 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBTL-UI: Blink-Think-Link Reasoning Model for GUI Agent
Sep 19, 2025In the field of AI-driven human-GUI interaction automation, while rapid advances in multimodal large language models and reinforcement fine-tuning techniques have yielded remarkable progress, a fundamental challenge persists: their interaction logic significantly deviates from natural human-GUI communication patterns. To fill this gap, we propose "Blink-Think-Link" (BTL), a brain-inspired framework for human-GUI interaction that mimics the human cognitive process between users and graphical interfaces. The system decomposes interactions into three biologically plausible phases: (1) Blink - rapid detection and attention to relevant screen areas, analogous to saccadic eye movements; (2) Think - higher-level reasoning and decision-making, mirroring cognitive planning; and (3) Link - generation of executable commands for precise motor control, emulating human action selection mechanisms. Additionally, we introduce two key technical innovations for the BTL framework: (1) Blink Data Generation - an automated annotation pipeline specifically optimized for blink data, and (2) BTL Reward -- the first rule-based reward mechanism that enables reinforcement learning driven by both process and outcome. Building upon this framework, we develop a GUI agent model named BTL-UI, which demonstrates consistent state-of-the-art performance across both static GUI understanding and dynamic interaction tasks in comprehensive benchmarks. These results provide conclusive empirical validation of the framework's efficacy in developing advanced GUI Agents.
Edge Intelligence with Spiking Neural Networks
Jul 18, 2025The convergence of artificial intelligence and edge computing has spurred growing interest in enabling intelligent services directly on resource-constrained devices. While traditional deep learning models require significant computational resources and centralized data management, the resulting latency, bandwidth consumption, and privacy concerns have exposed critical limitations in cloud-centric paradigms. Brain-inspired computing, particularly Spiking Neural Networks (SNNs), offers a promising alternative by emulating biological neuronal dynamics to achieve low-power, event-driven computation. This survey provides a comprehensive overview of Edge Intelligence based on SNNs (EdgeSNNs), examining their potential to address the challenges of on-device learning, inference, and security in edge scenarios. We present a systematic taxonomy of EdgeSNN foundations, encompassing neuron models, learning algorithms, and supporting hardware platforms. Three representative practical considerations of EdgeSNN are discussed in depth: on-device inference using lightweight SNN models, resource-aware training and updating under non-stationary data conditions, and secure and privacy-preserving issues. Furthermore, we highlight the limitations of evaluating EdgeSNNs on conventional hardware and introduce a dual-track benchmarking strategy to support fair comparisons and hardware-aware optimization. Through this study, we aim to bridge the gap between brain-inspired learning and practical edge deployment, offering insights into current advancements, open challenges, and future research directions. To the best of our knowledge, this is the first dedicated and comprehensive survey on EdgeSNNs, providing an essential reference for researchers and practitioners working at the intersection of neuromorphic computing and edge intelligence.
Revolutionizing Brain Tumor Imaging: Generating Synthetic 3D FA Maps from T1-Weighted MRI using CycleGAN Models
May 06, 2025Fractional anisotropy (FA) and directionally encoded colour (DEC) maps are essential for evaluating white matter integrity and structural connectivity in neuroimaging. However, the spatial misalignment between FA maps and tractography atlases hinders their effective integration into predictive models. To address this issue, we propose a CycleGAN based approach for generating FA maps directly from T1-weighted MRI scans, representing the first application of this technique to both healthy and tumour-affected tissues. Our model, trained on unpaired data, produces high fidelity maps, which have been rigorously evaluated using Structural Similarity Index (SSIM) and Peak Signal-to-Noise Ratio (PSNR), demonstrating particularly robust performance in tumour regions. Radiological assessments further underscore the model's potential to enhance clinical workflows by providing an AI-driven alternative that reduces the necessity for additional scans.
Concept Enhancement Engineering: A Lightweight and Efficient Robust Defense Against Jailbreak Attacks in Embodied AI
Apr 15, 2025


Embodied Intelligence (EI) systems integrated with large language models (LLMs) face significant security risks, particularly from jailbreak attacks that manipulate models into generating harmful outputs or executing unsafe physical actions. Traditional defense strategies, such as input filtering and output monitoring, often introduce high computational overhead or interfere with task performance in real-time embodied scenarios. To address these challenges, we propose Concept Enhancement Engineering (CEE), a novel defense framework that leverages representation engineering to enhance the safety of embodied LLMs by dynamically steering their internal activations. CEE operates by (1) extracting multilingual safety patterns from model activations, (2) constructing control directions based on safety-aligned concept subspaces, and (3) applying subspace concept rotation to reinforce safe behavior during inference. Our experiments demonstrate that CEE effectively mitigates jailbreak attacks while maintaining task performance, outperforming existing defense methods in both robustness and efficiency. This work contributes a scalable and interpretable safety mechanism for embodied AI, bridging the gap between theoretical representation engineering and practical security applications. Our findings highlight the potential of latent-space interventions as a viable defense paradigm against emerging adversarial threats in physically grounded AI systems.
Dendritic Localized Learning: Toward Biologically Plausible Algorithm
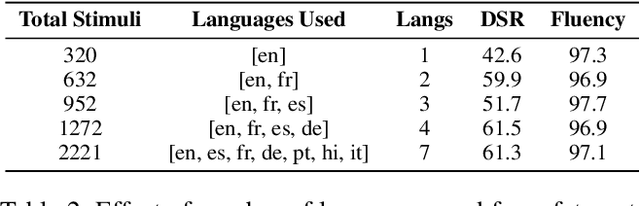
Jan 17, 2025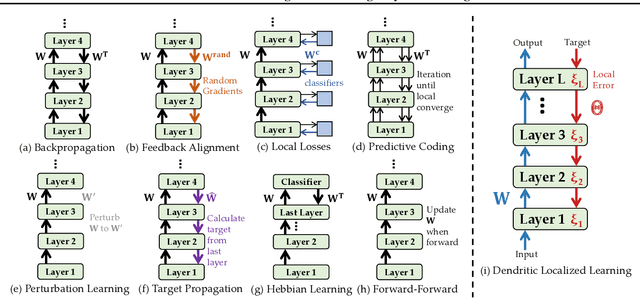
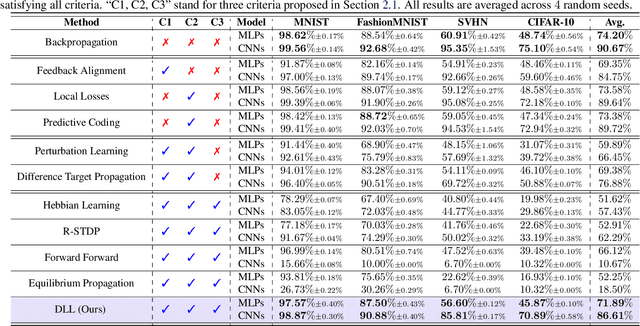
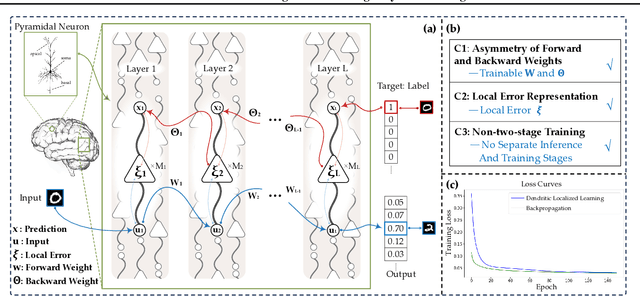

Backpropagation is the foundational algorithm for training neural networks and a key driver of deep learning's success. However, its biological plausibility has been challenged due to three primary limitations: weight symmetry, reliance on global error signals, and the dual-phase nature of training, as highlighted by the existing literature. Although various alternative learning approaches have been proposed to address these issues, most either fail to satisfy all three criteria simultaneously or yield suboptimal results. Inspired by the dynamics and plasticity of pyramidal neurons, we propose Dendritic Localized Learning (DLL), a novel learning algorithm designed to overcome these challenges. Extensive empirical experiments demonstrate that DLL satisfies all three criteria of biological plausibility while achieving state-of-the-art performance among algorithms that meet these requirements. Furthermore, DLL exhibits strong generalization across a range of architectures, including MLPs, CNNs, and RNNs. These results, benchmarked against existing biologically plausible learning algorithms, offer valuable empirical insights for future research. We hope this study can inspire the development of new biologically plausible algorithms for training multilayer networks and advancing progress in both neuroscience and machine learning.
FedLEC: Effective Federated Learning Algorithm with Spiking Neural Networks Under Label Skews
Dec 23, 2024With the advancement of neuromorphic chips, implementing Federated Learning (FL) with Spiking Neural Networks (SNNs) potentially offers a more energy-efficient schema for collaborative learning across various resource-constrained edge devices. However, one significant challenge in the FL systems is that the data from different clients are often non-independently and identically distributed (non-IID), with label skews presenting substantial difficulties in various federated SNN learning tasks. In this study, we propose a practical post-hoc framework named FedLEC to address the challenge. This framework penalizes the corresponding local logits for locally missing labels to enhance each local model's generalization ability. Additionally, it leverages the pertinent label distribution information distilled from the global model to mitigate label bias. Extensive experiments with three different structured SNNs across five datasets (i.e., three non-neuromorphic and two neuromorphic datasets) demonstrate the efficiency of FedLEC. Compared to seven state-of-the-art FL algorithms, FedLEC achieves an average accuracy improvement of approximately 11.59\% under various label skew distribution settings.
THz Channels for Short-Range Mobile Networks: Multipath Clusters and Human Body Shadowing
Dec 18, 2024The THz band (0.1-10 THz) is emerging as a crucial enabler for sixth-generation (6G) mobile communication systems, overcoming the limitations of current technologies and unlocking new opportunities for low-latency and ultra-high-speed communications by utilizing several tens of GHz transmission bandwidths. However, extremely high spreading losses and other interaction losses pose significant challenges to establishing wide-area communication coverage, while human body shadowing further complicates maintaining stable communication links. Although point-to-point (P2P) fixed wireless access in the THz band has been successfully demonstrated, realizing fully mobile and reliable wireless access remains a challenge due to numerous issues to be solved for highly directional communication. To provide insights into the design of THz communication systems, this article addresses the challenges associated with THz short-range mobile access networks. It offers an overview of recent findings on the environment-dependence of multipath cluster channel properties and the impact of human body shadowing, based on measurements at 300 GHz using a double-directional high-resolution channel sounder and a motion capture-integrated channel sounder.
Information-Theoretic Generative Clustering of Documents
Dec 18, 2024We present {\em generative clustering} (GC) for clustering a set of documents, $\mathrm{X}$, by using texts $\mathrm{Y}$ generated by large language models (LLMs) instead of by clustering the original documents $\mathrm{X}$. Because LLMs provide probability distributions, the similarity between two documents can be rigorously defined in an information-theoretic manner by the KL divergence. We also propose a natural, novel clustering algorithm by using importance sampling. We show that GC achieves the state-of-the-art performance, outperforming any previous clustering method often by a large margin. Furthermore, we show an application to generative document retrieval in which documents are indexed via hierarchical clustering and our method improves the retrieval accuracy.
Efficient Joint Precoding Design for Wideband Intelligent Reflecting Surface-Assisted Cell-Free Network
Dec 07, 2024In this paper, we propose an efficient joint precoding design method to maximize the weighted sum-rate in wideband intelligent reflecting surface (IRS)-assisted cell-free networks by jointly optimizing the active beamforming of base stations and the passive beamforming of IRS. Due to employing wideband transmissions, the frequency selectivity of IRSs has to been taken into account, whose response usually follows a Lorentzian-like profile. To address the high-dimensional non-convex optimization problem, we employ a fractional programming approach to decouple the non-convex problem into subproblems for alternating optimization between active and passive beamforming. The active beamforming subproblem is addressed using the consensus alternating direction method of multipliers (CADMM) algorithm, while the passive beamforming subproblem is tackled using the accelerated projection gradient (APG) method and Flecher-Reeves conjugate gradient method (FRCG). Simulation results demonstrate that our proposed approach achieves significant improvements in weighted sum-rate under various performance metrics compared to primal-dual subgradient (PDS) with ideal reflection matrix. This study provides valuable insights for computational complexity reduction and network capacity enhancement.
An Asynchronous Multi-core Accelerator for SNN inference
Jul 30, 2024



Spiking Neural Networks (SNNs) are extensively utilized in brain-inspired computing and neuroscience research. To enhance the speed and energy efficiency of SNNs, several many-core accelerators have been developed. However, maintaining the accuracy of SNNs often necessitates frequent explicit synchronization among all cores, which presents a challenge to overall efficiency. In this paper, we propose an asynchronous architecture for Spiking Neural Networks (SNNs) that eliminates the need for inter-core synchronization, thus enhancing speed and energy efficiency. This approach leverages the pre-determined dependencies of neuromorphic cores established during compilation. Each core is equipped with a scheduler that monitors the status of its dependencies, allowing it to safely advance to the next timestep without waiting for other cores. This eliminates the necessity for global synchronization and minimizes core waiting time despite inherent workload imbalances. Comprehensive evaluations using five different SNN workloads show that our architecture achieves a 1.86x speedup and a 1.55x increase in energy efficiency compared to state-of-the-art synchronization architectures.