 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Causality-Aware Modeling for Multimodal Brain-Muscle Interactions
Feb 13, 2026Robust characterization of dynamic causal interactions in multivariate biomedical signals is essential for advancing computational and algorithmic methods in biomedical imaging. Conventional approaches, such as Dynamic Bayesian Networks (DBNs), often assume linear or simple statistical dependencies, while manifold based techniques like Convergent Cross Mapping (CCM) capture nonlinear, lagged interactions but lack probabilistic quantification and interventional modeling. We introduce a DBN informed CCM framework that integrates geometric manifold reconstruction with probabilistic temporal modeling. Applied to multimodal EEG-EMG recordings from dystonic and neurotypical children, the method quantifies uncertainty, supports interventional simulation, and reveals distinct frequency specific reorganization of corticomuscular pathways in dystonia. Experimental results show marked improvements in predictive consistency and causal stability as compared to baseline approaches, demonstrating the potential of causality aware multimodal modeling for developing quantitative biomarkers and guiding targeted neuromodulatory interventions.
Stationary and Sparse Denoising Approach for Corticomuscular Causality Estimation
Jun 24, 2024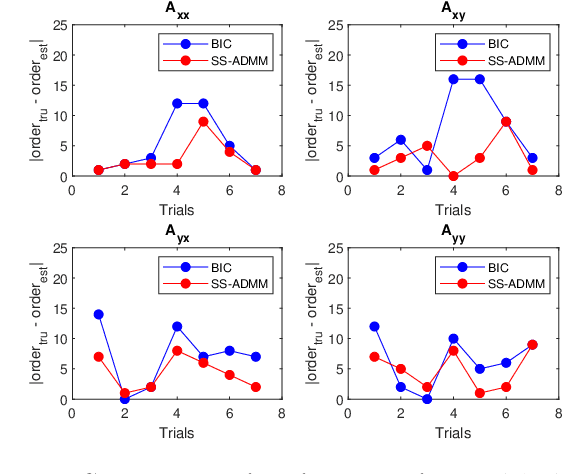
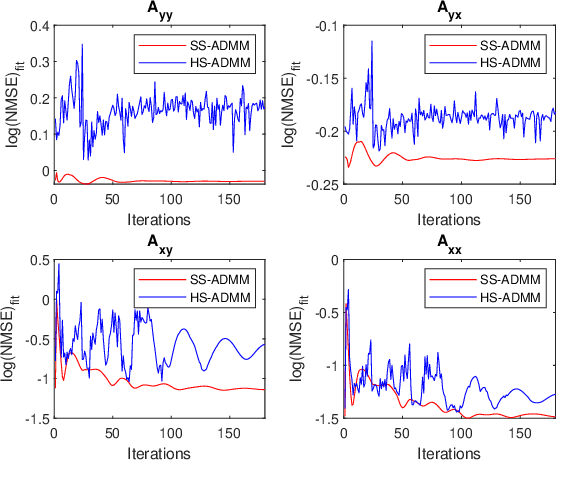
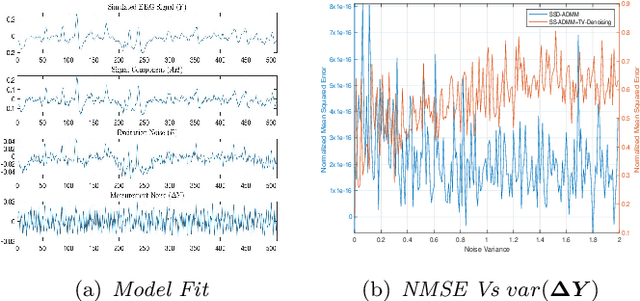
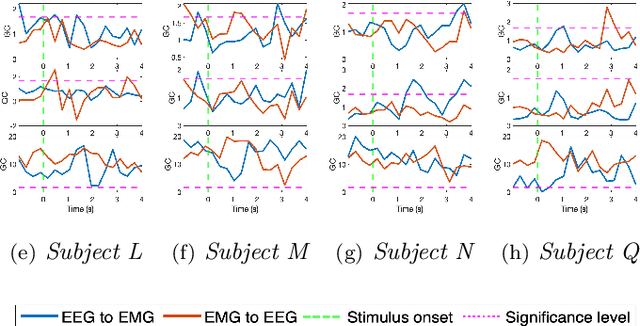
Objective: Cortico-muscular communication patterns are instrumental in understanding movement control. Estimating significant causal relationships between motor cortex electroencephalogram (EEG) and surface electromyogram (sEMG) from concurrently active muscles presents a formidable challenge since the relevant processes underlying muscle control are typically weak in comparison to measurement noise and background activities. Methodology: In this paper, a novel framework is proposed to simultaneously estimate the order of the autoregressive model of cortico-muscular interactions along with the parameters while enforcing stationarity condition in a convex program to ensure global optimality. The proposed method is further extended to a non-convex program to account for the presence of measurement noise in the recorded signals by introducing a wavelet sparsity assumption on the excitation noise in the model. Results: The proposed methodology is validated using both simulated data and neurophysiological signals. In case of simulated data, the performance of the proposed methods has been compared with the benchmark approaches in terms of order identification, computational efficiency, and goodness of fit in relation to various noise levels. In case of physiological signals our proposed methods are compared against the state-of-the-art approaches in terms of the ability to detect Granger causality. Significance: The proposed methods are shown to be effective in handling stationarity and measurement noise assumptions, revealing significant causal interactions from brain to muscles and vice versa.
Phonetic Error Analysis of Raw Waveform Acoustic Models with Parametric and Non-Parametric CNNs
Jun 02, 2024

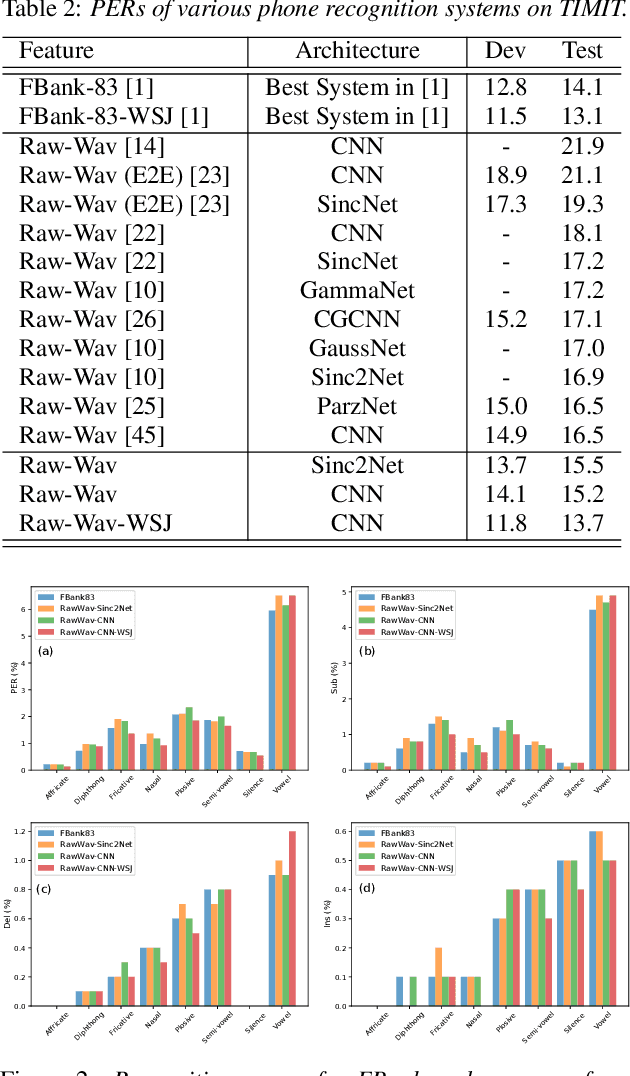

In this paper, we analyse the error patterns of the raw waveform acoustic models in TIMIT's phone recognition task. Our analysis goes beyond the conventional phone error rate (PER) metric. We categorise the phones into three groups: {affricate, diphthong, fricative, nasal, plosive, semi-vowel, vowel, silence}, {consonant, vowel+, silence}, and {voiced, unvoiced, silence} and, compute the PER for each broad phonetic class in each category. We also construct a confusion matrix for each category using the substitution errors and compare the confusion patterns with those of the Filterbank and Wav2vec 2.0 systems. Our raw waveform acoustic models consists of parametric (Sinc2Net) or non-parametric CNNs and Bidirectional LSTMs, achieving down to 13.7%/15.2% PERs on TIMIT Dev/Test sets, outperforming reported PERs for raw waveform models in the literature. We also investigate the impact of transfer learning from WSJ on the phonetic error patterns and confusion matrices. It reduces the PER to 11.8%/13.7% on the Dev/Test sets.
Towards Robust Waveform-Based Acoustic Models
Oct 16, 2021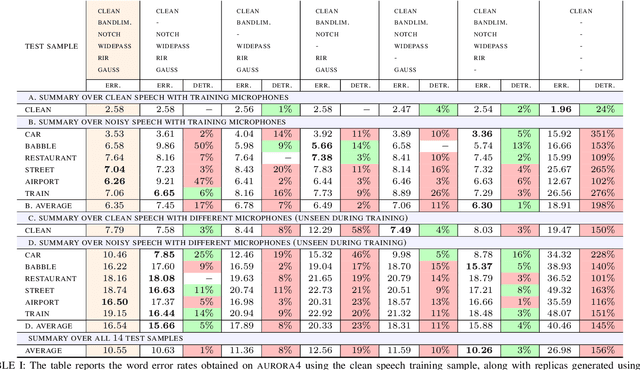
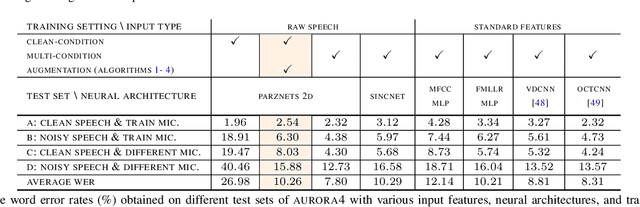
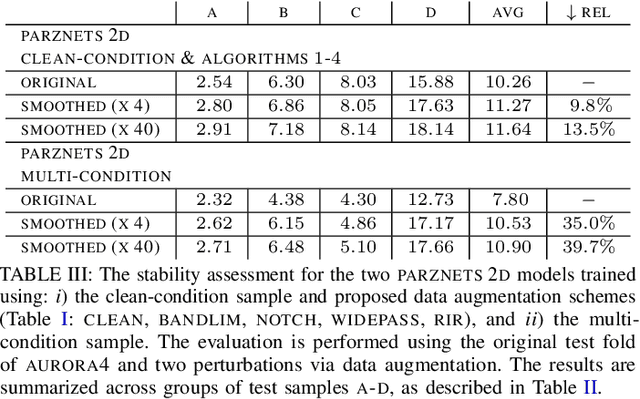
We propose an approach for learning robust acoustic models in adverse environments, characterized by a significant mismatch between training and test conditions. This problem is of paramount importance for the deployment of speech recognition systems that need to perform well in unseen environments. Our approach is an instance of vicinal risk minimization, which aims to improve risk estimates during training by replacing the delta functions that define the empirical density over the input space with an approximation of the marginal population density in the vicinity of the training samples. More specifically, we assume that local neighborhoods centered at training samples can be approximated using a mixture of Gaussians, and demonstrate theoretically that this can incorporate robust inductive bias into the learning process. We characterize the individual mixture components implicitly via data augmentation schemes, designed to address common sources of spurious correlations in acoustic models. To avoid potential confounding effects on robustness due to information loss, which has been associated with standard feature extraction techniques (e.g., FBANK and MFCC features), we focus our evaluation on the waveform-based setting. Our empirical results show that the proposed approach can generalize to unseen noise conditions, with 150% relative improvement in out-of-distribution generalization compared to training using the standard risk minimization principle. Moreover, the results demonstrate competitive performance relative to models learned using a training sample designed to match the acoustic conditions characteristic of test utterances (i.e., optimal vicinal densities).
When saliency goes off on a tangent: Interpreting Deep Neural Networks with nonlinear saliency maps
Oct 13, 2021

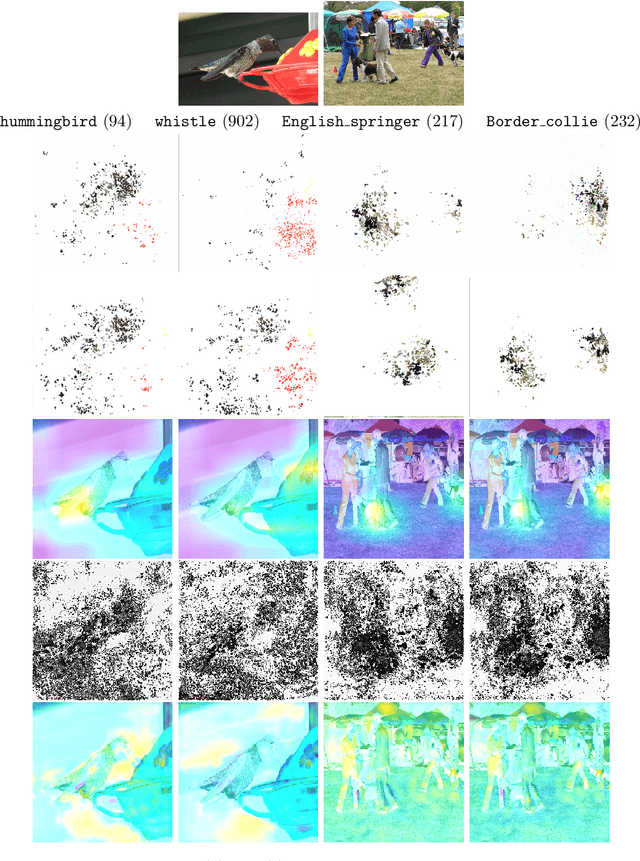
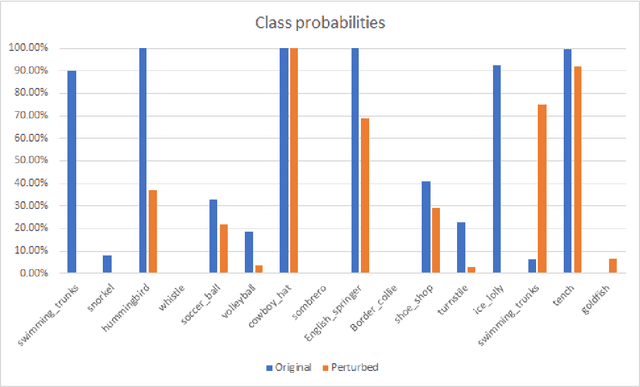
A fundamental bottleneck in utilising complex machine learning systems for critical applications has been not knowing why they do and what they do, thus preventing the development of any crucial safety protocols. To date, no method exist that can provide full insight into the granularity of the neural network's decision process. In the past, saliency maps were an early attempt at resolving this problem through sensitivity calculations, whereby dimensions of a data point are selected based on how sensitive the output of the system is to them. However, the success of saliency maps has been at best limited, mainly due to the fact that they interpret the underlying learning system through a linear approximation. We present a novel class of methods for generating nonlinear saliency maps which fully account for the nonlinearity of the underlying learning system. While agreeing with linear saliency maps on simple problems where linear saliency maps are correct, they clearly identify more specific drivers of classification on complex examples where nonlinearities are more pronounced. This new class of methods significantly aids interpretability of deep neural networks and related machine learning systems. Crucially, they provide a starting point for their more broad use in serious applications, where 'why' is equally important as 'what'.
Multiscale Wavelet Transfer Entropy with Application to Corticomuscular Coupling Analysis
Aug 09, 2021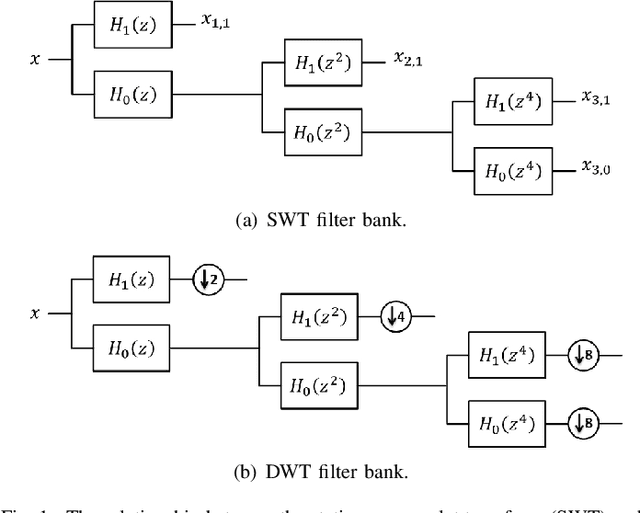
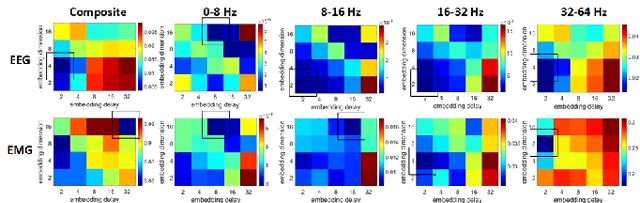
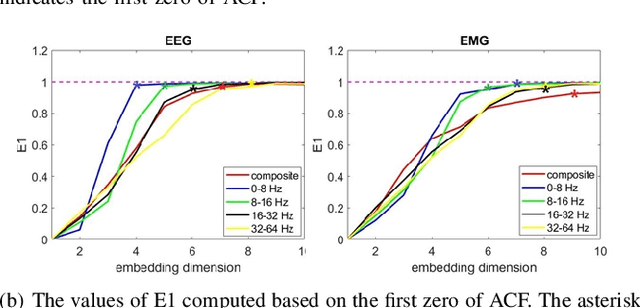
Objective: Functional coupling between the motor cortex and muscle activity is commonly detected and quantified by cortico-muscular coherence (CMC) or Granger causality (GC) analysis, which are applicable only to linear couplings and are not sufficiently sensitive: some healthy subjects show no significant CMC and GC, and yet have good motor skills. The objective of this work is to develop measures of functional cortico-muscular coupling that have improved sensitivity and are capable of detecting both linear and non-linear interactions. Methods: A multiscale wavelet transfer entropy (TE) methodology is proposed. The methodology relies on a dyadic stationary wavelet transform to decompose electroencephalogram (EEG) and electromyogram (EMG) signals into functional bands of neural oscillations. Then, it applies TE analysis based on a range of embedding delay vectors to detect and quantify intra- and cross-frequency band cortico-muscular coupling at different time scales. Results: Our experiments with neurophysiological signals substantiate the potential of the developed methodologies for detecting and quantifying information flow between EEG and EMG signals for subjects with and without significant CMC or GC, including non-linear cross-frequency interactions, and interactions across different temporal scales. The obtained results are in agreement with the underlying sensorimotor neurophysiology. Conclusion: These findings suggest that the concept of multiscale wavelet TE provides a comprehensive framework for analysing cortex-muscle interactions. Significance: The proposed methodologies will enable developing novel insights into movement control and neurophysiological processes more generally.
Goldilocks Neural Networks
Feb 26, 2020
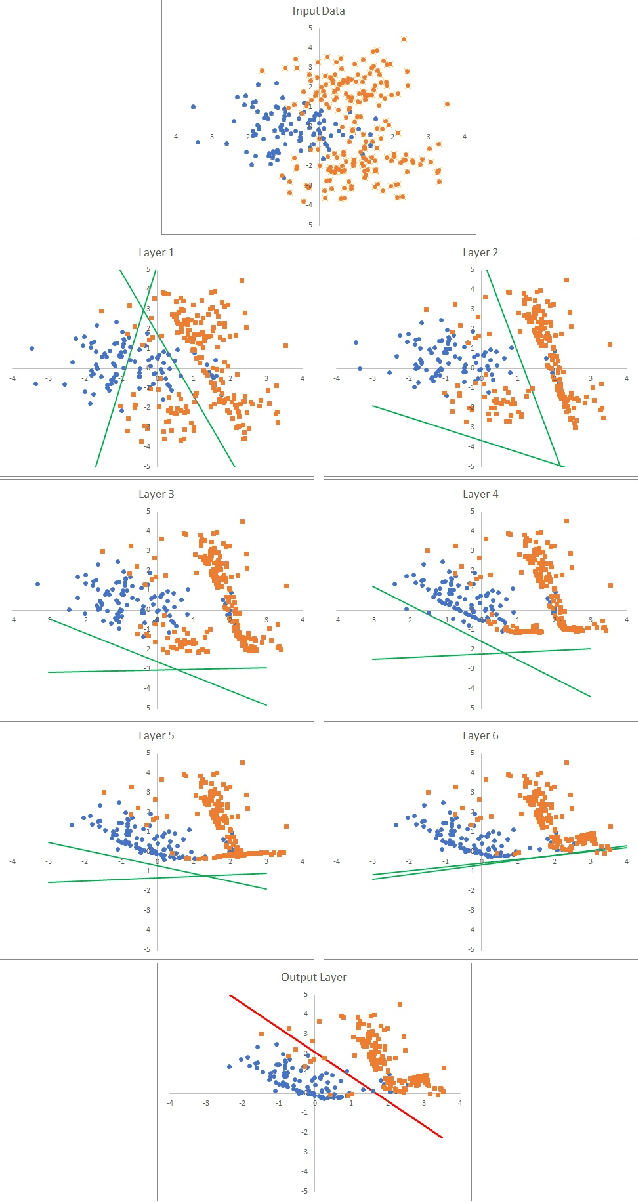
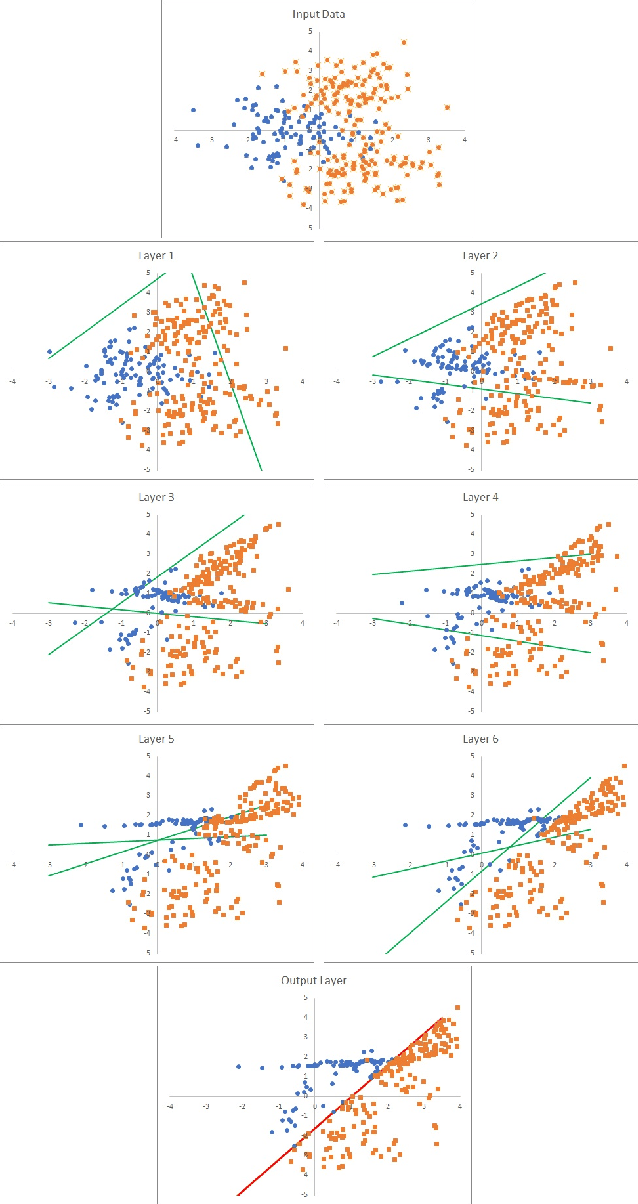
We introduce the new "Goldilocks" class of activation functions, which non-linearly deform the input signal only locally when the input signal is in the appropriate range. The small local deformation of the signal enables better understanding of how and why the signal is transformed through the layers. Numerical results on CIFAR-10 and CIFAR-100 data sets show that Goldilocks networks perform better than, or comparably to SELU and RELU, while introducing tractability of data deformation through the layers.
ITENE: Intrinsic Transfer Entropy Neural Estimator
Jan 08, 2020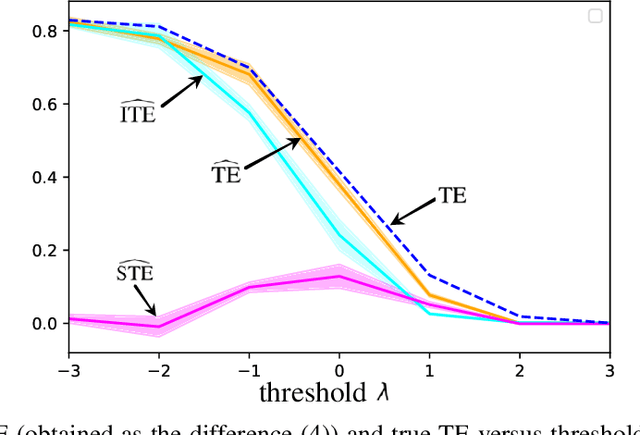
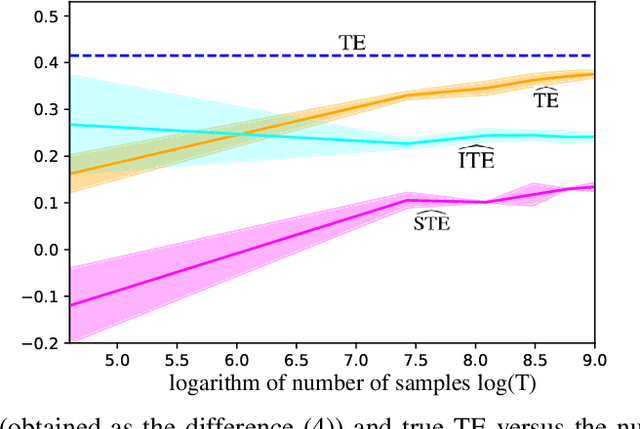
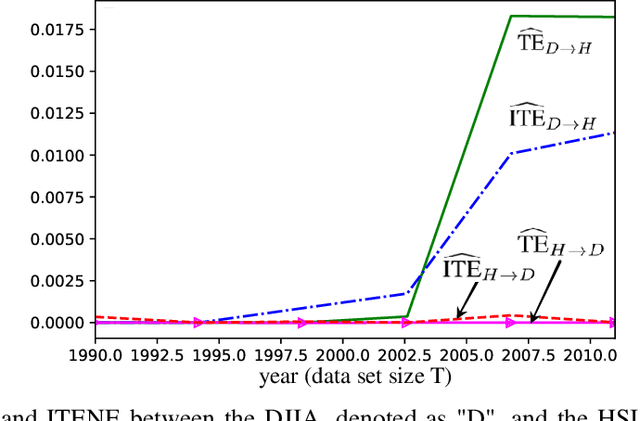
Quantifying the directionality of information flow is instrumental in understanding, and possibly controlling, the operation of many complex systems, such as transportation, social, neural, or gene-regulatory networks. The standard Transfer Entropy (TE) metric follows Granger's causality principle by measuring the Mutual Information (MI) between the past states of a source signal $X$ and the future state of a target signal $Y$ while conditioning on past states of $Y$. Hence, the TE quantifies the improvement, as measured by the log-loss, in the prediction of the target sequence $Y$ that can be accrued when, in addition to the past of $Y$, one also has available past samples from $X$. However, by conditioning on the past of $Y$, the TE also measures information that can be synergistically extracted by observing both the past of $X$ and $Y$, and not solely the past of $X$. Building on a private key agreement formulation, the Intrinsic TE (ITE) aims to discount such synergistic information to quantify the degree to which $X$ is \emph{individually} predictive of $Y$, independent of $Y$'s past. In this paper, an estimator of the ITE is proposed that is inspired by the recently proposed Mutual Information Neural Estimation (MINE). The estimator is based on variational bound on the KL divergence, two-sample neural network classifiers, and the pathwise estimator of Monte Carlo gradients.
Dictionary Learning with BLOTLESS Update
Jun 24, 2019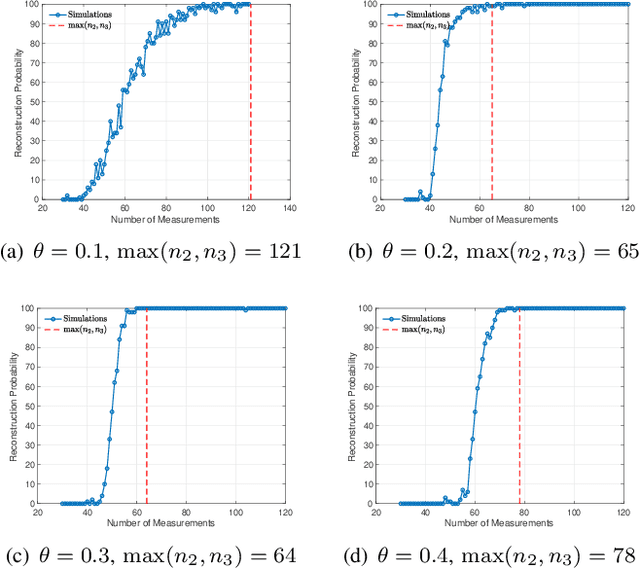
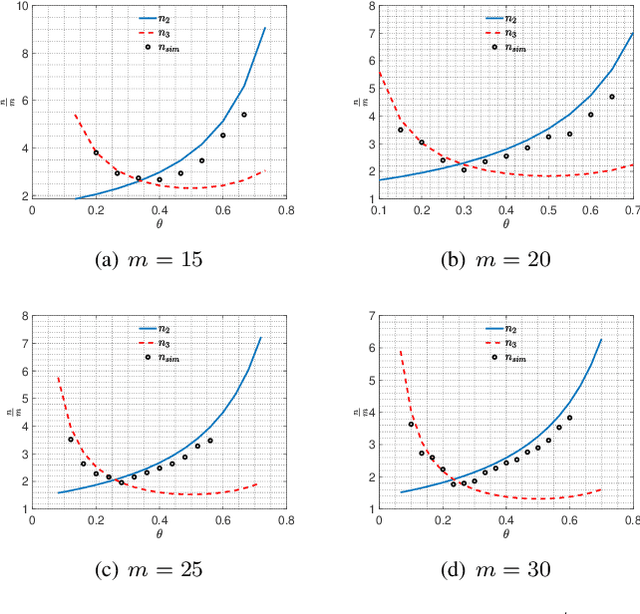
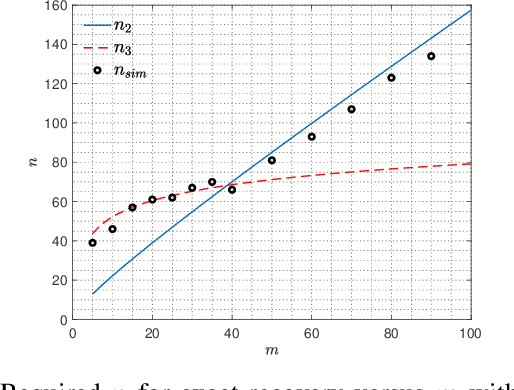
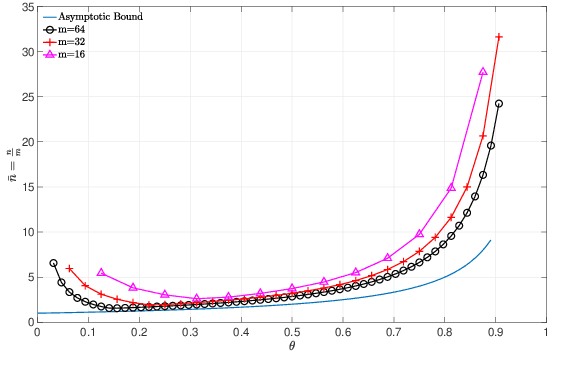
Algorithms for learning a dictionary under which a data in a given set have sparse expansions typically alternate between sparse coding and dictionary update stages. Methods for dictionary update aim to minimise expansion error by updating dictionary vectors and expansion coefficients given patterns of non-zero coefficients obtained in the sparse coding stage. We propose a block total least squares (BLOTLESS) algorithm for dictionary update. BLOTLESS updates a block of dictionary elements and the corresponding sparse coefficients simultaneously. In the error free case, three necessary conditions for exact recovery are identified. Lower bounds on the number of training data are established so that the necessary conditions hold with high probability. Numerical simulations show that the bounds well approximate the number of training data needed for exact dictionary recovery. Numerical experiments further demonstrate several benefits of dictionary learning with BLOTLESS update compared with state-of-the-art algorithms especially when the amount of training data is small.
Parzen Filters for Spectral Decomposition of Signals
Jun 23, 2019

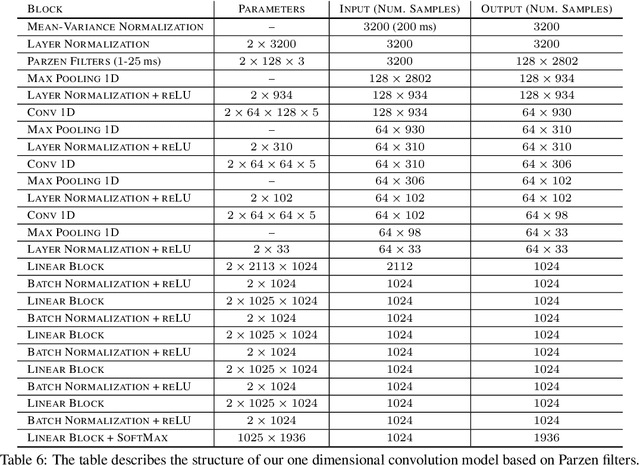
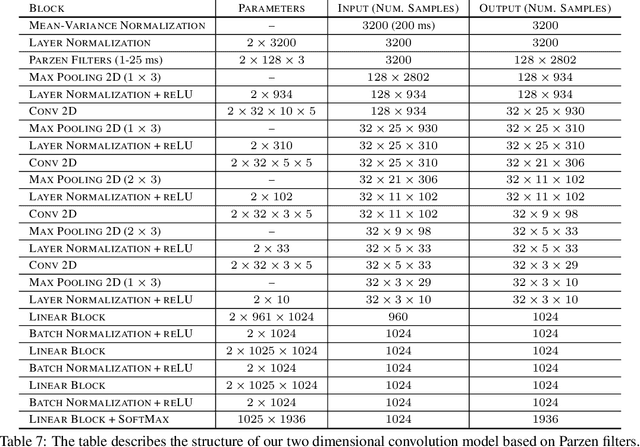
We propose a novel family of band-pass filters for efficient spectral decomposition of signals. Previous work has already established the effectiveness of representations based on static band-pass filtering of speech signals (e.g., mel-frequency cepstral coefficients and deep scattering spectrum). A potential shortcoming of these approaches is the fact that the parameters specifying such a representation are fixed a priori and not learned using the available data. To address this limitation, we propose a family of filters defined via cosine modulations of Parzen windows, where the modulation frequency models the center of a spectral band-pass filter and the length of a Parzen window is inversely proportional to the filter width in the spectral domain. We propose to learn such a representation using stochastic variational Bayesian inference based on Gaussian dropout posteriors and sparsity inducing priors. Such a prior leads to an intractable integral defining the Kullback--Leibler divergence term for which we propose an effective approximation based on the Gauss--Hermite quadrature. Our empirical results demonstrate that the proposed approach is competitive with state-of-the-art models on speech recognition tasks.