 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVGGT: Omni-Modality Driven Visual Geometry Grounded Transformer
Nov 14, 2025General 3D foundation models have started to lead the trend of unifying diverse vision tasks, yet most assume RGB-only inputs and ignore readily available geometric cues (e.g., camera intrinsics, poses, and depth maps). To address this issue, we introduce OmniVGGT, a novel framework that can effectively benefit from an arbitrary number of auxiliary geometric modalities during both training and inference. In our framework, a GeoAdapter is proposed to encode depth and camera intrinsics/extrinsics into a spatial foundation model. It employs zero-initialized convolutions to progressively inject geometric information without disrupting the foundation model's representation space. This design ensures stable optimization with negligible overhead, maintaining inference speed comparable to VGGT even with multiple additional inputs. Additionally, a stochastic multimodal fusion regimen is proposed, which randomly samples modality subsets per instance during training. This enables an arbitrary number of modality inputs during testing and promotes learning robust spatial representations instead of overfitting to auxiliary cues. Comprehensive experiments on monocular/multi-view depth estimation, multi-view stereo, and camera pose estimation demonstrate that OmniVGGT outperforms prior methods with auxiliary inputs and achieves state-of-the-art results even with RGB-only input. To further highlight its practical utility, we integrated OmniVGGT into vision-language-action (VLA) models. The enhanced VLA model by OmniVGGT not only outperforms the vanilla point-cloud-based baseline on mainstream benchmarks, but also effectively leverages accessible auxiliary inputs to achieve consistent gains on robotic tasks.
Radiant: Large-scale 3D Gaussian Rendering based on Hierarchical Framework
Dec 07, 2024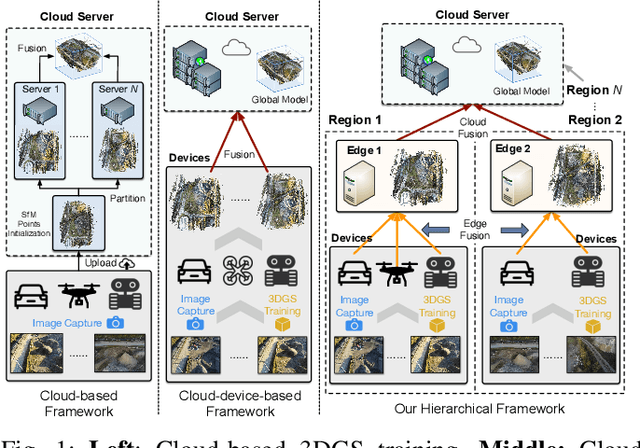
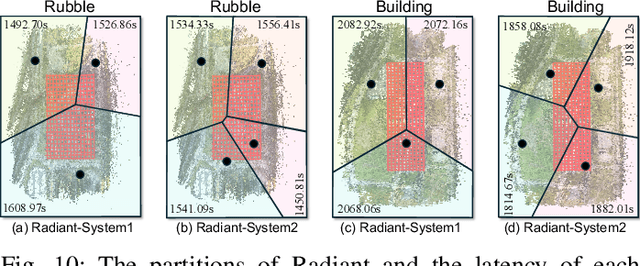
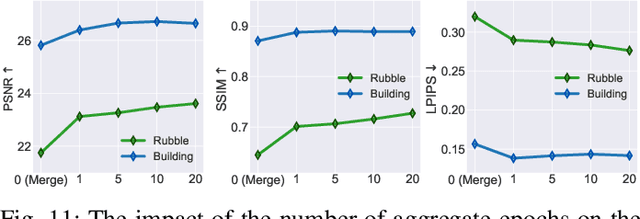

With the advancement of computer vision, the recently emerged 3D Gaussian Splatting (3DGS) has increasingly become a popular scene reconstruction algorithm due to its outstanding performance. Distributed 3DGS can efficiently utilize edge devices to directly train on the collected images, thereby offloading computational demands and enhancing efficiency. However, traditional distributed frameworks often overlook computational and communication challenges in real-world environments, hindering large-scale deployment and potentially posing privacy risks. In this paper, we propose Radiant, a hierarchical 3DGS algorithm designed for large-scale scene reconstruction that considers system heterogeneity, enhancing the model performance and training efficiency. Via extensive empirical study, we find that it is crucial to partition the regions for each edge appropriately and allocate varying camera positions to each device for image collection and training. The core of Radiant is partitioning regions based on heterogeneous environment information and allocating workloads to each device accordingly. Furthermore, we provide a 3DGS model aggregation algorithm that enhances the quality and ensures the continuity of models' boundaries. Finally, we develop a testbed, and experiments demonstrate that Radiant improved reconstruction quality by up to 25.7\% and reduced up to 79.6\% end-to-end latency.
DGTR: Distributed Gaussian Turbo-Reconstruction for Sparse-View Vast Scenes
Nov 20, 2024
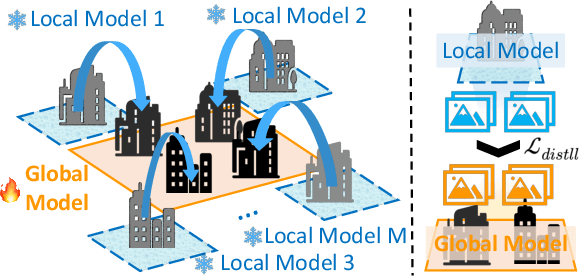


Novel-view synthesis (NVS) approaches play a critical role in vast scene reconstruction. However, these methods rely heavily on dense image inputs and prolonged training times, making them unsuitable where computational resources are limited. Additionally, few-shot methods often struggle with poor reconstruction quality in vast environments. This paper presents DGTR, a novel distributed framework for efficient Gaussian reconstruction for sparse-view vast scenes. Our approach divides the scene into regions, processed independently by drones with sparse image inputs. Using a feed-forward Gaussian model, we predict high-quality Gaussian primitives, followed by a global alignment algorithm to ensure geometric consistency. Synthetic views and depth priors are incorporated to further enhance training, while a distillation-based model aggregation mechanism enables efficient reconstruction. Our method achieves high-quality large-scale scene reconstruction and novel-view synthesis in significantly reduced training times, outperforming existing approaches in both speed and scalability. We demonstrate the effectiveness of our framework on vast aerial scenes, achieving high-quality results within minutes. Code will released on our [https://3d-aigc.github.io/DGTR].
Arena: A Patch-of-Interest ViT Inference Acceleration System for Edge-Assisted Video Analytics
Apr 14, 2024The advent of edge computing has made real-time intelligent video analytics feasible. Previous works, based on traditional model architecture (e.g., CNN, RNN, etc.), employ various strategies to filter out non-region-of-interest content to minimize bandwidth and computation consumption but show inferior performance in adverse environments. Recently, visual foundation models based on transformers have shown great performance in adverse environments due to their amazing generalization capability. However, they require a large amount of computation power, which limits their applications in real-time intelligent video analytics. In this paper, we find visual foundation models like Vision Transformer (ViT) also have a dedicated acceleration mechanism for video analytics. To this end, we introduce Arena, an end-to-end edge-assisted video inference acceleration system based on ViT. We leverage the capability of ViT that can be accelerated through token pruning by only offloading and feeding Patches-of-Interest (PoIs) to the downstream models. Additionally, we employ probability-based patch sampling, which provides a simple but efficient mechanism for determining PoIs where the probable locations of objects are in subsequent frames. Through extensive evaluations on public datasets, our findings reveal that Arena can boost inference speeds by up to $1.58\times$ and $1.82\times$ on average while consuming only 54% and 34% of the bandwidth, respectively, all with high inference accuracy.
MDENet: Multi-modal Dual-embedding Networks for Malware Open-set Recognition
May 02, 2023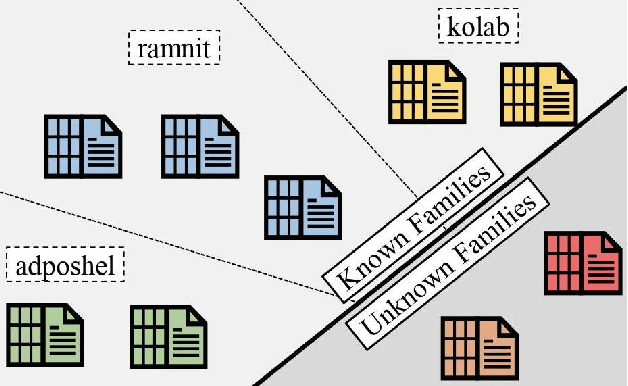
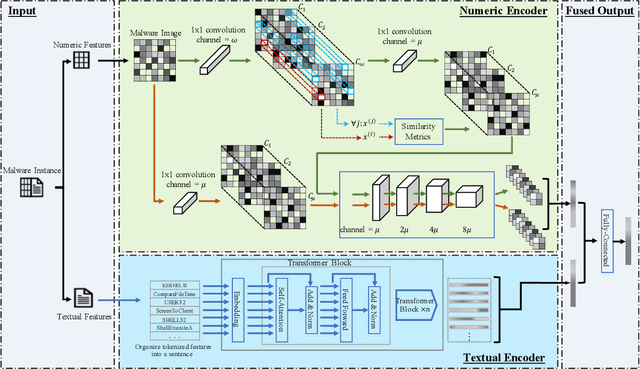
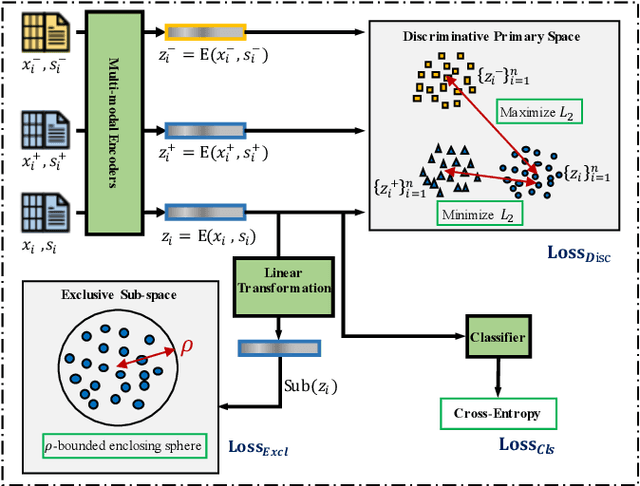
Malware open-set recognition (MOSR) aims at jointly classifying malware samples from known families and detect the ones from novel unknown families, respectively. Existing works mostly rely on a well-trained classifier considering the predicted probabilities of each known family with a threshold-based detection to achieve the MOSR. However, our observation reveals that the feature distributions of malware samples are extremely similar to each other even between known and unknown families. Thus the obtained classifier may produce overly high probabilities of testing unknown samples toward known families and degrade the model performance. In this paper, we propose the Multi-modal Dual-Embedding Networks, dubbed MDENet, to take advantage of comprehensive malware features (i.e., malware images and malware sentences) from different modalities to enhance the diversity of malware feature space, which is more representative and discriminative for down-stream recognition. Last, to further guarantee the open-set recognition, we dually embed the fused multi-modal representation into one primary space and an associated sub-space, i.e., discriminative and exclusive spaces, with contrastive sampling and rho-bounded enclosing sphere regularizations, which resort to classification and detection, respectively. Moreover, we also enrich our previously proposed large-scaled malware dataset MAL-100 with multi-modal characteristics and contribute an improved version dubbed MAL-100+. Experimental results on the widely used malware dataset Mailing and the proposed MAL-100+ demonstrate the effectiveness of our method.
A Coalition Formation Game Approach for Personalized Federated Learning
Feb 08, 2022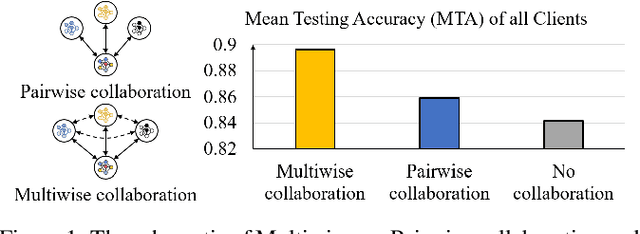

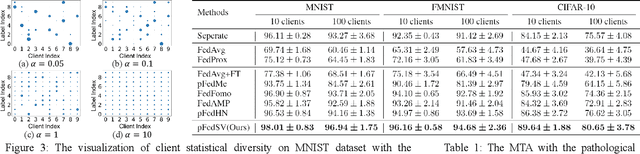
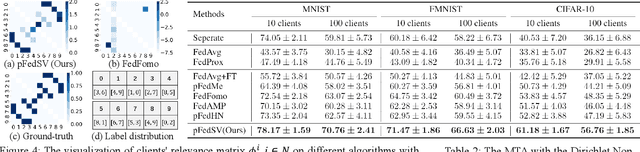
Facing the challenge of statistical diversity in client local data distribution, personalized federated learning (PFL) has become a growing research hotspot. Although the state-of-the-art methods with model similarity-based pairwise collaboration have achieved promising performance, they neglect the fact that model aggregation is essentially a collaboration process within the coalition, where the complex multiwise influences take place among clients. In this paper, we first apply Shapley value (SV) from coalition game theory into the PFL scenario. To measure the multiwise collaboration among a group of clients on the personalized learning performance, SV takes their marginal contribution to the final result as a metric. We propose a novel personalized algorithm: pFedSV, which can 1. identify each client's optimal collaborator coalition and 2. perform personalized model aggregation based on SV. Extensive experiments on various datasets (MNIST, Fashion-MNIST, and CIFAR-10) are conducted with different Non-IID data settings (Pathological and Dirichlet). The results show that pFedSV can achieve superior personalized accuracy for each client, compared to the state-of-the-art benchmarks.
TFDPM: Attack detection for cyber-physical systems with diffusion probabilistic models
Dec 20, 2021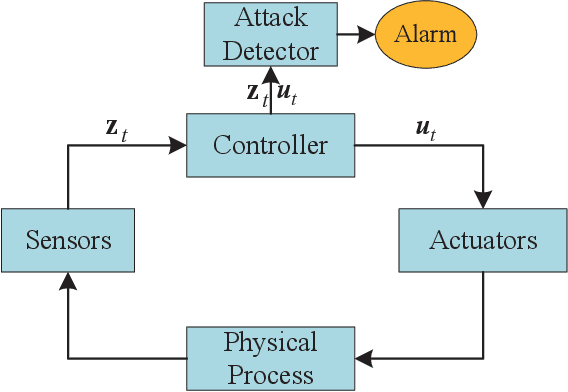

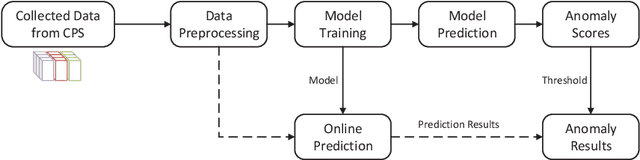
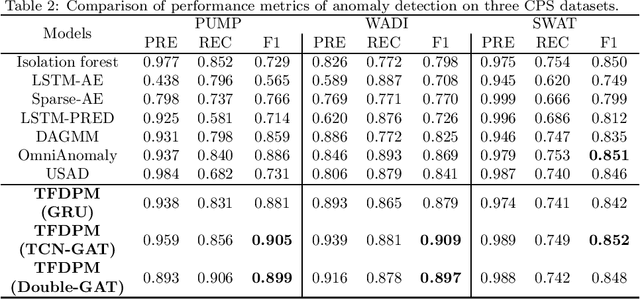
With the development of AIoT, data-driven attack detection methods for cyber-physical systems (CPSs) have attracted lots of attention. However, existing methods usually adopt tractable distributions to approximate data distributions, which are not suitable for complex systems. Besides, the correlation of the data in different channels does not attract sufficient attention. To address these issues, we use energy-based generative models, which are less restrictive on functional forms of the data distribution. In addition, graph neural networks are used to explicitly model the correlation of the data in different channels. In the end, we propose TFDPM, a general framework for attack detection tasks in CPSs. It simultaneously extracts temporal pattern and feature pattern given the historical data. Then extract features are sent to a conditional diffusion probabilistic model. Predicted values can be obtained with the conditional generative network and attacks are detected based on the difference between predicted values and observed values. In addition, to realize real-time detection, a conditional noise scheduling network is proposed to accelerate the prediction process. Experimental results show that TFDPM outperforms existing state-of-the-art attack detection methods. The noise scheduling network increases the detection speed by three times.
ScoreGrad: Multivariate Probabilistic Time Series Forecasting with Continuous Energy-based Generative Models
Jun 18, 2021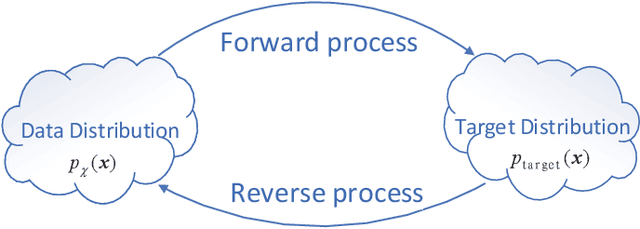
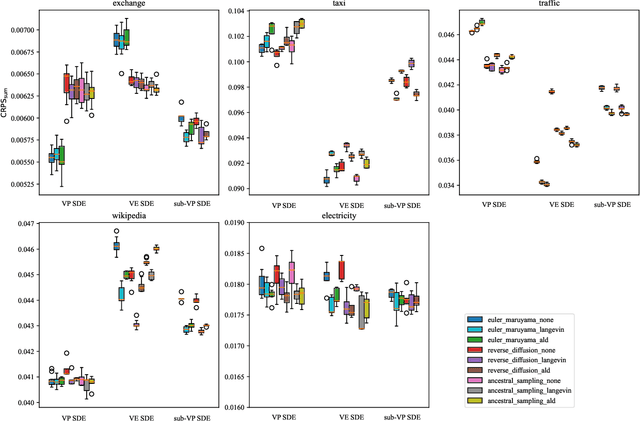
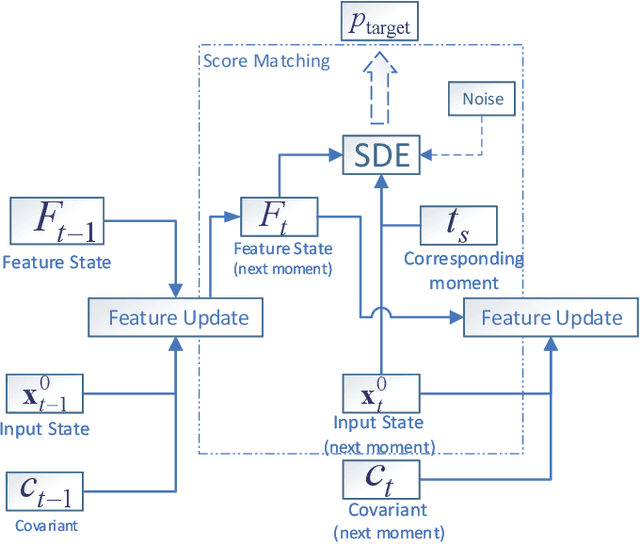
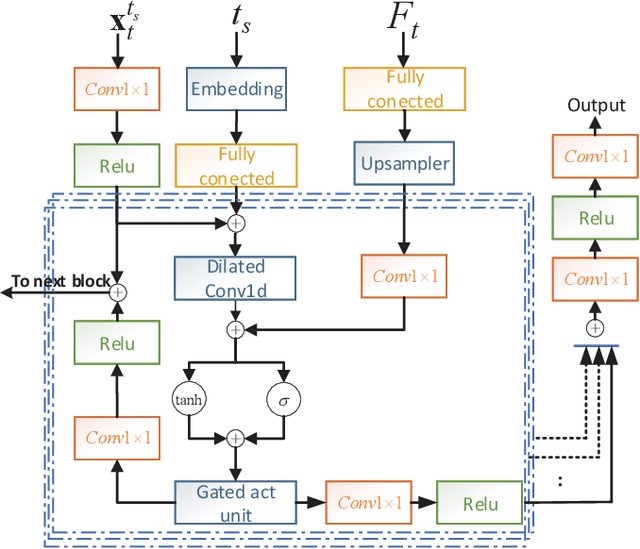
Multivariate time series prediction has attracted a lot of attention because of its wide applications such as intelligence transportation, AIOps. Generative models have achieved impressive results in time series modeling because they can model data distribution and take noise into consideration. However, many existing works can not be widely used because of the constraints of functional form of generative models or the sensitivity to hyperparameters. In this paper, we propose ScoreGrad, a multivariate probabilistic time series forecasting framework based on continuous energy-based generative models. ScoreGrad is composed of time series feature extraction module and conditional stochastic differential equation based score matching module. The prediction can be achieved by iteratively solving reverse-time SDE. To the best of our knowledge, ScoreGrad is the first continuous energy based generative model used for time series forecasting. Furthermore, ScoreGrad achieves state-of-the-art results on six real-world datasets. The impact of hyperparameters and sampler types on the performance are also explored. Code is available at https://github.com/yantijin/ScoreGradPred.