 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonetic Error Analysis of Raw Waveform Acoustic Models with Parametric and Non-Parametric CNNs
Paper and Code
Jun 02, 2024

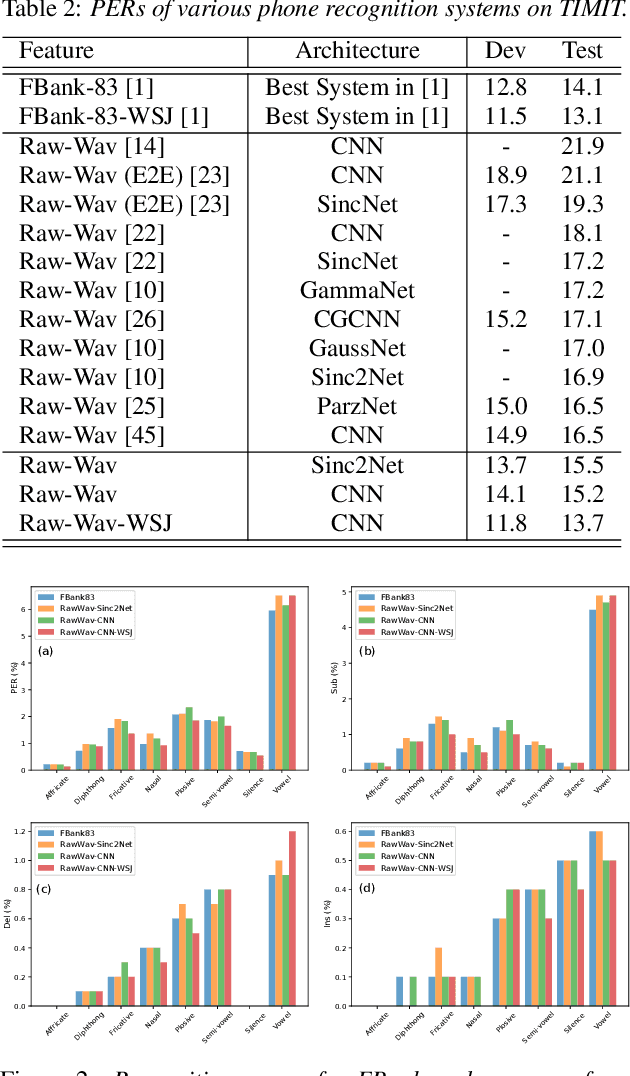

In this paper, we analyse the error patterns of the raw waveform acoustic models in TIMIT's phone recognition task. Our analysis goes beyond the conventional phone error rate (PER) metric. We categorise the phones into three groups: {affricate, diphthong, fricative, nasal, plosive, semi-vowel, vowel, silence}, {consonant, vowel+, silence}, and {voiced, unvoiced, silence} and, compute the PER for each broad phonetic class in each category. We also construct a confusion matrix for each category using the substitution errors and compare the confusion patterns with those of the Filterbank and Wav2vec 2.0 systems. Our raw waveform acoustic models consists of parametric (Sinc2Net) or non-parametric CNNs and Bidirectional LSTMs, achieving down to 13.7%/15.2% PERs on TIMIT Dev/Test sets, outperforming reported PERs for raw waveform models in the literature. We also investigate the impact of transfer learning from WSJ on the phonetic error patterns and confusion matrices. It reduces the PER to 11.8%/13.7% on the Dev/Test sets.