 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyVoice: Long-Context Conditioning for Anthropomorphic Multi-Speaker Conversational Synthesis
Dec 22, 2025Large speech generation models are evolving from single-speaker, short sentence synthesis to multi-speaker, long conversation geneartion. Current long-form speech generation models are predominately constrained to dyadic, turn-based interactions. To address this, we introduce JoyVoice, a novel anthropomorphic foundation model designed for flexible, boundary-free synthesis of up to eight speakers. Unlike conventional cascaded systems, JoyVoice employs a unified E2E-Transformer-DiT architecture that utilizes autoregressive hidden representations directly for diffusion inputs, enabling holistic end-to-end optimization. We further propose a MM-Tokenizer operating at a low bitrate of 12.5 Hz, which integrates multitask semantic and MMSE losses to effectively model both semantic and acoustic information. Additionally, the model incorporates robust text front-end processing via large-scale data perturbation. Experiments show that JoyVoice achieves state-of-the-art results in multilingual generation (Chinese, English, Japanese, Korean) and zero-shot voice cloning. JoyVoice achieves top-tier results on both the Seed-TTS-Eval Benchmark and multi-speaker long-form conversational voice cloning tasks, demonstrating superior audio quality and generalization. It achieves significant improvements in prosodic continuity for long-form speech, rhythm richness in multi-speaker conversations, paralinguistic naturalness, besides superior intelligibility. We encourage readers to listen to the demo at https://jea-speech.github.io/JoyVoice
Balanced 3DGS: Gaussian-wise Parallelism Rendering with Fine-Grained Tiling
Dec 23, 2024



3D Gaussian Splatting (3DGS) is increasingly attracting attention in both academia and industry owing to its superior visual quality and rendering speed. However, training a 3DGS model remains a time-intensive task, especially in load imbalance scenarios where workload diversity among pixels and Gaussian spheres causes poor renderCUDA kernel performance. We introduce Balanced 3DGS, a Gaussian-wise parallelism rendering with fine-grained tiling approach in 3DGS training process, perfectly solving load-imbalance issues. First, we innovatively introduce the inter-block dynamic workload distribution technique to map workloads to Streaming Multiprocessor(SM) resources within a single GPU dynamically, which constitutes the foundation of load balancing. Second, we are the first to propose the Gaussian-wise parallel rendering technique to significantly reduce workload divergence inside a warp, which serves as a critical component in addressing load imbalance. Based on the above two methods, we further creatively put forward the fine-grained combined load balancing technique to uniformly distribute workload across all SMs, which boosts the forward renderCUDA kernel performance by up to 7.52x. Besides, we present a self-adaptive render kernel selection strategy during the 3DGS training process based on different load-balance situations, which effectively improves training efficiency.
Mapping Information in Feature Extraction Transformation for Chirp Signal
Jan 10, 2024Chirp signals have established diverse applications caused by the capable of producing time-dependent linear frequencies. Most feature extraction transformation methods for chirp signals focus on enhancing the performance of transform methods but neglecting the information derived from the transformation process. Consequently, they may fail to fully exploit the information from observations, resulting in decreased performance under conditions of low signal-to-noise ratio and limited observations. In this work, we develop a novel post-processing method called mapping information model to addressing this challenge. The model establishes a link between the observation space and feature space in feature extraction transform, enabling interference suppression and obtain more accurate information by iteratively resampling and assigning weights in both spaces. Analysis of the iteration process reveals a continual increase in weight of signal samples and a gradual stability in weight of noise samples. The demonstration of the noise suppression in the iteration process and feature enhancement supports the effectiveness of the mapping information model. Furthermore, numerical simulations also affirm the high efficiency of the proposed model by showcasing enhanced signal detection and estimation performances without requiring additional observations. This superior model allows amplifying performance within feature extraction transformation for chirp signal processing under low SNR and limited observation conditions, opens up new opportunities for areas such as communication, biomedicine, and remote sensing.
RingMo-lite: A Remote Sensing Multi-task Lightweight Network with CNN-Transformer Hybrid Framework
Sep 16, 2023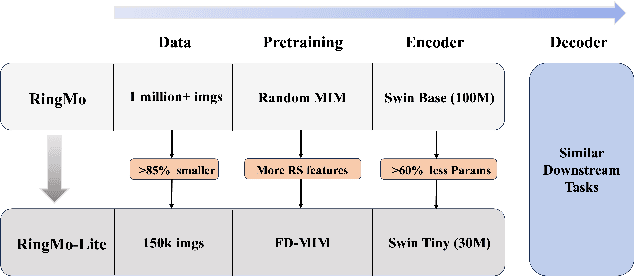
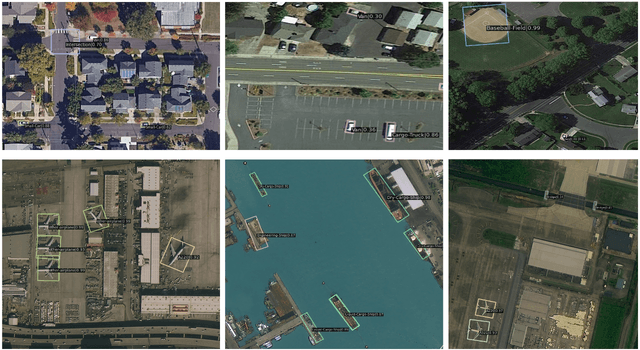
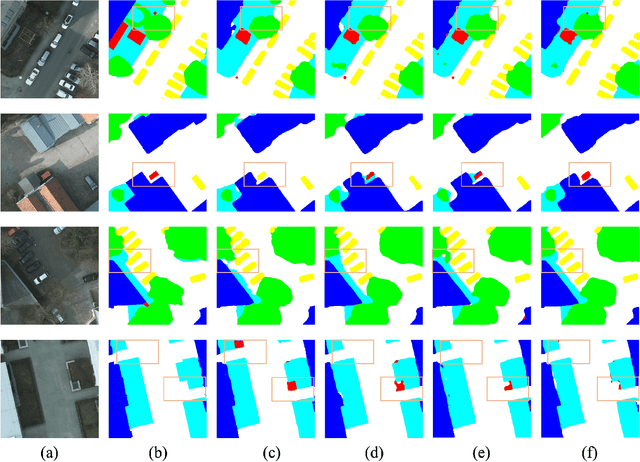
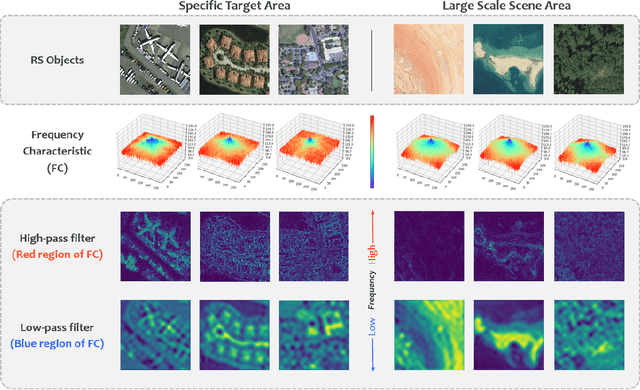
In recent years, remote sensing (RS) vision foundation models such as RingMo have emerged and achieved excellent performance in various downstream tasks. However, the high demand for computing resources limits the application of these models on edge devices. It is necessary to design a more lightweight foundation model to support on-orbit RS image interpretation. Existing methods face challenges in achieving lightweight solutions while retaining generalization in RS image interpretation. This is due to the complex high and low-frequency spectral components in RS images, which make traditional single CNN or Vision Transformer methods unsuitable for the task. Therefore, this paper proposes RingMo-lite, an RS multi-task lightweight network with a CNN-Transformer hybrid framework, which effectively exploits the frequency-domain properties of RS to optimize the interpretation process. It is combined by the Transformer module as a low-pass filter to extract global features of RS images through a dual-branch structure, and the CNN module as a stacked high-pass filter to extract fine-grained details effectively. Furthermore, in the pretraining stage, the designed frequency-domain masked image modeling (FD-MIM) combines each image patch's high-frequency and low-frequency characteristics, effectively capturing the latent feature representation in RS data. As shown in Fig. 1, compared with RingMo, the proposed RingMo-lite reduces the parameters over 60% in various RS image interpretation tasks, the average accuracy drops by less than 2% in most of the scenes and achieves SOTA performance compared to models of the similar size. In addition, our work will be integrated into the MindSpore computing platform in the near future.