 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Guided Transformer Tokenizer for Human Motion Generation
Feb 09, 2026In this paper, we focus on motion discrete tokenization, which converts raw motion into compact discrete tokens--a process proven crucial for efficient motion generation. In this paradigm, increasing the number of tokens is a common approach to improving motion reconstruction quality, but more tokens make it more difficult for generative models to learn. To maintain high reconstruction quality while reducing generation complexity, we propose leveraging language to achieve efficient motion tokenization, which we term Language-Guided Tokenization (LG-Tok). LG-Tok aligns natural language with motion at the tokenization stage, yielding compact, high-level semantic representations. This approach not only strengthens both tokenization and detokenization but also simplifies the learning of generative models. Furthermore, existing tokenizers predominantly adopt convolutional architectures, whose local receptive fields struggle to support global language guidance. To this end, we propose a Transformer-based Tokenizer that leverages attention mechanisms to enable effective alignment between language and motion. Additionally, we design a language-drop scheme, in which language conditions are randomly removed during training, enabling the detokenizer to support language-free guidance during generation. On the HumanML3D and Motion-X generation benchmarks, LG-Tok achieves Top-1 scores of 0.542 and 0.582, outperforming state-of-the-art methods (MARDM: 0.500 and 0.528), and with FID scores of 0.057 and 0.088, respectively, versus 0.114 and 0.147. LG-Tok-mini uses only half the tokens while maintaining competitive performance (Top-1: 0.521/0.588, FID: 0.085/0.071), validating the efficiency of our semantic representations.
DARNet: Dual Attention Refinement Network with Spatiotemporal Construction for Auditory Attention Detection
Oct 15, 2024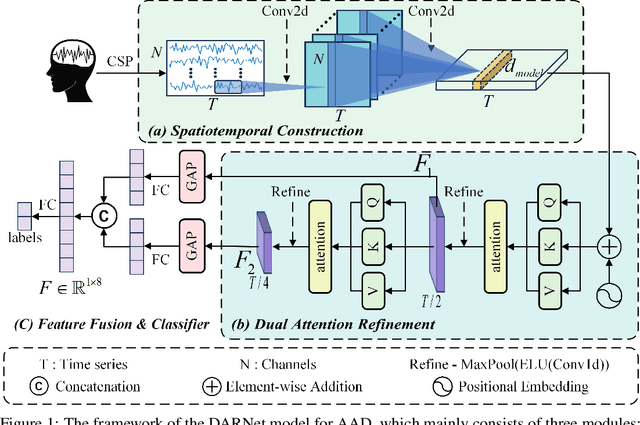



At a cocktail party, humans exhibit an impressive ability to direct their attention. The auditory attention detection (AAD) approach seeks to identify the attended speaker by analyzing brain signals, such as EEG signals. However, current AAD algorithms overlook the spatial distribution information within EEG signals and lack the ability to capture long-range latent dependencies, limiting the model's ability to decode brain activity. To address these issues, this paper proposes a dual attention refinement network with spatiotemporal construction for AAD, named DARNet, which consists of the spatiotemporal construction module, dual attention refinement module, and feature fusion \& classifier module. Specifically, the spatiotemporal construction module aims to construct more expressive spatiotemporal feature representations, by capturing the spatial distribution characteristics of EEG signals. The dual attention refinement module aims to extract different levels of temporal patterns in EEG signals and enhance the model's ability to capture long-range latent dependencies. The feature fusion \& classifier module aims to aggregate temporal patterns and dependencies from different levels and obtain the final classification results. The experimental results indicate that compared to the state-of-the-art models, DARNet achieves an average classification accuracy improvement of 5.9\% for 0.1s, 4.6\% for 1s, and 3.9\% for 2s on the DTU dataset. While maintaining excellent classification performance, DARNet significantly reduces the number of required parameters. Compared to the state-of-the-art models, DARNet reduces the parameter count by 91\%. Code is available at: https://github.com/fchest/DARNet.git.
Prompt When the Animal is: Temporal Animal Behavior Grounding with Positional Recovery Training
May 09, 2024
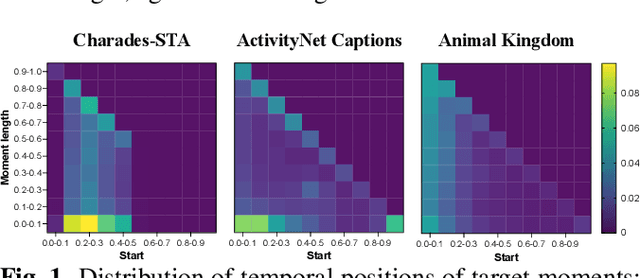

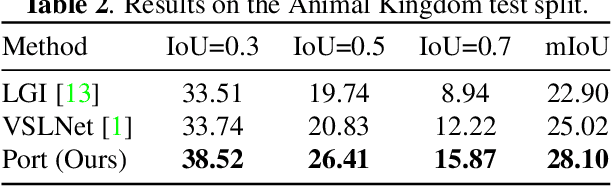
Temporal grounding is crucial in multimodal learning, but it poses challenges when applied to animal behavior data due to the sparsity and uniform distribution of moments. To address these challenges, we propose a novel Positional Recovery Training framework (Port), which prompts the model with the start and end times of specific animal behaviors during training. Specifically, Port enhances the baseline model with a Recovering part to predict flipped label sequences and align distributions with a Dual-alignment method. This allows the model to focus on specific temporal regions prompted by ground-truth information. Extensive experiments on the Animal Kingdom dataset demonstrate the effectiveness of Port, achieving an IoU@0.3 of 38.52. It emerges as one of the top performers in the sub-track of MMVRAC in ICME 2024 Grand Challenges.
MLP: Motion Label Prior for Temporal Sentence Localization in Untrimmed 3D Human Motions
Apr 21, 2024In this paper, we address the unexplored question of temporal sentence localization in human motions (TSLM), aiming to locate a target moment from a 3D human motion that semantically corresponds to a text query. Considering that 3D human motions are captured using specialized motion capture devices, motions with only a few joints lack complex scene information like objects and lighting. Due to this character, motion data has low contextual richness and semantic ambiguity between frames, which limits the accuracy of predictions made by current video localization frameworks extended to TSLM to only a rough level. To refine this, we devise two novel label-prior-assisted training schemes: one embed prior knowledge of foreground and background to highlight the localization chances of target moments, and the other forces the originally rough predictions to overlap with the more accurate predictions obtained from the flipped start/end prior label sequences during recovery training. We show that injecting label-prior knowledge into the model is crucial for improving performance at high IoU. In our constructed TSLM benchmark, our model termed MLP achieves a recall of 44.13 at IoU@0.7 on the BABEL dataset and 71.17 on HumanML3D (Restore), outperforming prior works. Finally, we showcase the potential of our approach in corpus-level moment retrieval. Our source code is openly accessible at https://github.com/eanson023/mlp.
Cross-Modal Retrieval for Motion and Text via MildTriple Loss
May 07, 2023



Cross-modal retrieval has become a prominent research topic in computer vision and natural language processing with advances made in image-text and video-text retrieval technologies. However, cross-modal retrieval between human motion sequences and text has not garnered sufficient attention despite the extensive application value it holds, such as aiding virtual reality applications in better understanding users' actions and language. This task presents several challenges, including joint modeling of the two modalities, demanding the understanding of person-centered information from text, and learning behavior features from 3D human motion sequences. Previous work on motion data modeling mainly relied on autoregressive feature extractors that may forget previous information, while we propose an innovative model that includes simple yet powerful transformer-based motion and text encoders, which can learn representations from the two different modalities and capture long-term dependencies. Furthermore, the overlap of the same atomic actions of different human motions can cause semantic conflicts, leading us to explore a new triplet loss function, MildTriple Loss. it leverages the similarity between samples in intra-modal space to guide soft-hard negative sample mining in the joint embedding space to train the triplet loss and reduce the violation caused by false negative samples. We evaluated our model and method on the latest HumanML3D and KIT Motion-Language datasets, achieving a 62.9\% recall for motion retrieval and a 71.5\% recall for text retrieval (based on R@10) on the HumanML3D dataset. Our code is available at https://github.com/eanson023/rehamot.
Adaptive Detection of Dim Maneuvering Targets in Adjacent Range Cells
Mar 07, 2021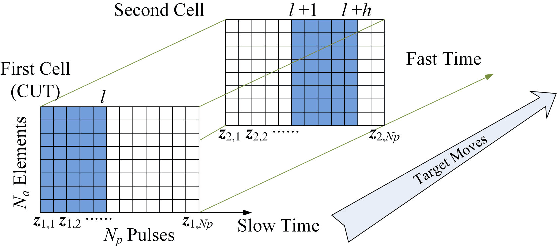
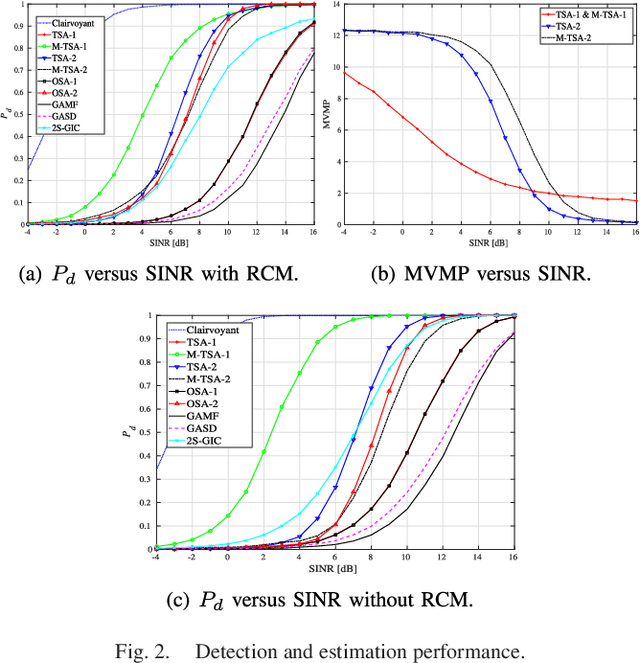
This letter addresses the detection problem of dim maneuvering targets in the presence of range cell migration. Specifically, it is assumed that the moving target can appear in more than one range cell within the transmitted pulse train. Then, the Bayesian information criterion and the generalized likelihood ratio test design procedure are jointly exploited to come up with six adaptive decision schemes capable of estimating the range indices related to the target migration. The computational complexity of the proposed detectors is also studied and suitably reduced. Simulation results show the effectiveness of the newly proposed solutions also for a limited set of training data and in comparison with suitable counterparts.