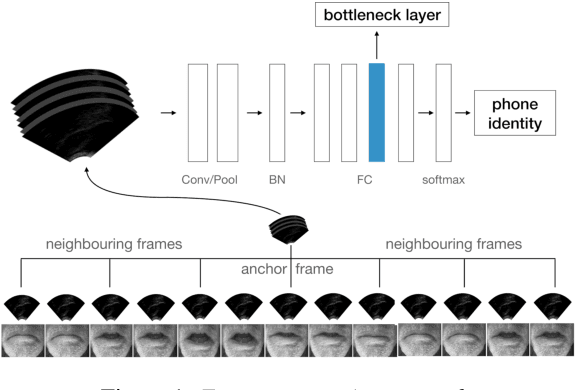
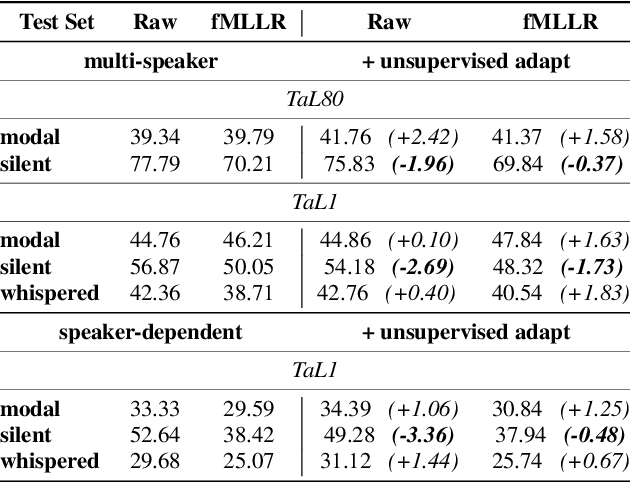
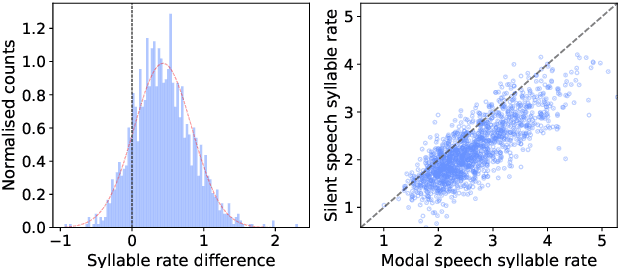

We investigate multi-speaker speech recognition from ultrasound images of the tongue and video images of the lips. We train our systems on imaging data from modal speech, and evaluate on matched test sets of two speaking modes: silent and modal speech. We observe that silent speech recognition from imaging data underperforms compared to modal speech recognition, likely due to a speaking-mode mismatch between training and testing. We improve silent speech recognition performance using techniques that address the domain mismatch, such as fMLLR and unsupervised model adaptation. We also analyse the properties of silent and modal speech in terms of utterance duration and the size of the articulatory space. To estimate the articulatory space, we compute the convex hull of tongue splines, extracted from ultrasound tongue images. Overall, we observe that the duration of silent speech is longer than that of modal speech, and that silent speech covers a smaller articulatory space than modal speech. Although these two properties are statistically significant across speaking modes, they do not directly correlate with word error rates from speech recognition.
Exploiting ultrasound tongue imaging for the automatic detection of speech articulation errors
Feb 27, 2021

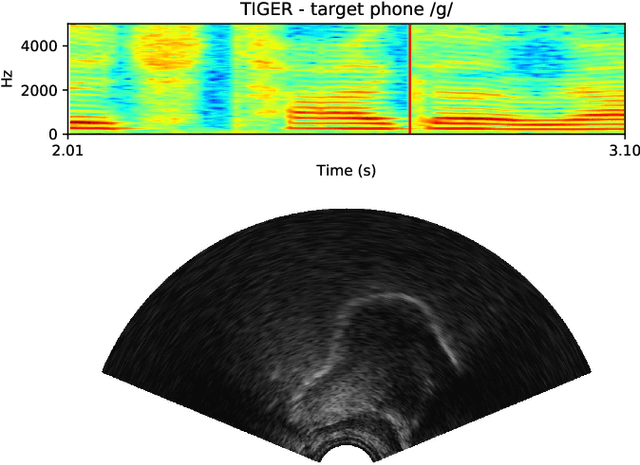
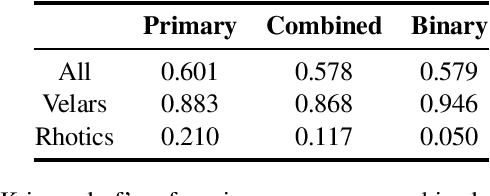
Speech sound disorders are a common communication impairment in childhood. Because speech disorders can negatively affect the lives and the development of children, clinical intervention is often recommended. To help with diagnosis and treatment, clinicians use instrumented methods such as spectrograms or ultrasound tongue imaging to analyse speech articulations. Analysis with these methods can be laborious for clinicians, therefore there is growing interest in its automation. In this paper, we investigate the contribution of ultrasound tongue imaging for the automatic detection of speech articulation errors. Our systems are trained on typically developing child speech and augmented with a database of adult speech using audio and ultrasound. Evaluation on typically developing speech indicates that pre-training on adult speech and jointly using ultrasound and audio gives the best results with an accuracy of 86.9%. To evaluate on disordered speech, we collect pronunciation scores from experienced speech and language therapists, focusing on cases of velar fronting and gliding of /r/. The scores show good inter-annotator agreement for velar fronting, but not for gliding errors. For automatic velar fronting error detection, the best results are obtained when jointly using ultrasound and audio. The best system correctly detects 86.6% of the errors identified by experienced clinicians. Out of all the segments identified as errors by the best system, 73.2% match errors identified by clinicians. Results on automatic gliding detection are harder to interpret due to poor inter-annotator agreement, but appear promising. Overall findings suggest that automatic detection of speech articulation errors has potential to be integrated into ultrasound intervention software for automatically quantifying progress during speech therapy.
* 15 pages, 9 figures, 6 tables
Train your classifier first: Cascade Neural Networks Training from upper layers to lower layers
Feb 09, 2021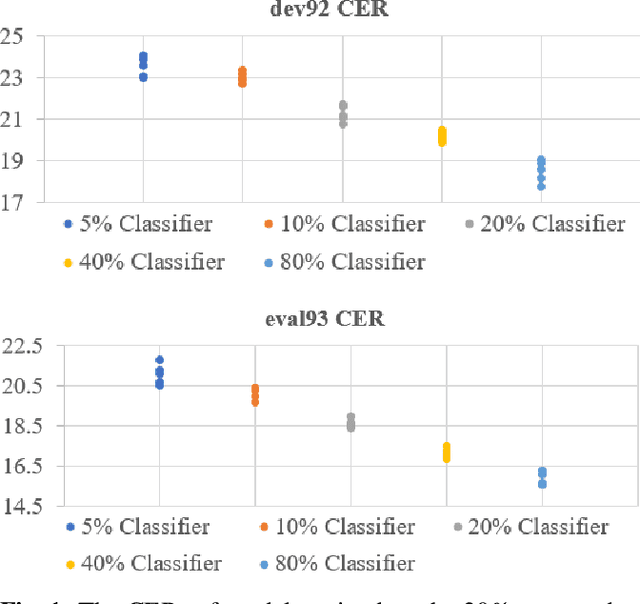
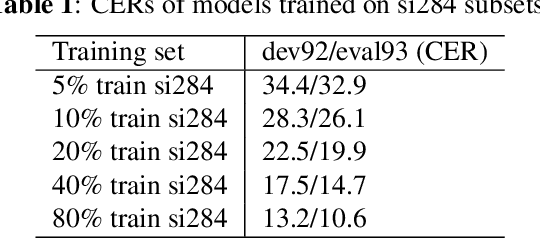
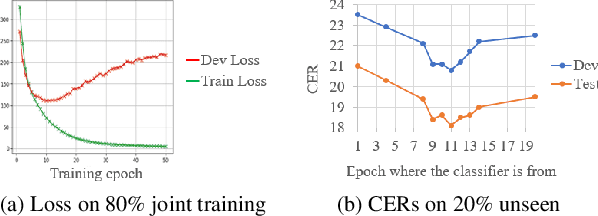
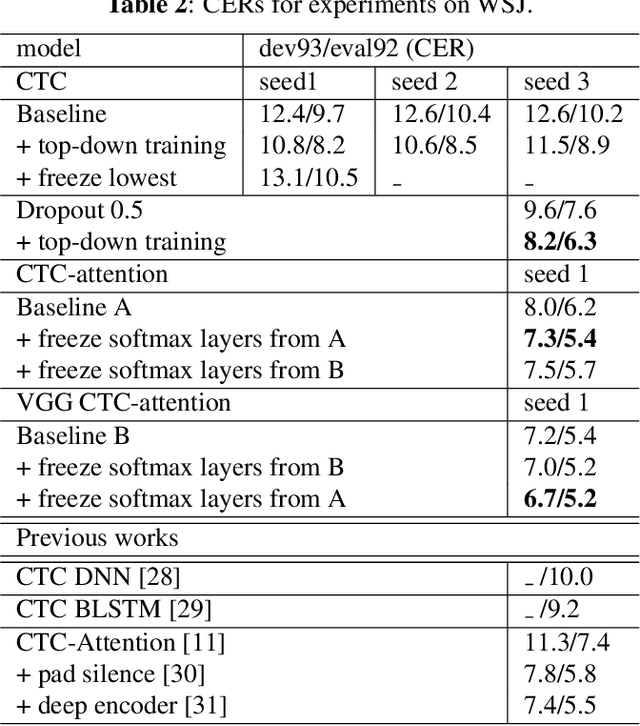
Although the lower layers of a deep neural network learn features which are transferable across datasets, these layers are not transferable within the same dataset. That is, in general, freezing the trained feature extractor (the lower layers) and retraining the classifier (the upper layers) on the same dataset leads to worse performance. In this paper, for the first time, we show that the frozen classifier is transferable within the same dataset. We develop a novel top-down training method which can be viewed as an algorithm for searching for high-quality classifiers. We tested this method on automatic speech recognition (ASR) tasks and language modelling tasks. The proposed method consistently improves recurrent neural network ASR models on Wall Street Journal, self-attention ASR models on Switchboard, and AWD-LSTM language models on WikiText-2.
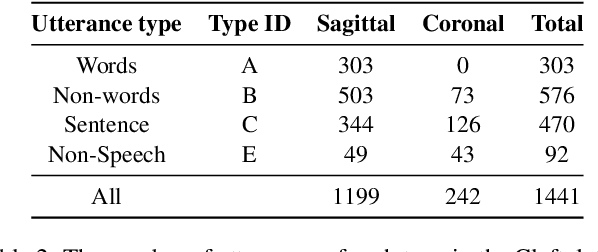
TaL: a synchronised multi-speaker corpus of ultrasound tongue imaging, audio, and lip videos
Nov 19, 2020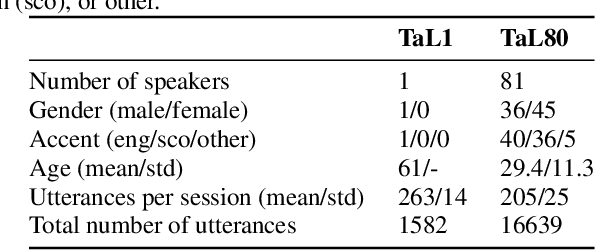
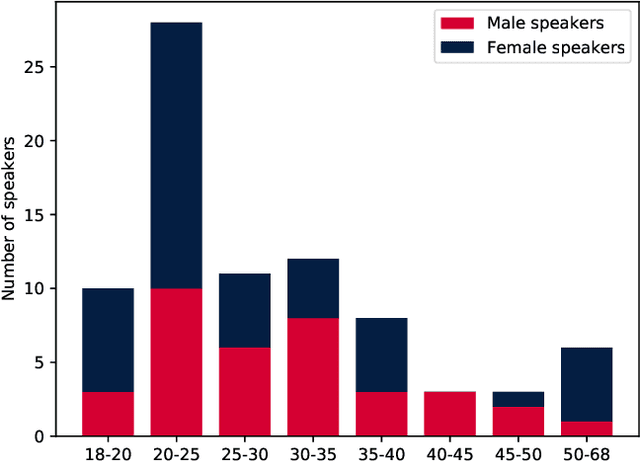
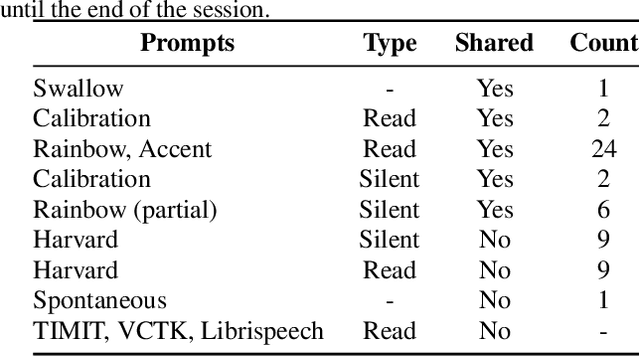

We present the Tongue and Lips corpus (TaL), a multi-speaker corpus of audio, ultrasound tongue imaging, and lip videos. TaL consists of two parts: TaL1 is a set of six recording sessions of one professional voice talent, a male native speaker of English; TaL80 is a set of recording sessions of 81 native speakers of English without voice talent experience. Overall, the corpus contains 24 hours of parallel ultrasound, video, and audio data, of which approximately 13.5 hours are speech. This paper describes the corpus and presents benchmark results for the tasks of speech recognition, speech synthesis (articulatory-to-acoustic mapping), and automatic synchronisation of ultrasound to audio. The TaL corpus is publicly available under the CC BY-NC 4.0 license.
On the Usefulness of Self-Attention for Automatic Speech Recognition with Transformers
Nov 08, 2020
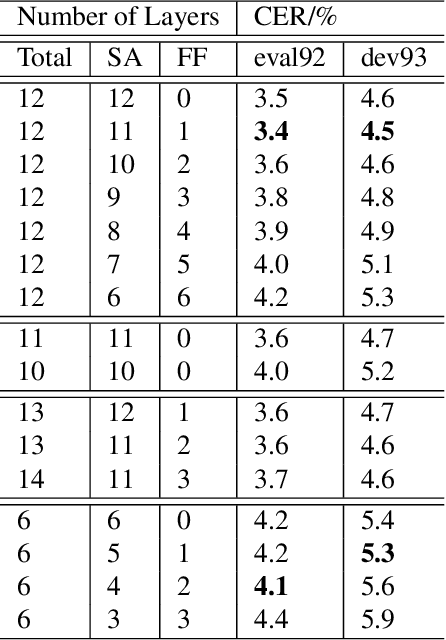
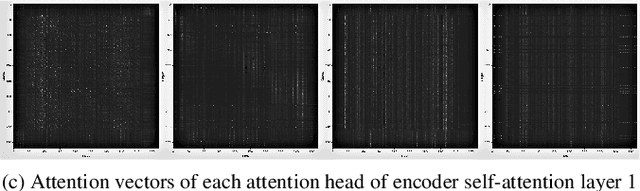
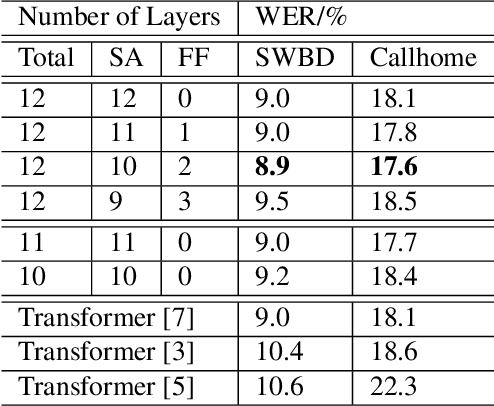
Self-attention models such as Transformers, which can capture temporal relationships without being limited by the distance between events, have given competitive speech recognition results. However, we note the range of the learned context increases from the lower to upper self-attention layers, whilst acoustic events often happen within short time spans in a left-to-right order. This leads to a question: for speech recognition, is a global view of the entire sequence useful for the upper self-attention encoder layers in Transformers? To investigate this, we train models with lower self-attention/upper feed-forward layers encoders on Wall Street Journal and Switchboard. Compared to baseline Transformers, no performance drop but minor gains are observed. We further developed a novel metric of the diagonality of attention matrices and found the learned diagonality indeed increases from the lower to upper encoder self-attention layers. We conclude the global view is unnecessary in training upper encoder layers.
Stochastic Attention Head Removal: A Simple and Effective Method for Improving Automatic Speech Recognition with Transformers
Nov 08, 2020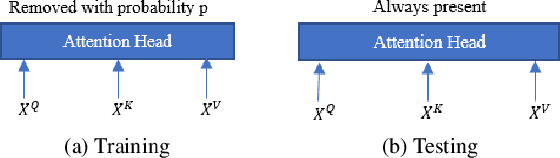
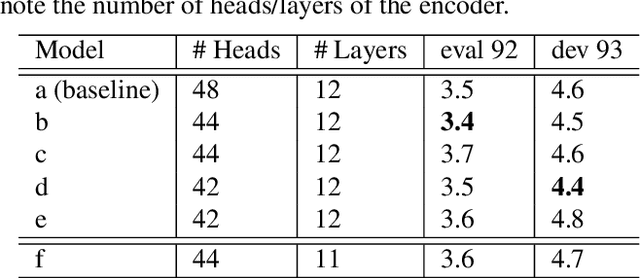
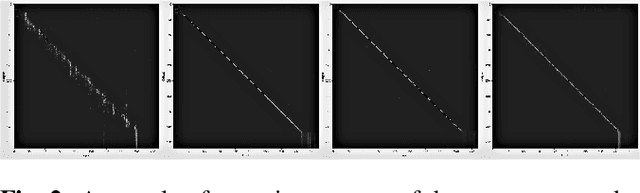
Recently, Transformers have shown competitive automatic speech recognition (ASR) results. One key factor to the success of these models is the multi-head attention mechanism. However, we observed in trained models, the diagonal attention matrices indicating the redundancy of the corresponding attention heads. Furthermore, we found some architectures with reduced numbers of attention heads have better performance. Since the search for the best structure is time prohibitive, we propose to randomly remove attention heads during training and keep all attention heads at test time, thus the final model can be viewed as an average of models with different architectures. This method gives consistent performance gains on the Wall Street Journal, AISHELL, Switchboard and AMI ASR tasks. On the AISHELL dev/test sets, the proposed method achieves state-of-the-art Transformer results with 5.8%/6.3% word error rates.
Leveraging speaker attribute information using multi task learning for speaker verification and diarization
Oct 27, 2020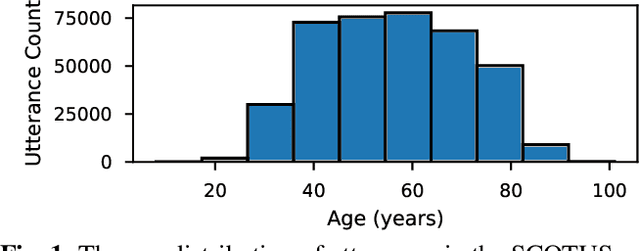
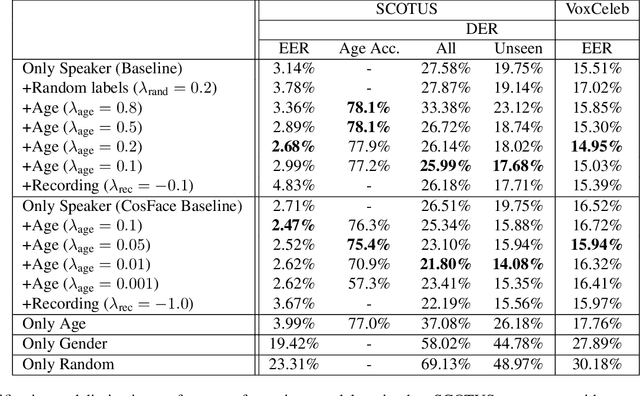
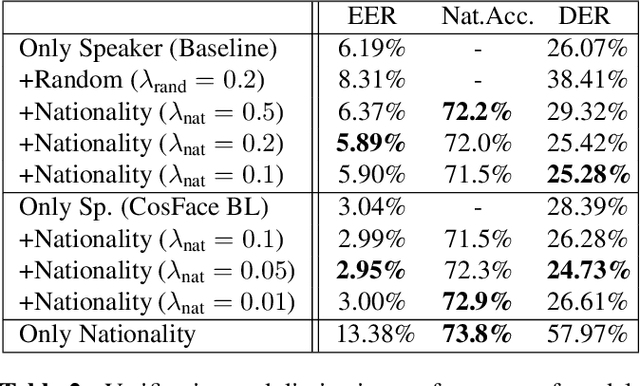
Deep speaker embeddings have become the leading method for encoding speaker identity in speaker recognition tasks. The embedding space should ideally capture the variations between all possible speakers, encoding the multiple aspects that make up speaker identity. In this work, utilizing speaker age as an auxiliary variable in US Supreme Court recordings and speaker nationality with VoxCeleb, we show that by leveraging additional speaker attribute information in a multi task learning setting, deep speaker embedding performance can be increased for verification and diarization tasks, achieving a relative improvement of 17.8% in DER and 8.9% in EER for Supreme Court audio compared to omitting the auxiliary task. Experimental code has been made publicly available.