 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefix Probing: Lightweight Harmful Content Detection for Large Language Models
Dec 18, 2025Large language models often face a three-way trade-off among detection accuracy, inference latency, and deployment cost when used in real-world safety-sensitive applications. This paper introduces Prefix Probing, a black-box harmful content detection method that compares the conditional log-probabilities of "agreement/execution" versus "refusal/safety" opening prefixes and leverages prefix caching to reduce detection overhead to near first-token latency. During inference, the method requires only a single log-probability computation over the probe prefixes to produce a harmfulness score and apply a threshold, without invoking any additional models or multi-stage inference. To further enhance the discriminative power of the prefixes, we design an efficient prefix construction algorithm that automatically discovers highly informative prefixes, substantially improving detection performance. Extensive experiments demonstrate that Prefix Probing achieves detection effectiveness comparable to mainstream external safety models while incurring only minimal computational cost and requiring no extra model deployment, highlighting its strong practicality and efficiency.
N-GLARE: An Non-Generative Latent Representation-Efficient LLM Safety Evaluator
Nov 18, 2025Evaluating the safety robustness of LLMs is critical for their deployment. However, mainstream Red Teaming methods rely on online generation and black-box output analysis. These approaches are not only costly but also suffer from feedback latency, making them unsuitable for agile diagnostics after training a new model. To address this, we propose N-GLARE (A Non-Generative, Latent Representation-Efficient LLM Safety Evaluator). N-GLARE operates entirely on the model's latent representations, bypassing the need for full text generation. It characterizes hidden layer dynamics by analyzing the APT (Angular-Probabilistic Trajectory) of latent representations and introducing the JSS (Jensen-Shannon Separability) metric. Experiments on over 40 models and 20 red teaming strategies demonstrate that the JSS metric exhibits high consistency with the safety rankings derived from Red Teaming. N-GLARE reproduces the discriminative trends of large-scale red-teaming tests at less than 1\% of the token cost and the runtime cost, providing an efficient output-free evaluation proxy for real-time diagnostics.
Concept Enhancement Engineering: A Lightweight and Efficient Robust Defense Against Jailbreak Attacks in Embodied AI
Apr 15, 2025


Embodied Intelligence (EI) systems integrated with large language models (LLMs) face significant security risks, particularly from jailbreak attacks that manipulate models into generating harmful outputs or executing unsafe physical actions. Traditional defense strategies, such as input filtering and output monitoring, often introduce high computational overhead or interfere with task performance in real-time embodied scenarios. To address these challenges, we propose Concept Enhancement Engineering (CEE), a novel defense framework that leverages representation engineering to enhance the safety of embodied LLMs by dynamically steering their internal activations. CEE operates by (1) extracting multilingual safety patterns from model activations, (2) constructing control directions based on safety-aligned concept subspaces, and (3) applying subspace concept rotation to reinforce safe behavior during inference. Our experiments demonstrate that CEE effectively mitigates jailbreak attacks while maintaining task performance, outperforming existing defense methods in both robustness and efficiency. This work contributes a scalable and interpretable safety mechanism for embodied AI, bridging the gap between theoretical representation engineering and practical security applications. Our findings highlight the potential of latent-space interventions as a viable defense paradigm against emerging adversarial threats in physically grounded AI systems.
Ambiguity-Free Broadband DOA Estimation Relying on Parameterized Time-Frequency Transform
Mar 05, 2025An ambiguity-free direction-of-arrival (DOA) estimation scheme is proposed for sparse uniform linear arrays under low signal-to-noise ratios (SNRs) and non-stationary broadband signals. First, for achieving better DOA estimation performance at low SNRs while using non-stationary signals compared to the conventional frequency-difference (FD) paradigms, we propose parameterized time-frequency transform-based FD processing. Then, the unambiguous compressive FD beamforming is conceived to compensate the resolution loss induced by difference operation. Finally, we further derive a coarse-to-fine histogram statistics scheme to alleviate the perturbation in compressive FD beamforming with good DOA estimation accuracy. Simulation results demonstrate the superior performance of our proposed algorithm regarding robustness, resolution, and DOA estimation accuracy.
Backdoor Attack on Vertical Federated Graph Neural Network Learning
Oct 15, 2024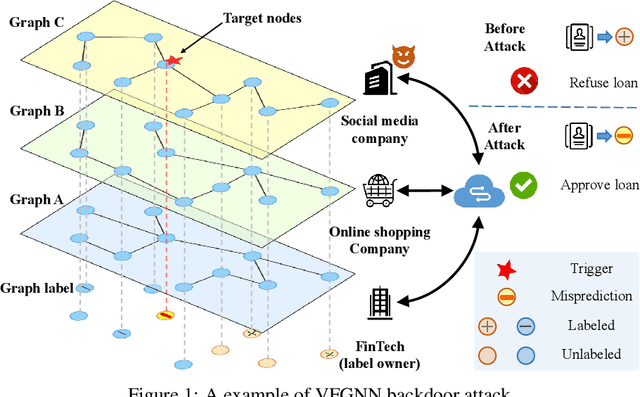
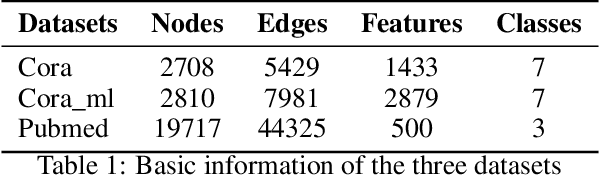
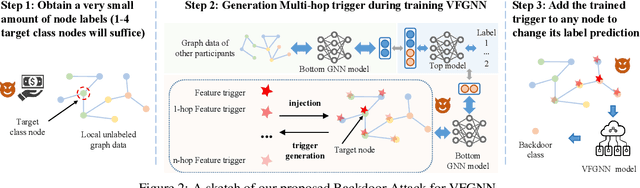
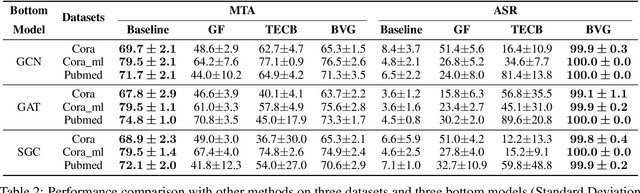
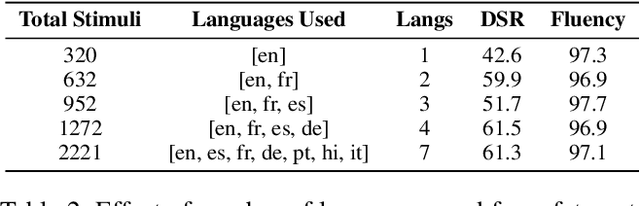
Federated Graph Neural Network (FedGNN) is a privacy-preserving machine learning technology that combines federated learning (FL) and graph neural networks (GNNs). It offers a privacy-preserving solution for training GNNs using isolated graph data. Vertical Federated Graph Neural Network (VFGNN) is an important branch of FedGNN, where data features and labels are distributed among participants, and each participant has the same sample space. Due to the difficulty of accessing and modifying distributed data and labels, the vulnerability of VFGNN to backdoor attacks remains largely unexplored. In this context, we propose BVG, the first method for backdoor attacks in VFGNN. Without accessing or modifying labels, BVG uses multi-hop triggers and requires only four target class nodes for an effective backdoor attack. Experiments show that BVG achieves high attack success rates (ASR) across three datasets and three different GNN models, with minimal impact on main task accuracy (MTA). We also evaluate several defense methods, further validating the robustness and effectiveness of BVG. This finding also highlights the need for advanced defense mechanisms to counter sophisticated backdoor attacks in practical VFGNN applications.
UIFV: Data Reconstruction Attack in Vertical Federated Learning
Jun 18, 2024



Vertical Federated Learning (VFL) facilitates collaborative machine learning without the need for participants to share raw private data. However, recent studies have revealed privacy risks where adversaries might reconstruct sensitive features through data leakage during the learning process. Although data reconstruction methods based on gradient or model information are somewhat effective, they reveal limitations in VFL application scenarios. This is because these traditional methods heavily rely on specific model structures and/or have strict limitations on application scenarios. To address this, our study introduces the Unified InverNet Framework into VFL, which yields a novel and flexible approach (dubbed UIFV) that leverages intermediate feature data to reconstruct original data, instead of relying on gradients or model details. The intermediate feature data is the feature exchanged by different participants during the inference phase of VFL. Experiments on four datasets demonstrate that our methods significantly outperform state-of-the-art techniques in attack precision. Our work exposes severe privacy vulnerabilities within VFL systems that pose real threats to practical VFL applications and thus confirms the necessity of further enhancing privacy protection in the VFL architecture.
PatchDCT: Patch Refinement for High Quality Instance Segmentation
Feb 07, 2023
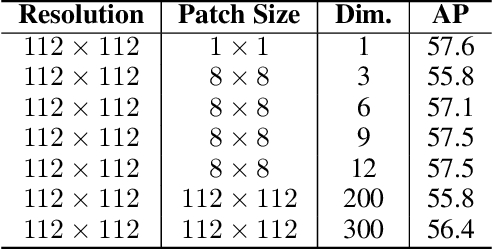
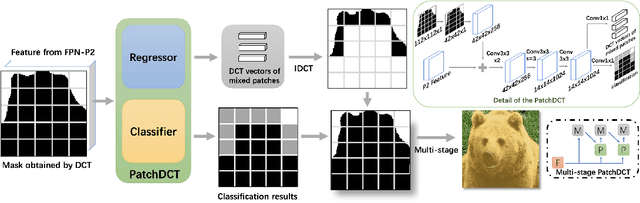
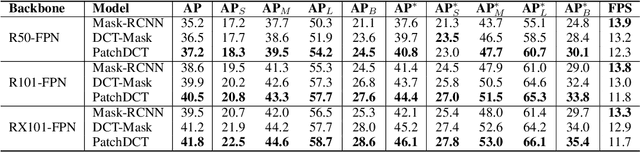
High-quality instance segmentation has shown emerging importance in computer vision. Without any refinement, DCT-Mask directly generates high-resolution masks by compressed vectors. To further refine masks obtained by compressed vectors, we propose for the first time a compressed vector based multi-stage refinement framework. However, the vanilla combination does not bring significant gains, because changes in some elements of the DCT vector will affect the prediction of the entire mask. Thus, we propose a simple and novel method named PatchDCT, which separates the mask decoded from a DCT vector into several patches and refines each patch by the designed classifier and regressor. Specifically, the classifier is used to distinguish mixed patches from all patches, and to correct previously mispredicted foreground and background patches. In contrast, the regressor is used for DCT vector prediction of mixed patches, further refining the segmentation quality at boundary locations. Experiments on COCO show that our method achieves 2.0%, 3.2%, 4.5% AP and 3.4%, 5.3%, 7.0% Boundary AP improvements over Mask-RCNN on COCO, LVIS, and Cityscapes, respectively. It also surpasses DCT-Mask by 0.7%, 1.1%, 1.3% AP and 0.9%, 1.7%, 4.2% Boundary AP on COCO, LVIS and Cityscapes. Besides, the performance of PatchDCT is also competitive with other state-of-the-art methods.
The KFIoU Loss for Rotated Object Detection
Feb 01, 2022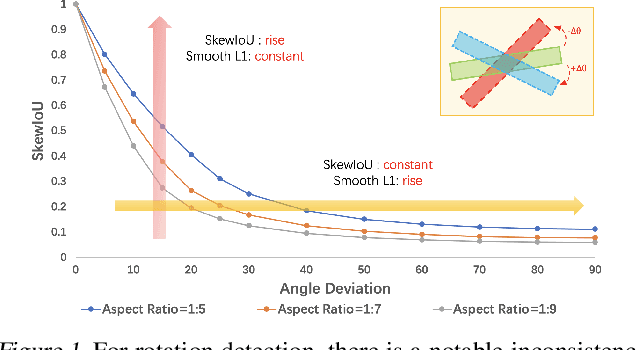
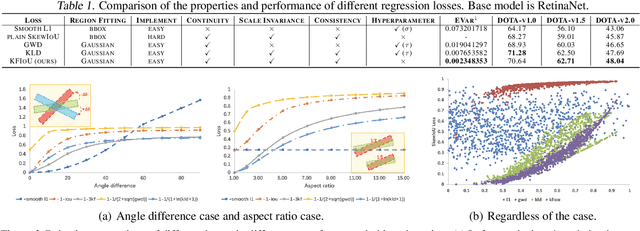
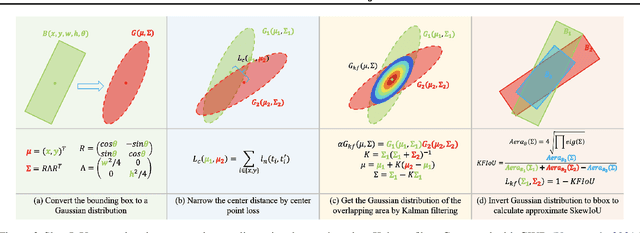

Differing from the well-developed horizontal object detection area whereby the computing-friendly IoU based loss is readily adopted and well fits with the detection metrics. In contrast, rotation detectors often involve a more complicated loss based on SkewIoU which is unfriendly to gradient-based training. In this paper, we argue that one effective alternative is to devise an approximate loss who can achieve trend-level alignment with SkewIoU loss instead of the strict value-level identity. Specifically, we model the objects as Gaussian distribution and adopt Kalman filter to inherently mimic the mechanism of SkewIoU by its definition, and show its alignment with the SkewIoU at trend-level. This is in contrast to recent Gaussian modeling based rotation detectors e.g. GWD, KLD that involves a human-specified distribution distance metric which requires additional hyperparameter tuning. The resulting new loss called KFIoU is easier to implement and works better compared with exact SkewIoU, thanks to its full differentiability and ability to handle the non-overlapping cases. We further extend our technique to the 3-D case which also suffers from the same issues as 2-D detection. Extensive results on various public datasets (2-D/3-D, aerial/text/face images) with different base detectors show the effectiveness of our approach.
Learning High-Precision Bounding Box for Rotated Object Detection via Kullback-Leibler Divergence
Jun 04, 2021



Existing rotated object detectors are mostly inherited from the horizontal detection paradigm, as the latter has evolved into a well-developed area. However, these detectors are difficult to perform prominently in high-precision detection due to the limitation of current regression loss design, especially for objects with large aspect ratios. Taking the perspective that horizontal detection is a special case for rotated object detection, in this paper, we are motivated to change the design of rotation regression loss from induction paradigm to deduction methodology, in terms of the relation between rotation and horizontal detection. We show that one essential challenge is how to modulate the coupled parameters in the rotation regression loss, as such the estimated parameters can influence to each other during the dynamic joint optimization, in an adaptive and synergetic way. Specifically, we first convert the rotated bounding box into a 2-D Gaussian distribution, and then calculate the Kullback-Leibler Divergence (KLD) between the Gaussian distributions as the regression loss. By analyzing the gradient of each parameter, we show that KLD (and its derivatives) can dynamically adjust the parameter gradients according to the characteristics of the object. It will adjust the importance (gradient weight) of the angle parameter according to the aspect ratio. This mechanism can be vital for high-precision detection as a slight angle error would cause a serious accuracy drop for large aspect ratios objects. More importantly, we have proved that KLD is scale invariant. We further show that the KLD loss can be degenerated into the popular $l_{n}$-norm loss for horizontal detection. Experimental results on seven datasets using different detectors show its consistent superiority, and codes are available at https://github.com/yangxue0827/RotationDetection.
DCT-Mask: Discrete Cosine Transform Mask Representation for Instance Segmentation
Nov 19, 2020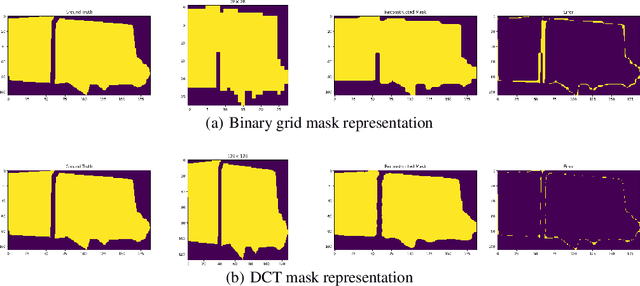
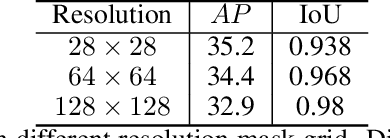
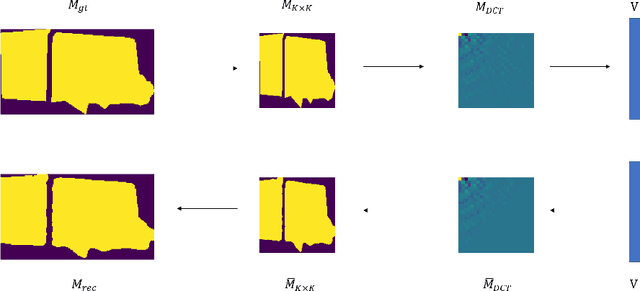
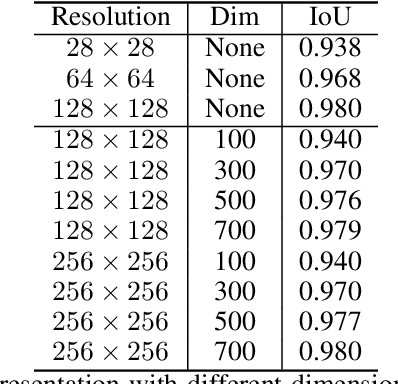
Binary grid mask representation is broadly used in instance segmentation. A representative instantiation is Mask R-CNN which predicts masks on a $28\times 28$ binary grid. Generally, a low-resolution grid is not sufficient to capture the details, while a high-resolution grid dramatically increases the training complexity. In this paper, we propose a new mask representation by applying the discrete cosine transform(DCT) to encode the high-resolution binary grid mask into a compact vector. Our method, termed DCT-Mask, could be easily integrated into most pixel-based instance segmentation methods. Without any bells and whistles, DCT-Mask yields significant gains on different frameworks, backbones, datasets, and training schedules. It does not require any pre-processing or pre-training, and almost no harm to the running speed. Especially, for higher-quality annotations and more complex backbones, our method has a greater improvement. Moreover, we analyze the performance of our method from the perspective of the quality of mask representation. The main reason why DCT-Mask works well is that it obtains a high-quality mask representation with low complexity. Code will be made available.