 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
Evo-1: Lightweight Vision-Language-Action Model with Preserved Semantic Alignment
Nov 06, 2025Vision-Language-Action (VLA) models have emerged as a powerful framework that unifies perception, language, and control, enabling robots to perform diverse tasks through multimodal understanding. However, current VLA models typically contain massive parameters and rely heavily on large-scale robot data pretraining, leading to high computational costs during training, as well as limited deployability for real-time inference. Moreover, most training paradigms often degrade the perceptual representations of the vision-language backbone, resulting in overfitting and poor generalization to downstream tasks. In this work, we present Evo-1, a lightweight VLA model that reduces computation and improves deployment efficiency, while maintaining strong performance without pretraining on robot data. Evo-1 builds on a native multimodal Vision-Language model (VLM), incorporating a novel cross-modulated diffusion transformer along with an optimized integration module, together forming an effective architecture. We further introduce a two-stage training paradigm that progressively aligns action with perception, preserving the representations of the VLM. Notably, with only 0.77 billion parameters, Evo-1 achieves state-of-the-art results on the Meta-World and RoboTwin suite, surpassing the previous best models by 12.4% and 6.9%, respectively, and also attains a competitive result of 94.8% on LIBERO. In real-world evaluations, Evo-1 attains a 78% success rate with high inference frequency and low memory overhead, outperforming all baseline methods. We release code, data, and model weights to facilitate future research on lightweight and efficient VLA models.
DMF2Mel: A Dynamic Multiscale Fusion Network for EEG-Driven Mel Spectrogram Reconstruction
Jul 10, 2025Decoding speech from brain signals is a challenging research problem. Although existing technologies have made progress in reconstructing the mel spectrograms of auditory stimuli at the word or letter level, there remain core challenges in the precise reconstruction of minute-level continuous imagined speech: traditional models struggle to balance the efficiency of temporal dependency modeling and information retention in long-sequence decoding. To address this issue, this paper proposes the Dynamic Multiscale Fusion Network (DMF2Mel), which consists of four core components: the Dynamic Contrastive Feature Aggregation Module (DC-FAM), the Hierarchical Attention-Guided Multi-Scale Network (HAMS-Net), the SplineMap attention mechanism, and the bidirectional state space module (convMamba). Specifically, the DC-FAM separates speech-related "foreground features" from noisy "background features" through local convolution and global attention mechanisms, effectively suppressing interference and enhancing the representation of transient signals. HAMS-Net, based on the U-Net framework,achieves cross-scale fusion of high-level semantics and low-level details. The SplineMap attention mechanism integrates the Adaptive Gated Kolmogorov-Arnold Network (AGKAN) to combine global context modeling with spline-based local fitting. The convMamba captures long-range temporal dependencies with linear complexity and enhances nonlinear dynamic modeling capabilities. Results on the SparrKULee dataset show that DMF2Mel achieves a Pearson correlation coefficient of 0.074 in mel spectrogram reconstruction for known subjects (a 48% improvement over the baseline) and 0.048 for unknown subjects (a 35% improvement over the baseline).Code is available at: https://github.com/fchest/DMF2Mel.
MHANet: Multi-scale Hybrid Attention Network for Auditory Attention Detection
May 21, 2025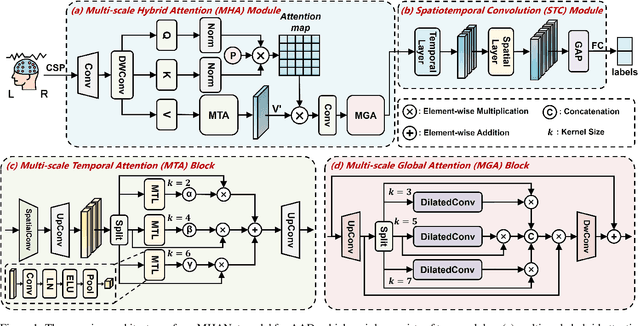
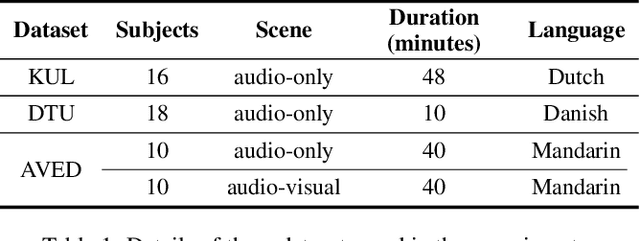
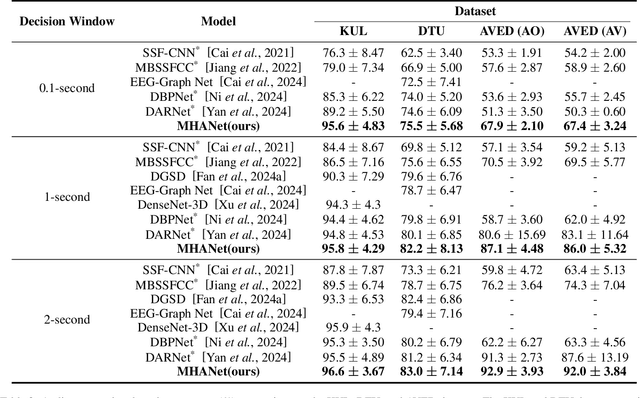
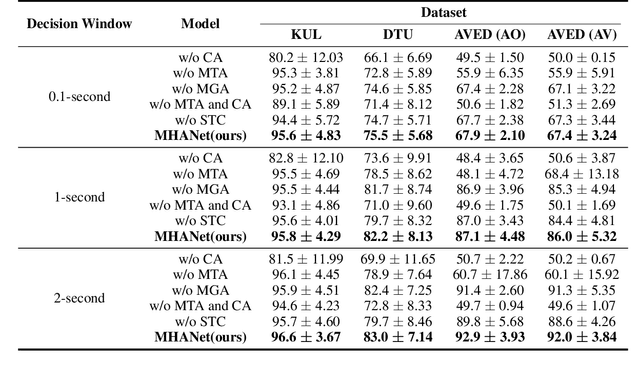
Auditory attention detection (AAD) aims to detect the target speaker in a multi-talker environment from brain signals, such as electroencephalography (EEG), which has made great progress. However, most AAD methods solely utilize attention mechanisms sequentially and overlook valuable multi-scale contextual information within EEG signals, limiting their ability to capture long-short range spatiotemporal dependencies simultaneously. To address these issues, this paper proposes a multi-scale hybrid attention network (MHANet) for AAD, which consists of the multi-scale hybrid attention (MHA) module and the spatiotemporal convolution (STC) module. Specifically, MHA combines channel attention and multi-scale temporal and global attention mechanisms. This effectively extracts multi-scale temporal patterns within EEG signals and captures long-short range spatiotemporal dependencies simultaneously. To further improve the performance of AAD, STC utilizes temporal and spatial convolutions to aggregate expressive spatiotemporal representations. Experimental results show that the proposed MHANet achieves state-of-the-art performance with fewer trainable parameters across three datasets, 3 times lower than that of the most advanced model. Code is available at: https://github.com/fchest/MHANet.
SFL-LEO: Asynchronous Split-Federated Learning Design for LEO Satellite-Ground Network Framework
Apr 18, 2025
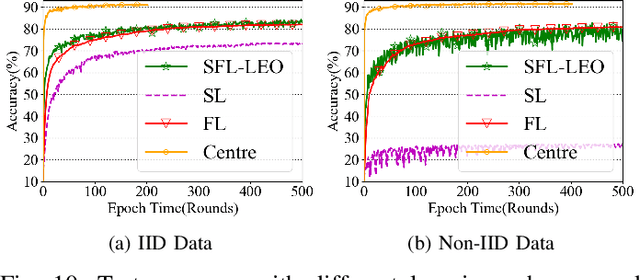
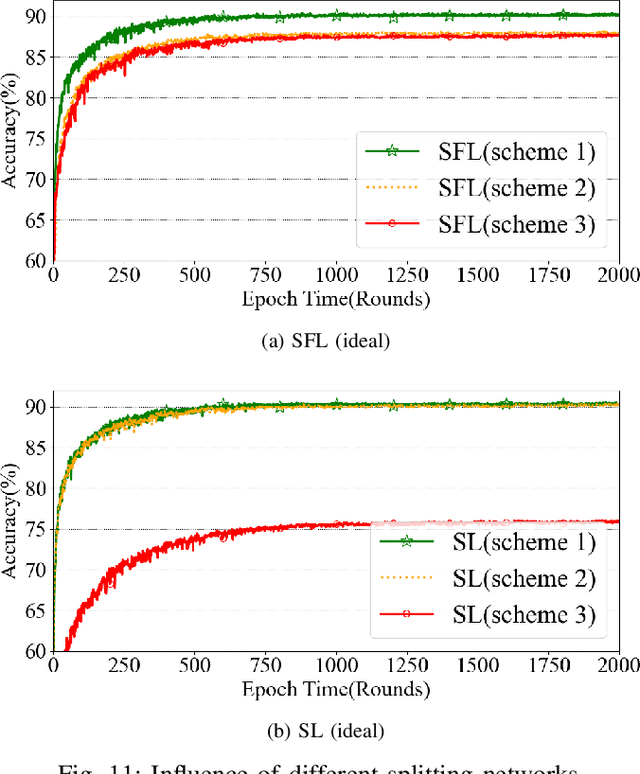
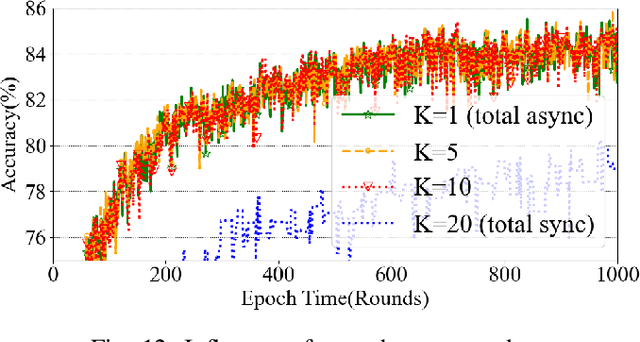
Recently, the rapid development of LEO satellite networks spurs another widespread concern-data processing at satellites. However, achieving efficient computation at LEO satellites in highly dynamic satellite networks is challenging and remains an open problem when considering the constrained computation capability of LEO satellites. For the first time, we propose a novel distributed learning framework named SFL-LEO by combining Federated Learning (FL) with Split Learning (SL) to accommodate the high dynamics of LEO satellite networks and the constrained computation capability of LEO satellites by leveraging the periodical orbit traveling feature. The proposed scheme allows training locally by introducing an asynchronous training strategy, i.e., achieving local update when LEO satellites disconnect with the ground station, to provide much more training space and thus increase the training performance. Meanwhile, it aggregates client-side sub-models at the ground station and then distributes them to LEO satellites by borrowing the idea from the federated learning scheme. Experiment results driven by satellite-ground bandwidth measured in Starlink demonstrate that SFL-LEO provides a similar accuracy performance with the conventional SL scheme because it can perform local training even within the disconnection duration.
Composed Multi-modal Retrieval: A Survey of Approaches and Applications
Mar 03, 2025



With the rapid growth of multi-modal data from social media, short video platforms, and e-commerce, content-based retrieval has become essential for efficiently searching and utilizing heterogeneous information. Over time, retrieval techniques have evolved from Unimodal Retrieval (UR) to Cross-modal Retrieval (CR) and, more recently, to Composed Multi-modal Retrieval (CMR). CMR enables users to retrieve images or videos by integrating a reference visual input with textual modifications, enhancing search flexibility and precision. This paper provides a comprehensive review of CMR, covering its fundamental challenges, technical advancements, and categorization into supervised, zero-shot, and semi-supervised learning paradigms. We discuss key research directions, including data augmentation, model architecture, and loss optimization in supervised CMR, as well as transformation frameworks and external knowledge integration in zero-shot CMR. Additionally, we highlight the application potential of CMR in composed image retrieval, video retrieval, and person retrieval, which have significant implications for e-commerce, online search, and public security. Given its ability to refine and personalize search experiences, CMR is poised to become a pivotal technology in next-generation retrieval systems. A curated list of related works and resources is available at: https://github.com/kkzhang95/Awesome-Composed-Multi-modal-Retrieval
Improved Feature Extraction Network for Neuro-Oriented Target Speaker Extraction
Jan 03, 2025



The recent rapid development of auditory attention decoding (AAD) offers the possibility of using electroencephalography (EEG) as auxiliary information for target speaker extraction. However, effectively modeling long sequences of speech and resolving the identity of the target speaker from EEG signals remains a major challenge. In this paper, an improved feature extraction network (IFENet) is proposed for neuro-oriented target speaker extraction, which mainly consists of a speech encoder with dual-path Mamba and an EEG encoder with Kolmogorov-Arnold Networks (KAN). We propose SpeechBiMamba, which makes use of dual-path Mamba in modeling local and global speech sequences to extract speech features. In addition, we propose EEGKAN to effectively extract EEG features that are closely related to the auditory stimuli and locate the target speaker through the subject's attention information. Experiments on the KUL and AVED datasets show that IFENet outperforms the state-of-the-art model, achieving 36\% and 29\% relative improvements in terms of scale-invariant signal-to-distortion ratio (SI-SDR) under an open evaluation condition.
FLARE: A New Federated Learning Framework with Adjustable Learning Rates over Resource-Constrained Wireless Networks
Apr 23, 2024Wireless federated learning (WFL) suffers from heterogeneity prevailing in the data distributions, computing powers, and channel conditions of participating devices. This paper presents a new Federated Learning with Adjusted leaRning ratE (FLARE) framework to mitigate the impact of the heterogeneity. The key idea is to allow the participating devices to adjust their individual learning rates and local training iterations, adapting to their instantaneous computing powers. The convergence upper bound of FLARE is established rigorously under a general setting with non-convex models in the presence of non-i.i.d. datasets and imbalanced computing powers. By minimizing the upper bound, we further optimize the scheduling of FLARE to exploit the channel heterogeneity. A nested problem structure is revealed to facilitate iteratively allocating the bandwidth with binary search and selecting devices with a new greedy method. A linear problem structure is also identified and a low-complexity linear programming scheduling policy is designed when training models have large Lipschitz constants. Experiments demonstrate that FLARE consistently outperforms the baselines in test accuracy, and converges much faster with the proposed scheduling policy.
DRAG: Divergence-based Adaptive Aggregation in Federated learning on Non-IID Data
Sep 04, 2023



Local stochastic gradient descent (SGD) is a fundamental approach in achieving communication efficiency in Federated Learning (FL) by allowing individual workers to perform local updates. However, the presence of heterogeneous data distributions across working nodes causes each worker to update its local model towards a local optimum, leading to the phenomenon known as ``client-drift" and resulting in slowed convergence. To address this issue, previous works have explored methods that either introduce communication overhead or suffer from unsteady performance. In this work, we introduce a novel metric called ``degree of divergence," quantifying the angle between the local gradient and the global reference direction. Leveraging this metric, we propose the divergence-based adaptive aggregation (DRAG) algorithm, which dynamically ``drags" the received local updates toward the reference direction in each round without requiring extra communication overhead. Furthermore, we establish a rigorous convergence analysis for DRAG, proving its ability to achieve a sublinear convergence rate. Compelling experimental results are presented to illustrate DRAG's superior performance compared to state-of-the-art algorithms in effectively managing the client-drift phenomenon. Additionally, DRAG exhibits remarkable resilience against certain Byzantine attacks. By securely sharing a small sample of the client's data with the FL server, DRAG effectively counters these attacks, as demonstrated through comprehensive experiments.
Adaptive Multi-Armed Bandit Learning for Task Offloading in Edge Computing
Jun 09, 2023The widespread adoption of edge computing has emerged as a prominent trend for alleviating task processing delays and reducing energy consumption. However, the dynamic nature of network conditions and the varying computation capacities of edge servers (ESs) can introduce disparities between computation loads and available computing resources in edge computing networks, potentially leading to inadequate service quality. To address this challenge, this paper investigates a practical scenario characterized by dynamic task offloading. Initially, we examine traditional Multi-armed Bandit (MAB) algorithms, namely the $\varepsilon$-greedy algorithm and the UCB1-based algorithm. However, both algorithms exhibit certain weaknesses in effectively addressing the tidal data traffic patterns. Consequently, based on MAB, we propose an adaptive task offloading algorithm (ATOA) that overcomes these limitations. By conducting extensive simulations, we demonstrate the superiority of our ATOA solution in reducing task processing latency compared to conventional MAB methods. This substantiates the effectiveness of our approach in enhancing the performance of edge computing networks and improving overall service quality.