 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBHN-Net: Dual-Branch Hybrid Neural Network For Low-Complexity Monaural Speech Enhancement
Jun 04, 2026Although artificial neural network (ANN) based speech enhancement (SE) methods demonstrate excellent performance, the high computational complexity and high energy consumption hinder their deployment in practical front-end processing tasks.} Currently, the spiking neural networks (SNNs) have shown potential in reducing power consumption. However, the discrete binary activation and complex spatio-temporal dynamics of SNNs often result in information loss. The current challenge therefore focuses on how to maintain performance and reduce computational complexity. To address this issue, this work propose a Dual-Branch Hybrid Neural (DBHN) Network. 1) In terms of network architecture: A dual-branch network integrating ANN and SNN was designed, where the SNN branch reduces power consumption while the ANN branch addresses information loss; The BandSplit and Time-Frequency (TF) -Mamba modules were developed to simultaneously compress energy consumption and enhance model performance; Spiking Feature Extraction Group (SFEG) and Information Transformation Block (ITB) components were implemented with residual connections to mitigate information loss while further refining feature representations. 2) To facilitate inter-branch information fusion: An Interaction module was designed to promote information exchange at various stages of the dual-branch network; A TF-Cross Attention-Fusion module was designed to perform time-frequency domain fusion of dual-branch information while data-adaptively guiding the SNN branch to retain more critical information. Results show that the proposed model maintains superior performance across three public datasets while achieving an average 7.5 fold reduction in computational complexity compared to baseline models.
* This article has been accepted for publication in IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI)
Trifuse: Enhancing Attention-Based GUI Grounding via Multimodal Fusion
Feb 06, 2026GUI grounding maps natural language instructions to the correct interface elements, serving as the perception foundation for GUI agents. Existing approaches predominantly rely on fine-tuning multimodal large language models (MLLMs) using large-scale GUI datasets to predict target element coordinates, which is data-intensive and generalizes poorly to unseen interfaces. Recent attention-based alternatives exploit localization signals in MLLMs attention mechanisms without task-specific fine-tuning, but suffer from low reliability due to the lack of explicit and complementary spatial anchors in GUI images. To address this limitation, we propose Trifuse, an attention-based grounding framework that explicitly integrates complementary spatial anchors. Trifuse integrates attention, OCR-derived textual cues, and icon-level caption semantics via a Consensus-SinglePeak (CS) fusion strategy that enforces cross-modal agreement while retaining sharp localization peaks. Extensive evaluations on four grounding benchmarks demonstrate that Trifuse achieves strong performance without task-specific fine-tuning, substantially reducing the reliance on expensive annotated data. Moreover, ablation studies reveal that incorporating OCR and caption cues consistently improves attention-based grounding performance across different backbones, highlighting its effectiveness as a general framework for GUI grounding.
FAIR-ESI: Feature Adaptive Importance Refinement for Electrophysiological Source Imaging
Jan 22, 2026An essential technique for diagnosing brain disorders is electrophysiological source imaging (ESI). While model-based optimization and deep learning methods have achieved promising results in this field, the accurate selection and refinement of features remains a central challenge for precise ESI. This paper proposes FAIR-ESI, a novel framework that adaptively refines feature importance across different views, including FFT-based spectral feature refinement, weighted temporal feature refinement, and self-attention-based patch-wise feature refinement. Extensive experiments on two simulation datasets with diverse configurations and two real-world clinical datasets validate our framework's efficacy, highlighting its potential to advance brain disorder diagnosis and offer new insights into brain function.
IEFS-GMB: Gradient Memory Bank-Guided Feature Selection Based on Information Entropy for EEG Classification of Neurological Disorders
Sep 18, 2025Deep learning-based EEG classification is crucial for the automated detection of neurological disorders, improving diagnostic accuracy and enabling early intervention. However, the low signal-to-noise ratio of EEG signals limits model performance, making feature selection (FS) vital for optimizing representations learned by neural network encoders. Existing FS methods are seldom designed specifically for EEG diagnosis; many are architecture-dependent and lack interpretability, limiting their applicability. Moreover, most rely on single-iteration data, resulting in limited robustness to variability. To address these issues, we propose IEFS-GMB, an Information Entropy-based Feature Selection method guided by a Gradient Memory Bank. This approach constructs a dynamic memory bank storing historical gradients, computes feature importance via information entropy, and applies entropy-based weighting to select informative EEG features. Experiments on four public neurological disease datasets show that encoders enhanced with IEFS-GMB achieve accuracy improvements of 0.64% to 6.45% over baseline models. The method also outperforms four competing FS techniques and improves model interpretability, supporting its practical use in clinical settings.
DMF2Mel: A Dynamic Multiscale Fusion Network for EEG-Driven Mel Spectrogram Reconstruction
Jul 10, 2025Decoding speech from brain signals is a challenging research problem. Although existing technologies have made progress in reconstructing the mel spectrograms of auditory stimuli at the word or letter level, there remain core challenges in the precise reconstruction of minute-level continuous imagined speech: traditional models struggle to balance the efficiency of temporal dependency modeling and information retention in long-sequence decoding. To address this issue, this paper proposes the Dynamic Multiscale Fusion Network (DMF2Mel), which consists of four core components: the Dynamic Contrastive Feature Aggregation Module (DC-FAM), the Hierarchical Attention-Guided Multi-Scale Network (HAMS-Net), the SplineMap attention mechanism, and the bidirectional state space module (convMamba). Specifically, the DC-FAM separates speech-related "foreground features" from noisy "background features" through local convolution and global attention mechanisms, effectively suppressing interference and enhancing the representation of transient signals. HAMS-Net, based on the U-Net framework,achieves cross-scale fusion of high-level semantics and low-level details. The SplineMap attention mechanism integrates the Adaptive Gated Kolmogorov-Arnold Network (AGKAN) to combine global context modeling with spline-based local fitting. The convMamba captures long-range temporal dependencies with linear complexity and enhances nonlinear dynamic modeling capabilities. Results on the SparrKULee dataset show that DMF2Mel achieves a Pearson correlation coefficient of 0.074 in mel spectrogram reconstruction for known subjects (a 48% improvement over the baseline) and 0.048 for unknown subjects (a 35% improvement over the baseline).Code is available at: https://github.com/fchest/DMF2Mel.
MHANet: Multi-scale Hybrid Attention Network for Auditory Attention Detection
May 21, 2025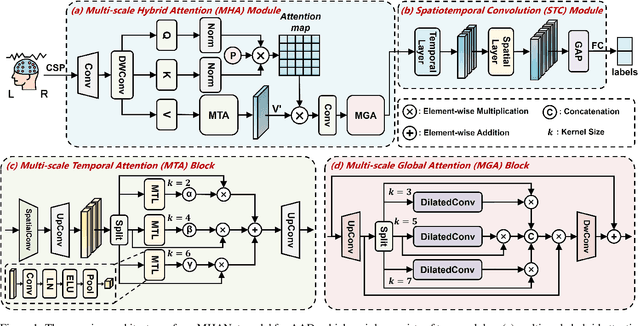
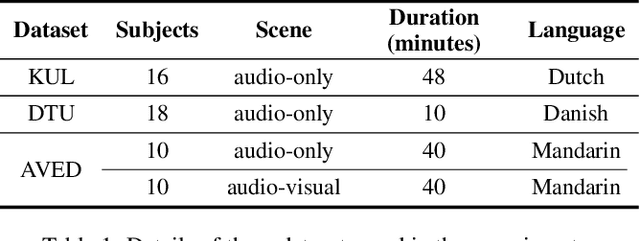
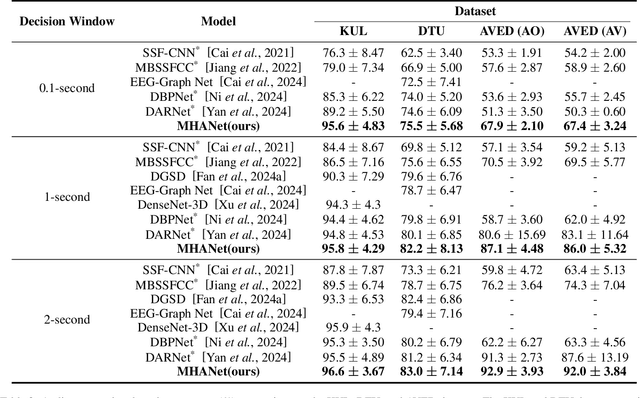
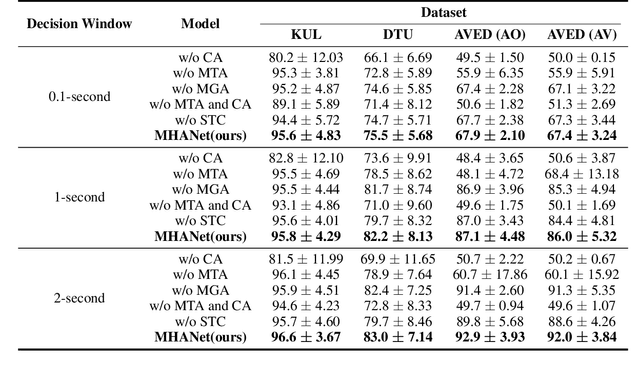
Auditory attention detection (AAD) aims to detect the target speaker in a multi-talker environment from brain signals, such as electroencephalography (EEG), which has made great progress. However, most AAD methods solely utilize attention mechanisms sequentially and overlook valuable multi-scale contextual information within EEG signals, limiting their ability to capture long-short range spatiotemporal dependencies simultaneously. To address these issues, this paper proposes a multi-scale hybrid attention network (MHANet) for AAD, which consists of the multi-scale hybrid attention (MHA) module and the spatiotemporal convolution (STC) module. Specifically, MHA combines channel attention and multi-scale temporal and global attention mechanisms. This effectively extracts multi-scale temporal patterns within EEG signals and captures long-short range spatiotemporal dependencies simultaneously. To further improve the performance of AAD, STC utilizes temporal and spatial convolutions to aggregate expressive spatiotemporal representations. Experimental results show that the proposed MHANet achieves state-of-the-art performance with fewer trainable parameters across three datasets, 3 times lower than that of the most advanced model. Code is available at: https://github.com/fchest/MHANet.
ListenNet: A Lightweight Spatio-Temporal Enhancement Nested Network for Auditory Attention Detection
May 15, 2025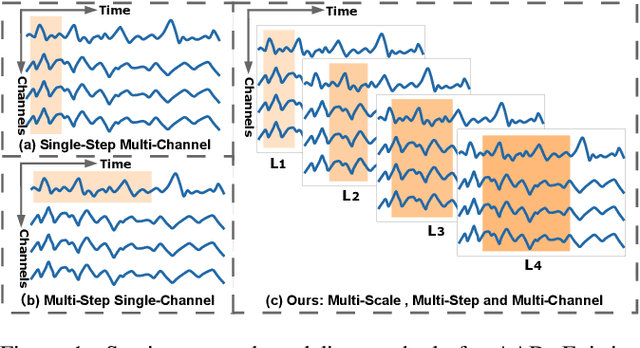
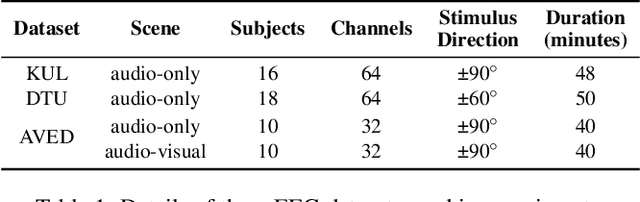
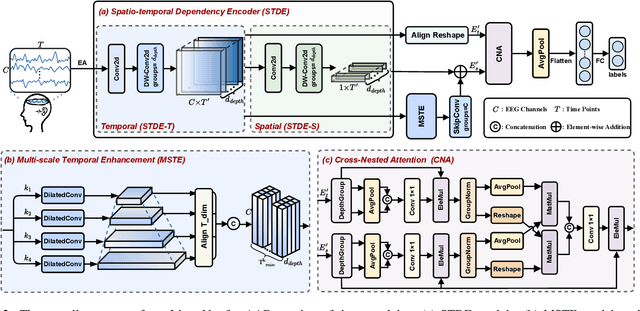
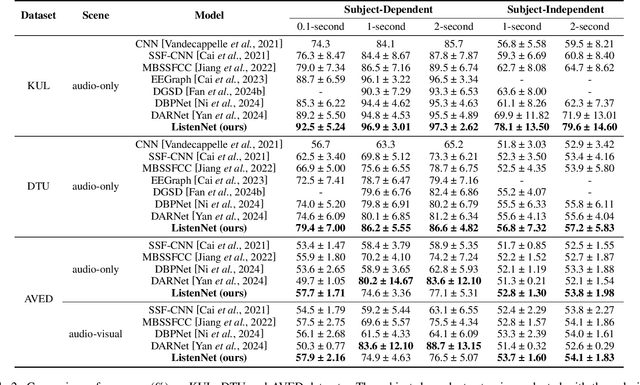
Auditory attention detection (AAD) aims to identify the direction of the attended speaker in multi-speaker environments from brain signals, such as Electroencephalography (EEG) signals. However, existing EEG-based AAD methods overlook the spatio-temporal dependencies of EEG signals, limiting their decoding and generalization abilities. To address these issues, this paper proposes a Lightweight Spatio-Temporal Enhancement Nested Network (ListenNet) for AAD. The ListenNet has three key components: Spatio-temporal Dependency Encoder (STDE), Multi-scale Temporal Enhancement (MSTE), and Cross-Nested Attention (CNA). The STDE reconstructs dependencies between consecutive time windows across channels, improving the robustness of dynamic pattern extraction. The MSTE captures temporal features at multiple scales to represent both fine-grained and long-range temporal patterns. In addition, the CNA integrates hierarchical features more effectively through novel dynamic attention mechanisms to capture deep spatio-temporal correlations. Experimental results on three public datasets demonstrate the superiority of ListenNet over state-of-the-art methods in both subject-dependent and challenging subject-independent settings, while reducing the trainable parameter count by approximately 7 times. Code is available at:https://github.com/fchest/ListenNet.
Improved Feature Extraction Network for Neuro-Oriented Target Speaker Extraction
Jan 03, 2025



The recent rapid development of auditory attention decoding (AAD) offers the possibility of using electroencephalography (EEG) as auxiliary information for target speaker extraction. However, effectively modeling long sequences of speech and resolving the identity of the target speaker from EEG signals remains a major challenge. In this paper, an improved feature extraction network (IFENet) is proposed for neuro-oriented target speaker extraction, which mainly consists of a speech encoder with dual-path Mamba and an EEG encoder with Kolmogorov-Arnold Networks (KAN). We propose SpeechBiMamba, which makes use of dual-path Mamba in modeling local and global speech sequences to extract speech features. In addition, we propose EEGKAN to effectively extract EEG features that are closely related to the auditory stimuli and locate the target speaker through the subject's attention information. Experiments on the KUL and AVED datasets show that IFENet outperforms the state-of-the-art model, achieving 36\% and 29\% relative improvements in terms of scale-invariant signal-to-distortion ratio (SI-SDR) under an open evaluation condition.
BSDB-Net: Band-Split Dual-Branch Network with Selective State Spaces Mechanism for Monaural Speech Enhancement
Dec 26, 2024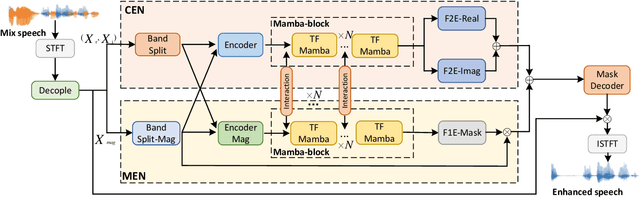
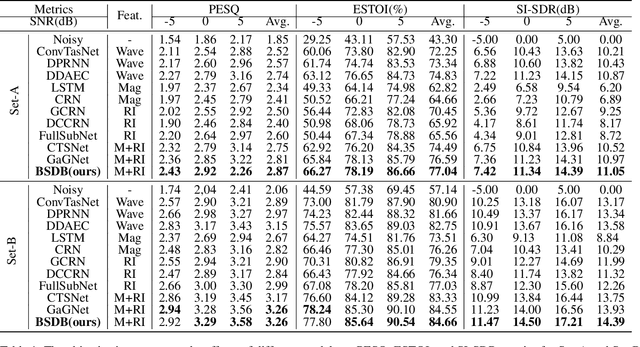
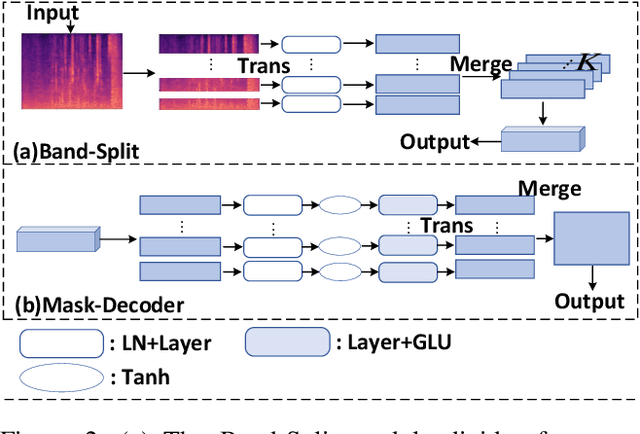
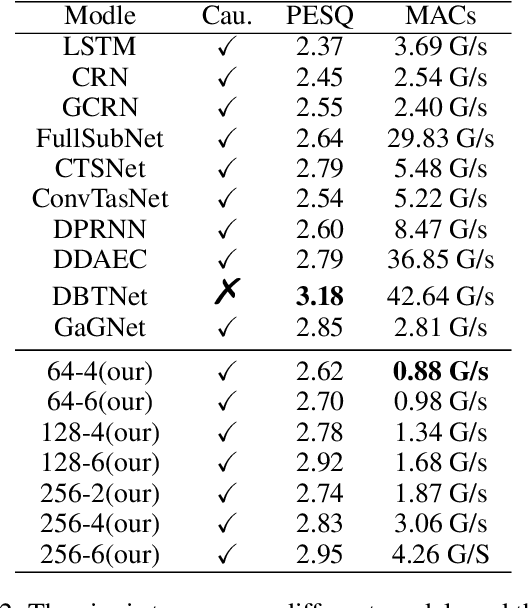
Although the complex spectrum-based speech enhancement(SE) methods have achieved significant performance, coupling amplitude and phase can lead to a compensation effect, where amplitude information is sacrificed to compensate for the phase that is harmful to SE. In addition, to further improve the performance of SE, many modules are stacked onto SE, resulting in increased model complexity that limits the application of SE. To address these problems, we proposed a dual-path network based on compressed frequency using Mamba. First, we extract amplitude and phase information through parallel dual branches. This approach leverages structured complex spectra to implicitly capture phase information and solves the compensation effect by decoupling amplitude and phase, and the network incorporates an interaction module to suppress unnecessary parts and recover missing components from the other branch. Second, to reduce network complexity, the network introduces a band-split strategy to compress the frequency dimension. To further reduce complexity while maintaining good performance, we designed a Mamba-based module that models the time and frequency dimensions under linear complexity. Finally, compared to baselines, our model achieves an average 8.3 times reduction in computational complexity while maintaining superior performance. Furthermore, it achieves a 25 times reduction in complexity compared to transformer-based models.
Region-Based Optimization in Continual Learning for Audio Deepfake Detection
Dec 16, 2024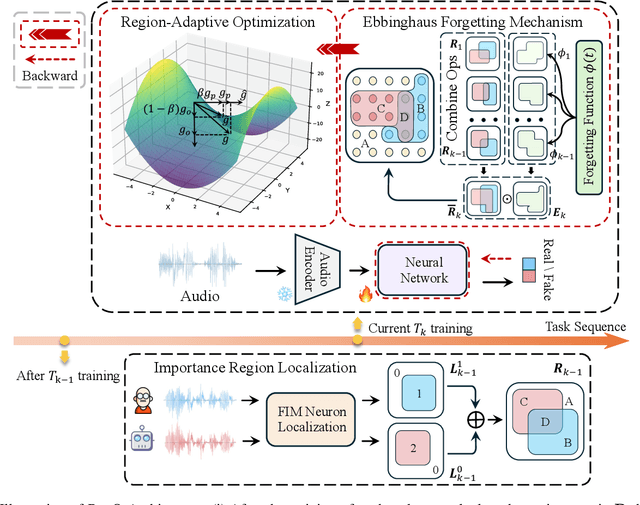
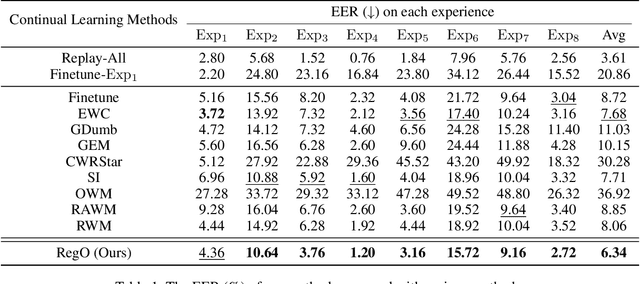
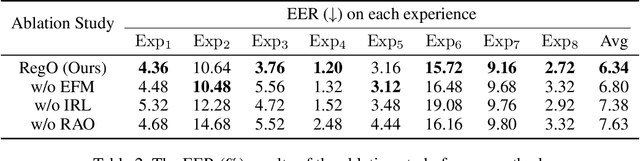
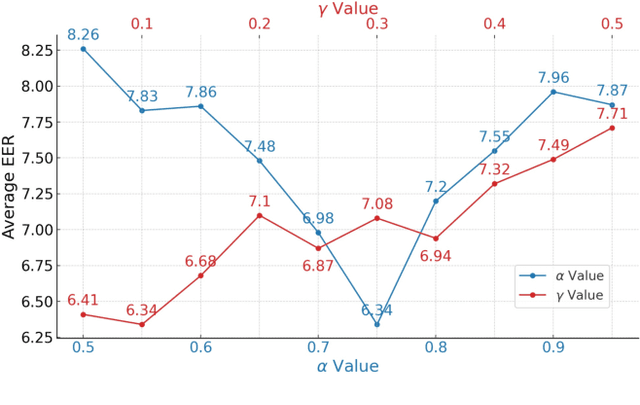
Rapid advancements in speech synthesis and voice conversion bring convenience but also new security risks, creating an urgent need for effective audio deepfake detection. Although current models perform well, their effectiveness diminishes when confronted with the diverse and evolving nature of real-world deepfakes. To address this issue, we propose a continual learning method named Region-Based Optimization (RegO) for audio deepfake detection. Specifically, we use the Fisher information matrix to measure important neuron regions for real and fake audio detection, dividing them into four regions. First, we directly fine-tune the less important regions to quickly adapt to new tasks. Next, we apply gradient optimization in parallel for regions important only to real audio detection, and in orthogonal directions for regions important only to fake audio detection. For regions that are important to both, we use sample proportion-based adaptive gradient optimization. This region-adaptive optimization ensures an appropriate trade-off between memory stability and learning plasticity. Additionally, to address the increase of redundant neurons from old tasks, we further introduce the Ebbinghaus forgetting mechanism to release them, thereby promoting the capability of the model to learn more generalized discriminative features. Experimental results show our method achieves a 21.3% improvement in EER over the state-of-the-art continual learning approach RWM for audio deepfake detection. Moreover, the effectiveness of RegO extends beyond the audio deepfake detection domain, showing potential significance in other tasks, such as image recognition. The code is available at https://github.com/cyjie429/RegO