 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCDNet: Multi-UAV Collaborative 3D Object Detection Network by Reliable Feature Mapping
Jun 07, 2024Multi-UAV collaborative 3D object detection can perceive and comprehend complex environments by integrating complementary information, with applications encompassing traffic monitoring, delivery services and agricultural management. However, the extremely broad observations in aerial remote sensing and significant perspective differences across multiple UAVs make it challenging to achieve precise and consistent feature mapping from 2D images to 3D space in multi-UAV collaborative 3D object detection paradigm. To address the problem, we propose an unparalleled camera-based multi-UAV collaborative 3D object detection paradigm called UCDNet. Specifically, the depth information from the UAVs to the ground is explicitly utilized as a strong prior to provide a reference for more accurate and generalizable feature mapping. Additionally, we design a homologous points geometric consistency loss as an auxiliary self-supervision, which directly influences the feature mapping module, thereby strengthening the global consistency of multi-view perception. Experiments on AeroCollab3D and CoPerception-UAVs datasets show our method increases 4.7% and 10% mAP respectively compared to the baseline, which demonstrates the superiority of UCDNet.
SiamTHN: Siamese Target Highlight Network for Visual Tracking
Mar 22, 2023



Siamese network based trackers develop rapidly in the field of visual object tracking in recent years. The majority of siamese network based trackers now in use treat each channel in the feature maps generated by the backbone network equally, making the similarity response map sensitive to background influence and hence challenging to focus on the target region. Additionally, there are no structural links between the classification and regression branches in these trackers, and the two branches are optimized separately during training. Therefore, there is a misalignment between the classification and regression branches, which results in less accurate tracking results. In this paper, a Target Highlight Module is proposed to help the generated similarity response maps to be more focused on the target region. To reduce the misalignment and produce more precise tracking results, we propose a corrective loss to train the model. The two branches of the model are jointly tuned with the use of corrective loss to produce more reliable prediction results. Experiments on 5 challenging benchmark datasets reveal that the method outperforms current models in terms of performance, and runs at 38 fps, proving its effectiveness and efficiency.
Ship Instance Segmentation From Remote Sensing Images Using Sequence Local Context Module
Apr 22, 2019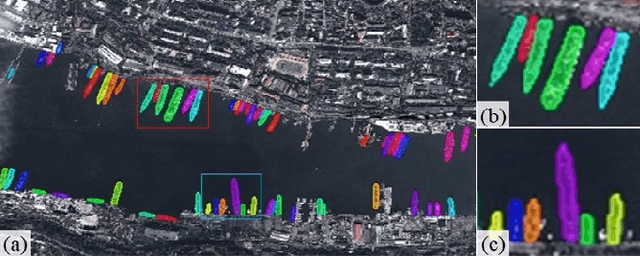
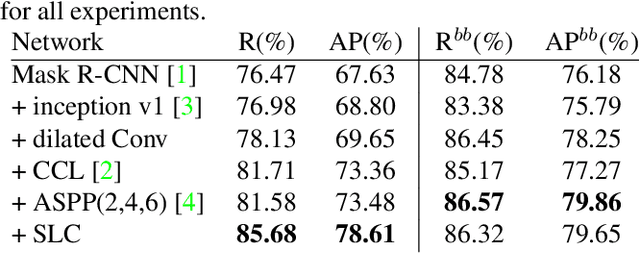
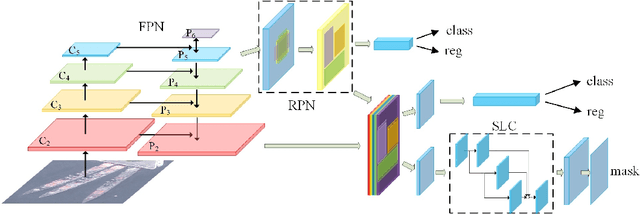

The performance of object instance segmentation in remote sensing images has been greatly improved through the introduction of many landmark frameworks based on convolutional neural network. However, the object densely issue still affects the accuracy of such segmentation frameworks. Objects of the same class are easily confused, which is most likely due to the close docking between objects. We think context information is critical to address this issue. So, we propose a novel framework called SLCMASK-Net, in which a sequence local context module (SLC) is introduced to avoid confusion between objects of the same class. The SLC module applies a sequence of dilation convolution blocks to progressively learn multi-scale context information in the mask branch. Besides, we try to add SLC module to different locations in our framework and experiment with the effect of different parameter settings. Comparative experiments are conducted on remote sensing images acquired by QuickBird with a resolution of $0.5m-1m$ and the results show that the proposed method achieves state-of-the-art performance.
Comparison Network for One-Shot Conditional Object Detection
Apr 04, 2019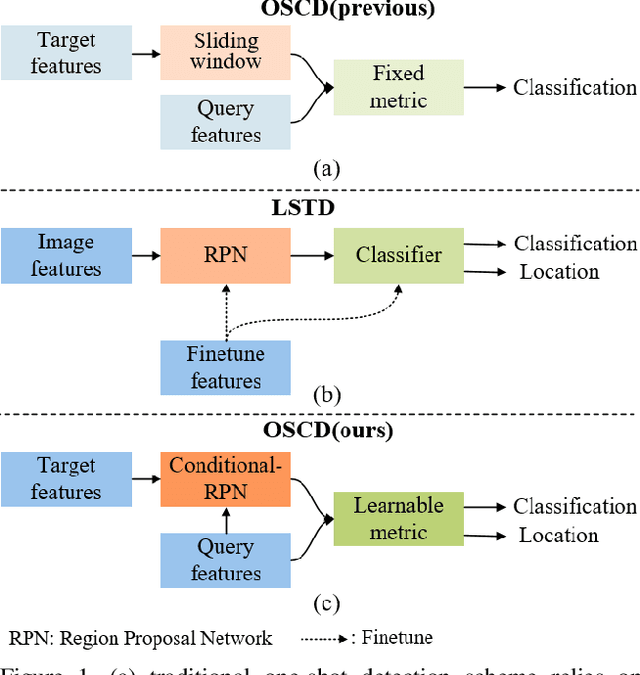
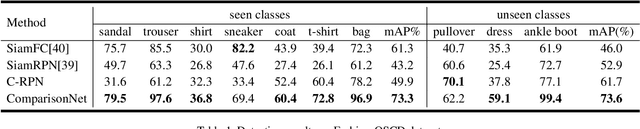

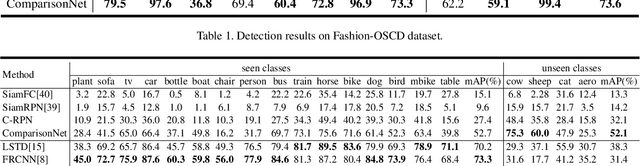
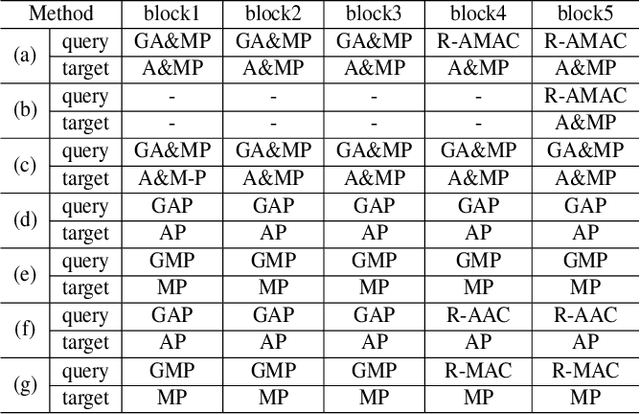
The current advances in object detection depend on large-scale datasets to get good performance. However, there may not always be sufficient samples in many scenarios, which leads to the research on few-shot detection as well as its extreme variation one-shot detection. In this paper, the one-shot detection has been formulated as a conditional probability problem. With this insight, a novel one-shot conditional object detection (OSCD) framework, referred as Comparison Network (ComparisonNet), has been proposed. Specifically, query and target image features are extracted through a Siamese network as mapped metrics of marginal probabilities. A two-stage detector for OSCD is introduced to compare the extracted query and target features with the learnable metric to approach the optimized non-linear conditional probability. Once trained, ComparisonNet can detect objects of both seen and unseen classes without further training, which also has the advantages including class-agnostic, training-free for unseen classes, and without catastrophic forgetting. Experiments show that the proposed approach achieves state-of-the-art performance on the proposed datasets of Fashion-MNIST and PASCAL VOC.
A Training-free, One-shot Detection Framework For Geospatial Objects In Remote Sensing Images
Apr 04, 2019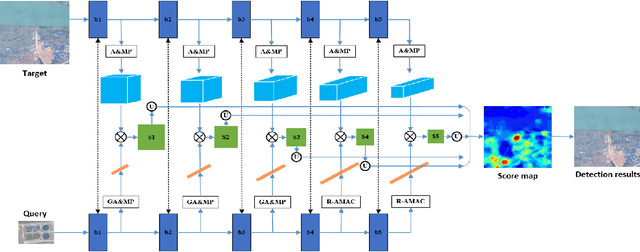
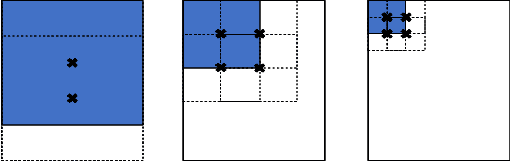
Deep learning based object detection has achieved great success. However, these supervised learning methods are data-hungry and time-consuming. This restriction makes them unsuitable for limited data and urgent tasks, especially in the applications of remote sensing. Inspired by the ability of humans to quickly learn new visual concepts from very few examples, we propose a training-free, one-shot geospatial object detection framework for remote sensing images. It consists of (1) a feature extractor with remote sensing domain knowledge, (2) a multi-level feature fusion method, (3) a novel similarity metric method, and (4) a 2-stage object detection pipeline. Experiments on sewage treatment plant and airport detections show that proposed method has achieved a certain effect. Our method can serve as a baseline for training-free, one-shot geospatial object detection.
R2CNN++: Multi-Dimensional Attention Based Rotation Invariant Detector with Robust Anchor Strategy
Nov 20, 2018
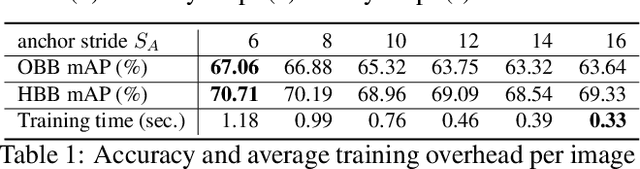
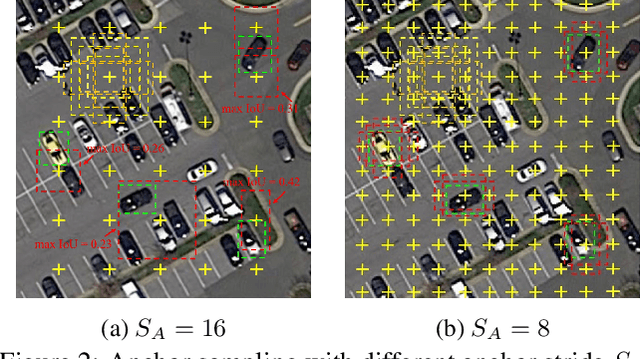
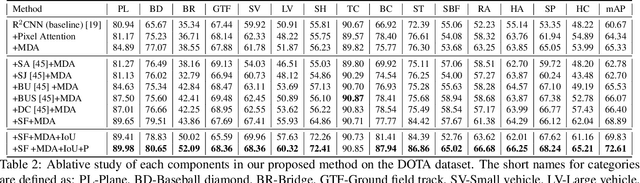
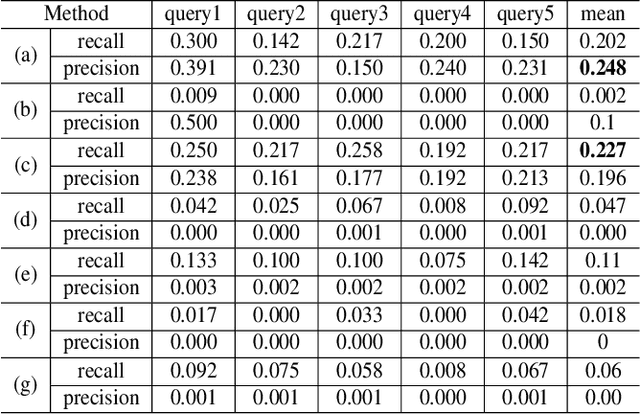
Object detection plays a vital role in natural scene and aerial scene and is full of challenges. Although many advanced algorithms have succeeded in the natural scene, the progress in the aerial scene has been slow due to the complexity of the aerial image and the large degree of freedom of remote sensing objects in scale, orientation, and density. In this paper, a novel multi-category rotation detector is proposed, which can efficiently detect small objects, arbitrary direction objects, and dense objects in complex remote sensing images. Specifically, the proposed model adopts a targeted feature fusion strategy called inception fusion network, which fully considers factors such as feature fusion, anchor sampling, and receptive field to improve the ability to handle small objects. Then we combine the pixel attention network and the channel attention network to weaken the noise information and highlight the objects feature. Finally, the rotational object detection algorithm is realized by redefining the rotating bounding box. Experiments on public datasets including DOTA, NWPU VHR-10 demonstrate that the proposed algorithm significantly outperforms state-of-the-art methods. The code and models will be available at https://github.com/DetectionTeamUCAS/R2CNN-Plus-Plus_Tensorflow.
Position Detection and Direction Prediction for Arbitrary-Oriented Ships via Multiscale Rotation Region Convolutional Neural Network
Jun 13, 2018


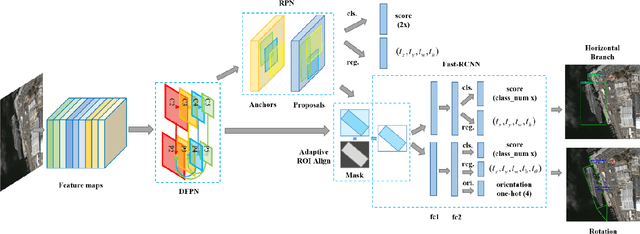
Ship detection is of great importance and full of challenges in the field of remote sensing. The complexity of application scenarios, the redundancy of detection region, and the difficulty of dense ship detection are all the main obstacles that limit the successful operation of traditional methods in ship detection. In this paper, we propose a brand new detection model based on multiscale rotational region convolutional neural network to solve the problems above. This model is mainly consist of five consecutive parts: Dense Feature Pyramid Network (DFPN), adaptive region of interest (ROI) Align, rotational bounding box regression, prow direction prediction and rotational nonmaximum suppression (R-NMS). First of all, the low-level location information and high-level semantic information are fully utilized through multiscale feature networks. Then, we design adaptive ROI Align to obtain high quality proposals which remain complete spatial and semantic information. Unlike most previous approaches, the prediction obtained by our method is the minimum bounding rectangle of the object with less redundant regions. Therefore, rotational region detection framework is more suitable to detect the dense object than traditional detection model. Additionally, we can find the berthing and sailing direction of ship through prediction. A detailed evaluation based on SRSS and DOTA dataset for rotation detection shows that our detection method has a competitive performance.
Automatic Ship Detection of Remote Sensing Images from Google Earth in Complex Scenes Based on Multi-Scale Rotation Dense Feature Pyramid Networks
Jun 12, 2018
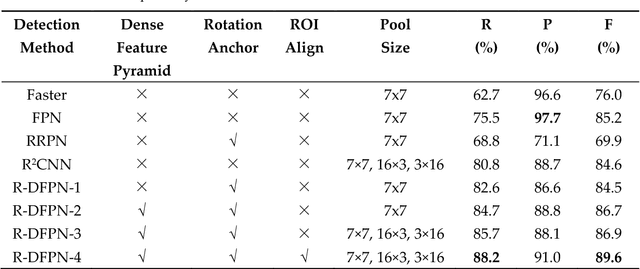
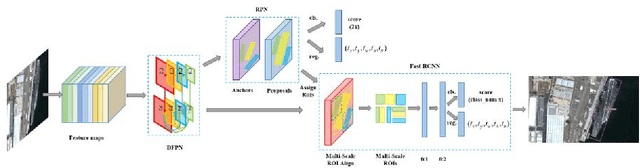

Ship detection has been playing a significant role in the field of remote sensing for a long time but it is still full of challenges. The main limitations of traditional ship detection methods usually lie in the complexity of application scenarios, the difficulty of intensive object detection and the redundancy of detection region. In order to solve such problems above, we propose a framework called Rotation Dense Feature Pyramid Networks (R-DFPN) which can effectively detect ship in different scenes including ocean and port. Specifically, we put forward the Dense Feature Pyramid Network (DFPN), which is aimed at solving the problem resulted from the narrow width of the ship. Compared with previous multi-scale detectors such as Feature Pyramid Network (FPN), DFPN builds the high-level semantic feature-maps for all scales by means of dense connections, through which enhances the feature propagation and encourages the feature reuse. Additionally, in the case of ship rotation and dense arrangement, we design a rotation anchor strategy to predict the minimum circumscribed rectangle of the object so as to reduce the redundant detection region and improve the recall. Furthermore, we also propose multi-scale ROI Align for the purpose of maintaining the completeness of semantic and spatial information. Experiments based on remote sensing images from Google Earth for ship detection show that our detection method based on R-DFPN representation has a state-of-the-art performance.
* 14 pages, 11 figures