 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet Experts Feel Uncertainty: A Multi-Expert Label Distribution Approach to Probabilistic Time Series Forecasting
Feb 04, 2026Time series forecasting in real-world applications requires both high predictive accuracy and interpretable uncertainty quantification. Traditional point prediction methods often fail to capture the inherent uncertainty in time series data, while existing probabilistic approaches struggle to balance computational efficiency with interpretability. We propose a novel Multi-Expert Learning Distributional Labels (LDL) framework that addresses these challenges through mixture-of-experts architectures with distributional learning capabilities. Our approach introduces two complementary methods: (1) Multi-Expert LDL, which employs multiple experts with different learned parameters to capture diverse temporal patterns, and (2) Pattern-Aware LDL-MoE, which explicitly decomposes time series into interpretable components (trend, seasonality, changepoints, volatility) through specialized sub-experts. Both frameworks extend traditional point prediction to distributional learning, enabling rich uncertainty quantification through Maximum Mean Discrepancy (MMD). We evaluate our methods on aggregated sales data derived from the M5 dataset, demonstrating superior performance compared to baseline approaches. The continuous Multi-Expert LDL achieves the best overall performance, while the Pattern-Aware LDL-MoE provides enhanced interpretability through component-wise analysis. Our frameworks successfully balance predictive accuracy with interpretability, making them suitable for real-world forecasting applications where both performance and actionable insights are crucial.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
WEDepth: Efficient Adaptation of World Knowledge for Monocular Depth Estimation
Nov 11, 2025Monocular depth estimation (MDE) has widely applicable but remains highly challenging due to the inherently ill-posed nature of reconstructing 3D scenes from single 2D images. Modern Vision Foundation Models (VFMs), pre-trained on large-scale diverse datasets, exhibit remarkable world understanding capabilities that benefit for various vision tasks. Recent studies have demonstrated significant improvements in MDE through fine-tuning these VFMs. Inspired by these developments, we propose WEDepth, a novel approach that adapts VFMs for MDE without modi-fying their structures and pretrained weights, while effec-tively eliciting and leveraging their inherent priors. Our method employs the VFM as a multi-level feature en-hancer, systematically injecting prior knowledge at differ-ent representation levels. Experiments on NYU-Depth v2 and KITTI datasets show that WEDepth establishes new state-of-the-art (SOTA) performance, achieving competi-tive results compared to both diffusion-based approaches (which require multiple forward passes) and methods pre-trained on relative depth. Furthermore, we demonstrate our method exhibits strong zero-shot transfer capability across diverse scenarios.
Partial Weakly-Supervised Oriented Object Detection
Jul 03, 2025
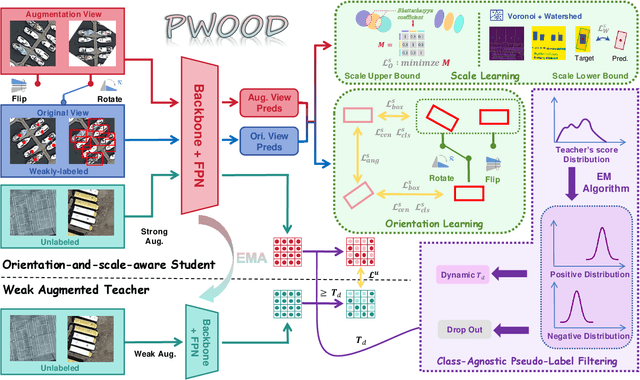


The growing demand for oriented object detection (OOD) across various domains has driven significant research in this area. However, the high cost of dataset annotation remains a major concern. Current mainstream OOD algorithms can be mainly categorized into three types: (1) fully supervised methods using complete oriented bounding box (OBB) annotations, (2) semi-supervised methods using partial OBB annotations, and (3) weakly supervised methods using weak annotations such as horizontal boxes or points. However, these algorithms inevitably increase the cost of models in terms of annotation speed or annotation cost. To address this issue, we propose:(1) the first Partial Weakly-Supervised Oriented Object Detection (PWOOD) framework based on partially weak annotations (horizontal boxes or single points), which can efficiently leverage large amounts of unlabeled data, significantly outperforming weakly supervised algorithms trained with partially weak annotations, also offers a lower cost solution; (2) Orientation-and-Scale-aware Student (OS-Student) model capable of learning orientation and scale information with only a small amount of orientation-agnostic or scale-agnostic weak annotations; and (3) Class-Agnostic Pseudo-Label Filtering strategy (CPF) to reduce the model's sensitivity to static filtering thresholds. Comprehensive experiments on DOTA-v1.0/v1.5/v2.0 and DIOR datasets demonstrate that our PWOOD framework performs comparably to, or even surpasses, traditional semi-supervised algorithms.
SA-Occ: Satellite-Assisted 3D Occupancy Prediction in Real World
Mar 20, 2025

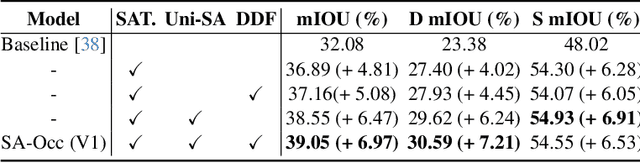
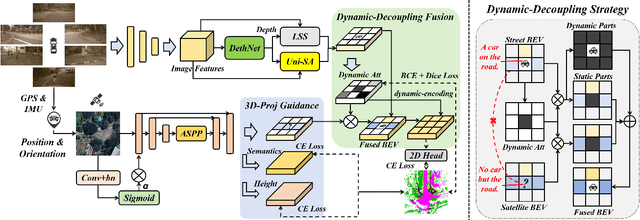
Existing vision-based 3D occupancy prediction methods are inherently limited in accuracy due to their exclusive reliance on street-view imagery, neglecting the potential benefits of incorporating satellite views. We propose SA-Occ, the first Satellite-Assisted 3D occupancy prediction model, which leverages GPS & IMU to integrate historical yet readily available satellite imagery into real-time applications, effectively mitigating limitations of ego-vehicle perceptions, involving occlusions and degraded performance in distant regions. To address the core challenges of cross-view perception, we propose: 1) Dynamic-Decoupling Fusion, which resolves inconsistencies in dynamic regions caused by the temporal asynchrony between satellite and street views; 2) 3D-Proj Guidance, a module that enhances 3D feature extraction from inherently 2D satellite imagery; and 3) Uniform Sampling Alignment, which aligns the sampling density between street and satellite views. Evaluated on Occ3D-nuScenes, SA-Occ achieves state-of-the-art performance, especially among single-frame methods, with a 39.05% mIoU (a 6.97% improvement), while incurring only 6.93 ms of additional latency per frame. Our code and newly curated dataset are available at https://github.com/chenchen235/SA-Occ.
OpenGV 2.0: Motion prior-assisted calibration and SLAM with vehicle-mounted surround-view systems
Mar 05, 2025



The present paper proposes optimization-based solutions to visual SLAM with a vehicle-mounted surround-view camera system. Owing to their original use-case, such systems often only contain a single camera facing into either direction and very limited overlap between fields of view. Our novelty consist of three optimization modules targeting at practical online calibration of exterior orientations from simple two-view geometry, reliable front-end initialization of relative displacements, and accurate back-end optimization using a continuous-time trajectory model. The commonality between the proposed modules is given by the fact that all three of them exploit motion priors that are related to the inherent non-holonomic characteristics of passenger vehicle motion. In contrast to prior related art, the proposed modules furthermore excel in terms of bypassing partial unobservabilities in the transformation variables that commonly occur for Ackermann-motion. As a further contribution, the modules are built into a novel surround-view camera SLAM system that specifically targets deployment on Ackermann vehicles operating in urban environments. All modules are studied in the context of in-depth ablation studies, and the practical validity of the entire framework is supported by a successful application to challenging, large-scale publicly available online datasets. Note that upon acceptance, the entire framework is scheduled for open-source release as part of an extension of the OpenGV library.
SemStereo: Semantic-Constrained Stereo Matching Network for Remote Sensing
Dec 17, 2024



Semantic segmentation and 3D reconstruction are two fundamental tasks in remote sensing, typically treated as separate or loosely coupled tasks. Despite attempts to integrate them into a unified network, the constraints between the two heterogeneous tasks are not explicitly modeled, since the pioneering studies either utilize a loosely coupled parallel structure or engage in only implicit interactions, failing to capture the inherent connections. In this work, we explore the connections between the two tasks and propose a new network that imposes semantic constraints on the stereo matching task, both implicitly and explicitly. Implicitly, we transform the traditional parallel structure to a new cascade structure termed Semantic-Guided Cascade structure, where the deep features enriched with semantic information are utilized for the computation of initial disparity maps, enhancing semantic guidance. Explicitly, we propose a Semantic Selective Refinement (SSR) module and a Left-Right Semantic Consistency (LRSC) module. The SSR refines the initial disparity map under the guidance of the semantic map. The LRSC ensures semantic consistency between two views via reducing the semantic divergence after transforming the semantic map from one view to the other using the disparity map. Experiments on the US3D and WHU datasets demonstrate that our method achieves state-of-the-art performance for both semantic segmentation and stereo matching.
Physics-Guided Detector for SAR Airplanes
Nov 19, 2024The disperse structure distributions (discreteness) and variant scattering characteristics (variability) of SAR airplane targets lead to special challenges of object detection and recognition. The current deep learning-based detectors encounter challenges in distinguishing fine-grained SAR airplanes against complex backgrounds. To address it, we propose a novel physics-guided detector (PGD) learning paradigm for SAR airplanes that comprehensively investigate their discreteness and variability to improve the detection performance. It is a general learning paradigm that can be extended to different existing deep learning-based detectors with "backbone-neck-head" architectures. The main contributions of PGD include the physics-guided self-supervised learning, feature enhancement, and instance perception, denoted as PGSSL, PGFE, and PGIP, respectively. PGSSL aims to construct a self-supervised learning task based on a wide range of SAR airplane targets that encodes the prior knowledge of various discrete structure distributions into the embedded space. Then, PGFE enhances the multi-scale feature representation of a detector, guided by the physics-aware information learned from PGSSL. PGIP is constructed at the detection head to learn the refined and dominant scattering point of each SAR airplane instance, thus alleviating the interference from the complex background. We propose two implementations, denoted as PGD and PGD-Lite, and apply them to various existing detectors with different backbones and detection heads. The experiments demonstrate the flexibility and effectiveness of the proposed PGD, which can improve existing detectors on SAR airplane detection with fine-grained classification task (an improvement of 3.1\% mAP most), and achieve the state-of-the-art performance (90.7\% mAP) on SAR-AIRcraft-1.0 dataset. The project is open-source at \url{https://github.com/XAI4SAR/PGD}.
RS-DFM: A Remote Sensing Distributed Foundation Model for Diverse Downstream Tasks
Jun 11, 2024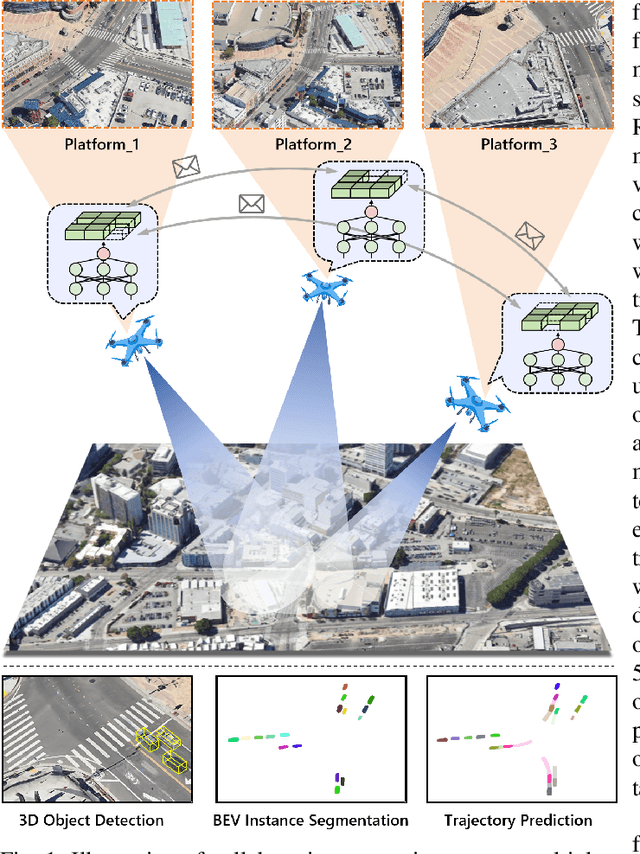
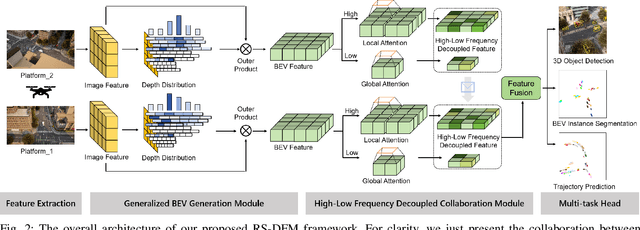
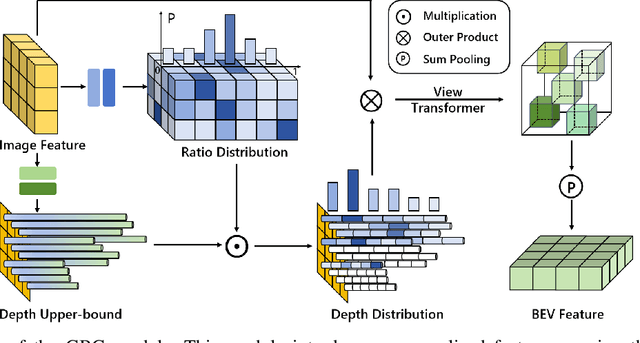
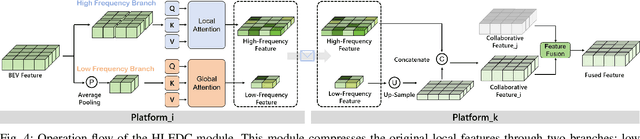
Remote sensing lightweight foundation models have achieved notable success in online perception within remote sensing. However, their capabilities are restricted to performing online inference solely based on their own observations and models, thus lacking a comprehensive understanding of large-scale remote sensing scenarios. To overcome this limitation, we propose a Remote Sensing Distributed Foundation Model (RS-DFM) based on generalized information mapping and interaction. This model can realize online collaborative perception across multiple platforms and various downstream tasks by mapping observations into a unified space and implementing a task-agnostic information interaction strategy. Specifically, we leverage the ground-based geometric prior of remote sensing oblique observations to transform the feature mapping from absolute depth estimation to relative depth estimation, thereby enhancing the model's ability to extract generalized features across diverse heights and perspectives. Additionally, we present a dual-branch information compression module to decouple high-frequency and low-frequency feature information, achieving feature-level compression while preserving essential task-agnostic details. In support of our research, we create a multi-task simulation dataset named AirCo-MultiTasks for multi-UAV collaborative observation. We also conduct extensive experiments, including 3D object detection, instance segmentation, and trajectory prediction. The numerous results demonstrate that our RS-DFM achieves state-of-the-art performance across various downstream tasks.
UCDNet: Multi-UAV Collaborative 3D Object Detection Network by Reliable Feature Mapping
Jun 07, 2024Multi-UAV collaborative 3D object detection can perceive and comprehend complex environments by integrating complementary information, with applications encompassing traffic monitoring, delivery services and agricultural management. However, the extremely broad observations in aerial remote sensing and significant perspective differences across multiple UAVs make it challenging to achieve precise and consistent feature mapping from 2D images to 3D space in multi-UAV collaborative 3D object detection paradigm. To address the problem, we propose an unparalleled camera-based multi-UAV collaborative 3D object detection paradigm called UCDNet. Specifically, the depth information from the UAVs to the ground is explicitly utilized as a strong prior to provide a reference for more accurate and generalizable feature mapping. Additionally, we design a homologous points geometric consistency loss as an auxiliary self-supervision, which directly influences the feature mapping module, thereby strengthening the global consistency of multi-view perception. Experiments on AeroCollab3D and CoPerception-UAVs datasets show our method increases 4.7% and 10% mAP respectively compared to the baseline, which demonstrates the superiority of UCDNet.