 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFNF: Functional Network Fingerprint for Large Language Models
Jan 30, 2026The development of large language models (LLMs) is costly and has significant commercial value. Consequently, preventing unauthorized appropriation of open-source LLMs and protecting developers' intellectual property rights have become critical challenges. In this work, we propose the Functional Network Fingerprint (FNF), a training-free, sample-efficient method for detecting whether a suspect LLM is derived from a victim model, based on the consistency between their functional network activity. We demonstrate that models that share a common origin, even with differences in scale or architecture, exhibit highly consistent patterns of neuronal activity within their functional networks across diverse input samples. In contrast, models trained independently on distinct data or with different objectives fail to preserve such activity alignment. Unlike conventional approaches, our method requires only a few samples for verification, preserves model utility, and remains robust to common model modifications (such as fine-tuning, pruning, and parameter permutation), as well as to comparisons across diverse architectures and dimensionalities. FNF thus provides model owners and third parties with a simple, non-invasive, and effective tool for protecting LLM intellectual property. The code is available at https://github.com/WhatAboutMyStar/LLM_ACTIVATION.
Granular-ball Guided Masking: Structure-aware Data Augmentation
Dec 24, 2025Deep learning models have achieved remarkable success in computer vision, but they still rely heavily on large-scale labeled data and tend to overfit when data are limited or distributions shift. Data augmentation, particularly mask-based information dropping, can enhance robustness by forcing models to explore complementary cues; however, existing approaches often lack structural awareness and may discard essential semantics. We propose Granular-ball Guided Masking (GBGM), a structure-aware augmentation strategy guided by Granular-ball Computing (GBC). GBGM adaptively preserves semantically rich, structurally important regions while suppressing redundant areas through a coarse-to-fine hierarchical masking process, producing augmentations that are both representative and discriminative. Extensive experiments on multiple benchmarks demonstrate consistent improvements in classification accuracy and masked image reconstruction, confirming the effectiveness and broad applicability of the proposed method. Simple and model-agnostic, it integrates seamlessly into CNNs and Vision Transformers and provides a new paradigm for structure-aware data augmentation.
Pruning Large Language Models by Identifying and Preserving Functional Networks
Aug 07, 2025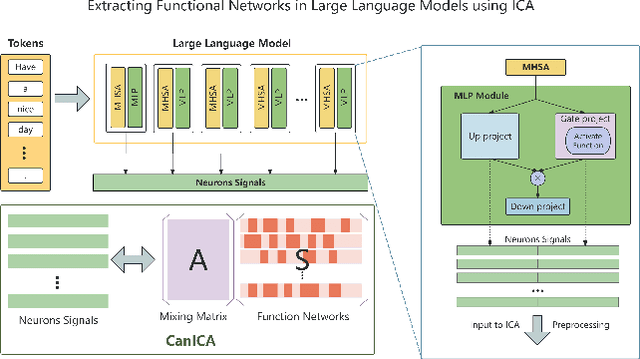
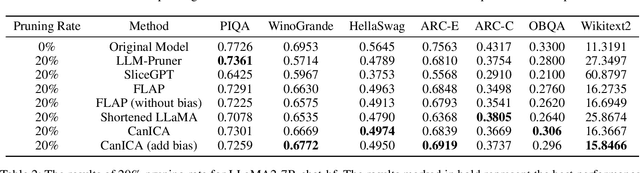
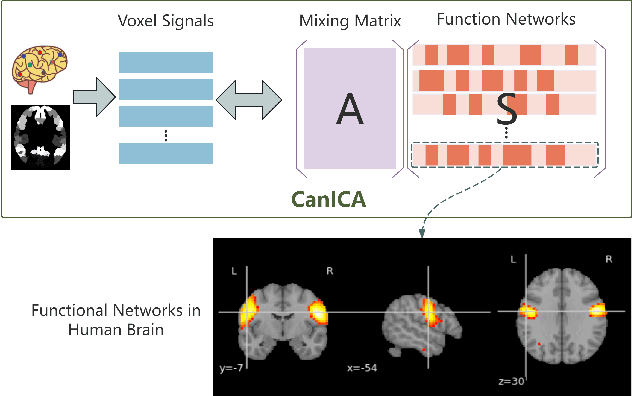

Structured pruning is one of the representative techniques for compressing large language models (LLMs) to reduce GPU memory consumption and accelerate inference speed. It offers significant practical value in improving the efficiency of LLMs in real-world applications. Current structured pruning methods typically rely on assessment of the importance of the structure units and pruning the units with less importance. Most of them overlooks the interaction and collaboration among artificial neurons that are crucial for the functionalities of LLMs, leading to a disruption in the macro functional architecture of LLMs and consequently a pruning performance degradation. Inspired by the inherent similarities between artificial neural networks and functional neural networks in the human brain, we alleviate this challenge and propose to prune LLMs by identifying and preserving functional networks within LLMs in this study. To achieve this, we treat an LLM as a digital brain and decompose the LLM into functional networks, analogous to identifying functional brain networks in neuroimaging data. Afterwards, an LLM is pruned by preserving the key neurons within these functional networks. Experimental results demonstrate that the proposed method can successfully identify and locate functional networks and key neurons in LLMs, enabling efficient model pruning. Our code is available at https://github.com/WhatAboutMyStar/LLM_ACTIVATION.
TAViS: Text-bridged Audio-Visual Segmentation with Foundation Models
Jun 13, 2025Audio-Visual Segmentation (AVS) faces a fundamental challenge of effectively aligning audio and visual modalities. While recent approaches leverage foundation models to address data scarcity, they often rely on single-modality knowledge or combine foundation models in an off-the-shelf manner, failing to address the cross-modal alignment challenge. In this paper, we present TAViS, a novel framework that \textbf{couples} the knowledge of multimodal foundation models (ImageBind) for cross-modal alignment and a segmentation foundation model (SAM2) for precise segmentation. However, effectively combining these models poses two key challenges: the difficulty in transferring the knowledge between SAM2 and ImageBind due to their different feature spaces, and the insufficiency of using only segmentation loss for supervision. To address these challenges, we introduce a text-bridged design with two key components: (1) a text-bridged hybrid prompting mechanism where pseudo text provides class prototype information while retaining modality-specific details from both audio and visual inputs, and (2) an alignment supervision strategy that leverages text as a bridge to align shared semantic concepts within audio-visual modalities. Our approach achieves superior performance on single-source, multi-source, semantic datasets, and excels in zero-shot settings.
Pursuing Temporal-Consistent Video Virtual Try-On via Dynamic Pose Interaction
May 22, 2025Video virtual try-on aims to seamlessly dress a subject in a video with a specific garment. The primary challenge involves preserving the visual authenticity of the garment while dynamically adapting to the pose and physique of the subject. While existing methods have predominantly focused on image-based virtual try-on, extending these techniques directly to videos often results in temporal inconsistencies. Most current video virtual try-on approaches alleviate this challenge by incorporating temporal modules, yet still overlook the critical spatiotemporal pose interactions between human and garment. Effective pose interactions in videos should not only consider spatial alignment between human and garment poses in each frame but also account for the temporal dynamics of human poses throughout the entire video. With such motivation, we propose a new framework, namely Dynamic Pose Interaction Diffusion Models (DPIDM), to leverage diffusion models to delve into dynamic pose interactions for video virtual try-on. Technically, DPIDM introduces a skeleton-based pose adapter to integrate synchronized human and garment poses into the denoising network. A hierarchical attention module is then exquisitely designed to model intra-frame human-garment pose interactions and long-term human pose dynamics across frames through pose-aware spatial and temporal attention mechanisms. Moreover, DPIDM capitalizes on a temporal regularized attention loss between consecutive frames to enhance temporal consistency. Extensive experiments conducted on VITON-HD, VVT and ViViD datasets demonstrate the superiority of our DPIDM against the baseline methods. Notably, DPIDM achieves VFID score of 0.506 on VVT dataset, leading to 60.5% improvement over the state-of-the-art GPD-VVTO approach.
CityGS-X: A Scalable Architecture for Efficient and Geometrically Accurate Large-Scale Scene Reconstruction
Mar 29, 2025Despite its significant achievements in large-scale scene reconstruction, 3D Gaussian Splatting still faces substantial challenges, including slow processing, high computational costs, and limited geometric accuracy. These core issues arise from its inherently unstructured design and the absence of efficient parallelization. To overcome these challenges simultaneously, we introduce CityGS-X, a scalable architecture built on a novel parallelized hybrid hierarchical 3D representation (PH^2-3D). As an early attempt, CityGS-X abandons the cumbersome merge-and-partition process and instead adopts a newly-designed batch-level multi-task rendering process. This architecture enables efficient multi-GPU rendering through dynamic Level-of-Detail voxel allocations, significantly improving scalability and performance. Through extensive experiments, CityGS-X consistently outperforms existing methods in terms of faster training times, larger rendering capacities, and more accurate geometric details in large-scale scenes. Notably, CityGS-X can train and render a scene with 5,000+ images in just 5 hours using only 4 * 4090 GPUs, a task that would make other alternative methods encounter Out-Of-Memory (OOM) issues and fail completely. This implies that CityGS-X is far beyond the capacity of other existing methods.
$\mathbfΦ$-GAN: Physics-Inspired GAN for Generating SAR Images Under Limited Data
Mar 04, 2025Approaches for improving generative adversarial networks (GANs) training under a few samples have been explored for natural images. However, these methods have limited effectiveness for synthetic aperture radar (SAR) images, as they do not account for the unique electromagnetic scattering properties of SAR. To remedy this, we propose a physics-inspired regularization method dubbed $\Phi$-GAN, which incorporates the ideal point scattering center (PSC) model of SAR with two physical consistency losses. The PSC model approximates SAR targets using physical parameters, ensuring that $\Phi$-GAN generates SAR images consistent with real physical properties while preventing discriminator overfitting by focusing on PSC-based decision cues. To embed the PSC model into GANs for end-to-end training, we introduce a physics-inspired neural module capable of estimating the physical parameters of SAR targets efficiently. This module retains the interpretability of the physical model and can be trained with limited data. We propose two physical loss functions: one for the generator, guiding it to produce SAR images with physical parameters consistent with real ones, and one for the discriminator, enhancing its robustness by basing decisions on PSC attributes. We evaluate $\Phi$-GAN across several conditional GAN (cGAN) models, demonstrating state-of-the-art performance in data-scarce scenarios on three SAR image datasets.
LangSurf: Language-Embedded Surface Gaussians for 3D Scene Understanding
Dec 24, 2024



Applying Gaussian Splatting to perception tasks for 3D scene understanding is becoming increasingly popular. Most existing works primarily focus on rendering 2D feature maps from novel viewpoints, which leads to an imprecise 3D language field with outlier languages, ultimately failing to align objects in 3D space. By utilizing masked images for feature extraction, these approaches also lack essential contextual information, leading to inaccurate feature representation. To this end, we propose a Language-Embedded Surface Field (LangSurf), which accurately aligns the 3D language fields with the surface of objects, facilitating precise 2D and 3D segmentation with text query, widely expanding the downstream tasks such as removal and editing. The core of LangSurf is a joint training strategy that flattens the language Gaussian on the object surfaces using geometry supervision and contrastive losses to assign accurate language features to the Gaussians of objects. In addition, we also introduce the Hierarchical-Context Awareness Module to extract features at the image level for contextual information then perform hierarchical mask pooling using masks segmented by SAM to obtain fine-grained language features in different hierarchies. Extensive experiments on open-vocabulary 2D and 3D semantic segmentation demonstrate that LangSurf outperforms the previous state-of-the-art method LangSplat by a large margin. As shown in Fig. 1, our method is capable of segmenting objects in 3D space, thus boosting the effectiveness of our approach in instance recognition, removal, and editing, which is also supported by comprehensive experiments. \url{https://langsurf.github.io}.
CoSurfGS:Collaborative 3D Surface Gaussian Splatting with Distributed Learning for Large Scene Reconstruction
Dec 23, 20243D Gaussian Splatting (3DGS) has demonstrated impressive performance in scene reconstruction. However, most existing GS-based surface reconstruction methods focus on 3D objects or limited scenes. Directly applying these methods to large-scale scene reconstruction will pose challenges such as high memory costs, excessive time consumption, and lack of geometric detail, which makes it difficult to implement in practical applications. To address these issues, we propose a multi-agent collaborative fast 3DGS surface reconstruction framework based on distributed learning for large-scale surface reconstruction. Specifically, we develop local model compression (LMC) and model aggregation schemes (MAS) to achieve high-quality surface representation of large scenes while reducing GPU memory consumption. Extensive experiments on Urban3d, MegaNeRF, and BlendedMVS demonstrate that our proposed method can achieve fast and scalable high-fidelity surface reconstruction and photorealistic rendering. Our project page is available at \url{https://gyy456.github.io/CoSurfGS}.
PolSAM: Polarimetric Scattering Mechanism Informed Segment Anything Model
Dec 17, 2024PolSAR data presents unique challenges due to its rich and complex characteristics. Existing data representations, such as complex-valued data, polarimetric features, and amplitude images, are widely used. However, these formats often face issues related to usability, interpretability, and data integrity. Most feature extraction networks for PolSAR are small, limiting their ability to capture features effectively. To address these issues, We propose the Polarimetric Scattering Mechanism-Informed SAM (PolSAM), an enhanced Segment Anything Model (SAM) that integrates domain-specific scattering characteristics and a novel prompt generation strategy. PolSAM introduces Microwave Vision Data (MVD), a lightweight and interpretable data representation derived from polarimetric decomposition and semantic correlations. We propose two key components: the Feature-Level Fusion Prompt (FFP), which fuses visual tokens from pseudo-colored SAR images and MVD to address modality incompatibility in the frozen SAM encoder, and the Semantic-Level Fusion Prompt (SFP), which refines sparse and dense segmentation prompts using semantic information. Experimental results on the PhySAR-Seg datasets demonstrate that PolSAM significantly outperforms existing SAM-based and multimodal fusion models, improving segmentation accuracy, reducing data storage, and accelerating inference time. The source code and datasets will be made publicly available at \url{https://github.com/XAI4SAR/PolSAM}.