 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemStereo: Semantic-Constrained Stereo Matching Network for Remote Sensing
Dec 17, 2024



Semantic segmentation and 3D reconstruction are two fundamental tasks in remote sensing, typically treated as separate or loosely coupled tasks. Despite attempts to integrate them into a unified network, the constraints between the two heterogeneous tasks are not explicitly modeled, since the pioneering studies either utilize a loosely coupled parallel structure or engage in only implicit interactions, failing to capture the inherent connections. In this work, we explore the connections between the two tasks and propose a new network that imposes semantic constraints on the stereo matching task, both implicitly and explicitly. Implicitly, we transform the traditional parallel structure to a new cascade structure termed Semantic-Guided Cascade structure, where the deep features enriched with semantic information are utilized for the computation of initial disparity maps, enhancing semantic guidance. Explicitly, we propose a Semantic Selective Refinement (SSR) module and a Left-Right Semantic Consistency (LRSC) module. The SSR refines the initial disparity map under the guidance of the semantic map. The LRSC ensures semantic consistency between two views via reducing the semantic divergence after transforming the semantic map from one view to the other using the disparity map. Experiments on the US3D and WHU datasets demonstrate that our method achieves state-of-the-art performance for both semantic segmentation and stereo matching.
UVCPNet: A UAV-Vehicle Collaborative Perception Network for 3D Object Detection
Jun 07, 2024With the advancement of collaborative perception, the role of aerial-ground collaborative perception, a crucial component, is becoming increasingly important. The demand for collaborative perception across different perspectives to construct more comprehensive perceptual information is growing. However, challenges arise due to the disparities in the field of view between cross-domain agents and their varying sensitivity to information in images. Additionally, when we transform image features into Bird's Eye View (BEV) features for collaboration, we need accurate depth information. To address these issues, we propose a framework specifically designed for aerial-ground collaboration. First, to mitigate the lack of datasets for aerial-ground collaboration, we develop a virtual dataset named V2U-COO for our research. Second, we design a Cross-Domain Cross-Adaptation (CDCA) module to align the target information obtained from different domains, thereby achieving more accurate perception results. Finally, we introduce a Collaborative Depth Optimization (CDO) module to obtain more precise depth estimation results, leading to more accurate perception outcomes. We conduct extensive experiments on both our virtual dataset and a public dataset to validate the effectiveness of our framework. Our experiments on the V2U-COO dataset and the DAIR-V2X dataset demonstrate that our method improves detection accuracy by 6.1% and 2.7%, respectively.
RingMo-lite: A Remote Sensing Multi-task Lightweight Network with CNN-Transformer Hybrid Framework
Sep 16, 2023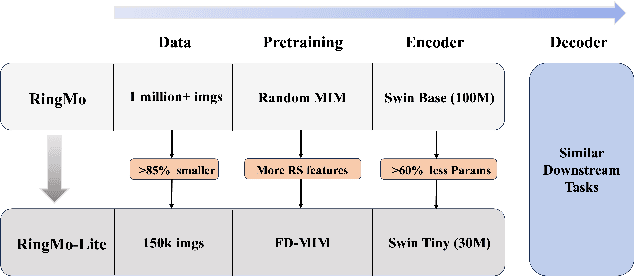
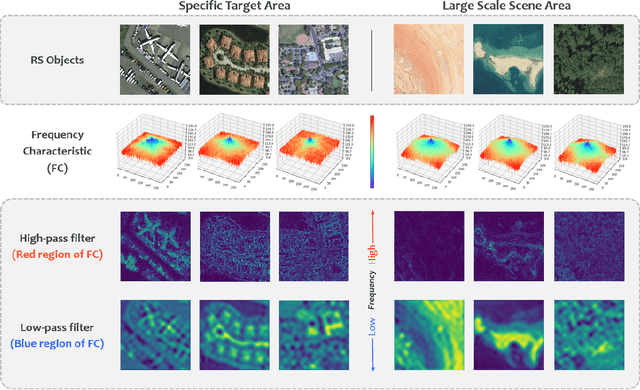
In recent years, remote sensing (RS) vision foundation models such as RingMo have emerged and achieved excellent performance in various downstream tasks. However, the high demand for computing resources limits the application of these models on edge devices. It is necessary to design a more lightweight foundation model to support on-orbit RS image interpretation. Existing methods face challenges in achieving lightweight solutions while retaining generalization in RS image interpretation. This is due to the complex high and low-frequency spectral components in RS images, which make traditional single CNN or Vision Transformer methods unsuitable for the task. Therefore, this paper proposes RingMo-lite, an RS multi-task lightweight network with a CNN-Transformer hybrid framework, which effectively exploits the frequency-domain properties of RS to optimize the interpretation process. It is combined by the Transformer module as a low-pass filter to extract global features of RS images through a dual-branch structure, and the CNN module as a stacked high-pass filter to extract fine-grained details effectively. Furthermore, in the pretraining stage, the designed frequency-domain masked image modeling (FD-MIM) combines each image patch's high-frequency and low-frequency characteristics, effectively capturing the latent feature representation in RS data. As shown in Fig. 1, compared with RingMo, the proposed RingMo-lite reduces the parameters over 60% in various RS image interpretation tasks, the average accuracy drops by less than 2% in most of the scenes and achieves SOTA performance compared to models of the similar size. In addition, our work will be integrated into the MindSpore computing platform in the near future.
SiamTHN: Siamese Target Highlight Network for Visual Tracking
Mar 22, 2023



Siamese network based trackers develop rapidly in the field of visual object tracking in recent years. The majority of siamese network based trackers now in use treat each channel in the feature maps generated by the backbone network equally, making the similarity response map sensitive to background influence and hence challenging to focus on the target region. Additionally, there are no structural links between the classification and regression branches in these trackers, and the two branches are optimized separately during training. Therefore, there is a misalignment between the classification and regression branches, which results in less accurate tracking results. In this paper, a Target Highlight Module is proposed to help the generated similarity response maps to be more focused on the target region. To reduce the misalignment and produce more precise tracking results, we propose a corrective loss to train the model. The two branches of the model are jointly tuned with the use of corrective loss to produce more reliable prediction results. Experiments on 5 challenging benchmark datasets reveal that the method outperforms current models in terms of performance, and runs at 38 fps, proving its effectiveness and efficiency.
Elevation Estimation-Driven Building 3D Reconstruction from Single-View Remote Sensing Imagery
Jan 11, 2023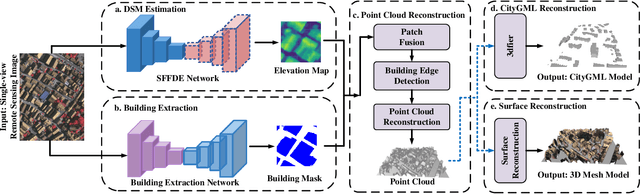


Building 3D reconstruction from remote sensing images has a wide range of applications in smart cities, photogrammetry and other fields. Methods for automatic 3D urban building modeling typically employ multi-view images as input to algorithms to recover point clouds and 3D models of buildings. However, such models rely heavily on multi-view images of buildings, which are time-intensive and limit the applicability and practicality of the models. To solve these issues, we focus on designing an efficient DSM estimation-driven reconstruction framework (Building3D), which aims to reconstruct 3D building models from the input single-view remote sensing image. First, we propose a Semantic Flow Field-guided DSM Estimation (SFFDE) network, which utilizes the proposed concept of elevation semantic flow to achieve the registration of local and global features. Specifically, in order to make the network semantics globally aware, we propose an Elevation Semantic Globalization (ESG) module to realize the semantic globalization of instances. Further, in order to alleviate the semantic span of global features and original local features, we propose a Local-to-Global Elevation Semantic Registration (L2G-ESR) module based on elevation semantic flow. Our Building3D is rooted in the SFFDE network for building elevation prediction, synchronized with a building extraction network for building masks, and then sequentially performs point cloud reconstruction, surface reconstruction (or CityGML model reconstruction). On this basis, our Building3D can optionally generate CityGML models or surface mesh models of the buildings. Extensive experiments on ISPRS Vaihingen and DFC2019 datasets on the DSM estimation task show that our SFFDE significantly improves upon state-of-the-arts. Furthermore, our Building3D achieves impressive results in the 3D point cloud and 3D model reconstruction process.