 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMTrack: End-to-End Trained Spiking Neural Networks for Multi-Object Tracking in RGB Videos
Aug 20, 2025Brain-inspired Spiking Neural Networks (SNNs) exhibit significant potential for low-power computation, yet their application in visual tasks remains largely confined to image classification, object detection, and event-based tracking. In contrast, real-world vision systems still widely use conventional RGB video streams, where the potential of directly-trained SNNs for complex temporal tasks such as multi-object tracking (MOT) remains underexplored. To address this challenge, we propose SMTrack-the first directly trained deep SNN framework for end-to-end multi-object tracking on standard RGB videos. SMTrack introduces an adaptive and scale-aware Normalized Wasserstein Distance loss (Asa-NWDLoss) to improve detection and localization performance under varying object scales and densities. Specifically, the method computes the average object size within each training batch and dynamically adjusts the normalization factor, thereby enhancing sensitivity to small objects. For the association stage, we incorporate the TrackTrack identity module to maintain robust and consistent object trajectories. Extensive evaluations on BEE24, MOT17, MOT20, and DanceTrack show that SMTrack achieves performance on par with leading ANN-based MOT methods, advancing robust and accurate SNN-based tracking in complex scenarios.
D$^{2}$MoE: Dual Routing and Dynamic Scheduling for Efficient On-Device MoE-based LLM Serving
Apr 17, 2025
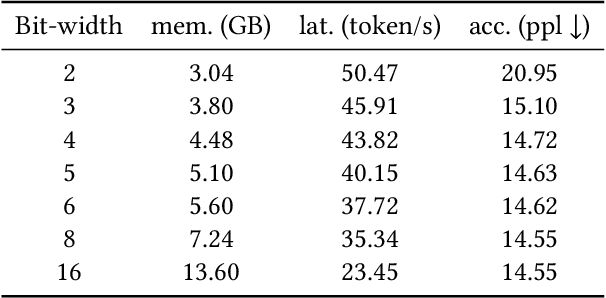


The mixture of experts (MoE) model is a sparse variant of large language models (LLMs), designed to hold a better balance between intelligent capability and computational overhead. Despite its benefits, MoE is still too expensive to deploy on resource-constrained edge devices, especially with the demands of on-device inference services. Recent research efforts often apply model compression techniques, such as quantization, pruning and merging, to restrict MoE complexity. Unfortunately, due to their predefined static model optimization strategies, they cannot always achieve the desired quality-overhead trade-off when handling multiple requests, finally degrading the on-device quality of service. These limitations motivate us to propose the D$^2$MoE, an algorithm-system co-design framework that matches diverse task requirements by dynamically allocating the most proper bit-width to each expert. Specifically, inspired by the nested structure of matryoshka dolls, we propose the matryoshka weight quantization (MWQ) to progressively compress expert weights in a bit-nested manner and reduce the required runtime memory. On top of it, we further optimize the I/O-computation pipeline and design a heuristic scheduling algorithm following our hottest-expert-bit-first (HEBF) principle, which maximizes the expert parallelism between I/O and computation queue under constrained memory budgets, thus significantly reducing the idle temporal bubbles waiting for the experts to load. Evaluations on real edge devices show that D$^2$MoE improves the overall inference throughput by up to 1.39$\times$ and reduces the peak memory footprint by up to 53% over the latest on-device inference frameworks, while still preserving comparable serving accuracy as its INT8 counterparts.
Gradient Diffusion: A Perturbation-Resilient Gradient Leakage Attack
Jul 07, 2024Recent years have witnessed the vulnerability of Federated Learning (FL) against gradient leakage attacks, where the private training data can be recovered from the exchanged gradients, making gradient protection a critical issue for the FL training process. Existing solutions often resort to perturbation-based mechanisms, such as differential privacy, where each participating client injects a specific amount of noise into local gradients before aggregating to the server, and the global distribution variation finally conceals the gradient privacy. However, perturbation is not always the panacea for gradient protection since the robustness heavily relies on the injected noise. This intuition raises an interesting question: \textit{is it possible to deactivate existing protection mechanisms by removing the perturbation inside the gradients?} In this paper, we present the answer: \textit{yes} and propose the Perturbation-resilient Gradient Leakage Attack (PGLA), the first attempt to recover the perturbed gradients, without additional access to the original model structure or third-party data. Specifically, we leverage the inherent diffusion property of gradient perturbation protection and construct a novel diffusion-based denoising model to implement PGLA. Our insight is that capturing the disturbance level of perturbation during the diffusion reverse process can release the gradient denoising capability, which promotes the diffusion model to generate approximate gradients as the original clean version through adaptive sampling steps. Extensive experiments demonstrate that PGLA effectively recovers the protected gradients and exposes the FL training process to the threat of gradient leakage, achieving the best quality in gradient denoising and data recovery compared to existing models. We hope to arouse public attention on PGLA and its defense.
Arena: A Patch-of-Interest ViT Inference Acceleration System for Edge-Assisted Video Analytics
Apr 14, 2024The advent of edge computing has made real-time intelligent video analytics feasible. Previous works, based on traditional model architecture (e.g., CNN, RNN, etc.), employ various strategies to filter out non-region-of-interest content to minimize bandwidth and computation consumption but show inferior performance in adverse environments. Recently, visual foundation models based on transformers have shown great performance in adverse environments due to their amazing generalization capability. However, they require a large amount of computation power, which limits their applications in real-time intelligent video analytics. In this paper, we find visual foundation models like Vision Transformer (ViT) also have a dedicated acceleration mechanism for video analytics. To this end, we introduce Arena, an end-to-end edge-assisted video inference acceleration system based on ViT. We leverage the capability of ViT that can be accelerated through token pruning by only offloading and feeding Patches-of-Interest (PoIs) to the downstream models. Additionally, we employ probability-based patch sampling, which provides a simple but efficient mechanism for determining PoIs where the probable locations of objects are in subsequent frames. Through extensive evaluations on public datasets, our findings reveal that Arena can boost inference speeds by up to $1.58\times$ and $1.82\times$ on average while consuming only 54% and 34% of the bandwidth, respectively, all with high inference accuracy.
ParsNets: A Parsimonious Orthogonal and Low-Rank Linear Networks for Zero-Shot Learning
Dec 21, 2023



This paper provides a novel parsimonious yet efficient design for zero-shot learning (ZSL), dubbed ParsNets, where we are interested in learning a composition of on-device friendly linear networks, each with orthogonality and low-rankness properties, to achieve equivalent or even better performance against existing deep models. Concretely, we first refactor the core module of ZSL, i.e., visual-semantics mapping function, into several base linear networks that correspond to diverse components of the semantic space, where the complex nonlinearity can be collapsed into simple local linearities. Then, to facilitate the generalization of local linearities, we construct a maximal margin geometry on the learned features by enforcing low-rank constraints on intra-class samples and high-rank constraints on inter-class samples, resulting in orthogonal subspaces for different classes and each subspace lies on a compact manifold. To enhance the model's adaptability and counterbalance over/under-fittings in ZSL, a set of sample-wise indicators is employed to select a sparse subset from these base linear networks to form a composite semantic predictor for each sample. Notably, maximal margin geometry can guarantee the diversity of features, and meanwhile, local linearities guarantee efficiency. Thus, our ParsNets can generalize better to unseen classes and can be deployed flexibly on resource-constrained devices. Theoretical explanations and extensive experiments are conducted to verify the effectiveness of the proposed method.
Attribute-Aware Representation Rectification for Generalized Zero-Shot Learning
Dec 01, 2023



Generalized Zero-shot Learning (GZSL) has yielded remarkable performance by designing a series of unbiased visual-semantics mappings, wherein, the precision relies heavily on the completeness of extracted visual features from both seen and unseen classes. However, as a common practice in GZSL, the pre-trained feature extractor may easily exhibit difficulty in capturing domain-specific traits of the downstream tasks/datasets to provide fine-grained discriminative features, i.e., domain bias, which hinders the overall recognition performance, especially for unseen classes. Recent studies partially address this issue by fine-tuning feature extractors, while may inevitably incur catastrophic forgetting and overfitting issues. In this paper, we propose a simple yet effective Attribute-Aware Representation Rectification framework for GZSL, dubbed $\mathbf{(AR)^{2}}$, to adaptively rectify the feature extractor to learn novel features while keeping original valuable features. Specifically, our method consists of two key components, i.e., Unseen-Aware Distillation (UAD) and Attribute-Guided Learning (AGL). During training, UAD exploits the prior knowledge of attribute texts that are shared by both seen/unseen classes with attention mechanisms to detect and maintain unseen class-sensitive visual features in a targeted manner, and meanwhile, AGL aims to steer the model to focus on valuable features and suppress them to fit noisy elements in the seen classes by attribute-guided representation learning. Extensive experiments on various benchmark datasets demonstrate the effectiveness of our method.
FreePIH: Training-Free Painterly Image Harmonization with Diffusion Model
Nov 25, 2023This paper provides an efficient training-free painterly image harmonization (PIH) method, dubbed FreePIH, that leverages only a pre-trained diffusion model to achieve state-of-the-art harmonization results. Unlike existing methods that require either training auxiliary networks or fine-tuning a large pre-trained backbone, or both, to harmonize a foreground object with a painterly-style background image, our FreePIH tames the denoising process as a plug-in module for foreground image style transfer. Specifically, we find that the very last few steps of the denoising (i.e., generation) process strongly correspond to the stylistic information of images, and based on this, we propose to augment the latent features of both the foreground and background images with Gaussians for a direct denoising-based harmonization. To guarantee the fidelity of the harmonized image, we make use of multi-scale features to enforce the consistency of the content and stability of the foreground objects in the latent space, and meanwhile, aligning both fore-/back-grounds with the same style. Moreover, to accommodate the generation with more structural and textural details, we further integrate text prompts to attend to the latent features, hence improving the generation quality. Quantitative and qualitative evaluations on COCO and LAION 5B datasets demonstrate that our method can surpass representative baselines by large margins.
Dissecting Arbitrary-scale Super-resolution Capability from Pre-trained Diffusion Generative Models
Jun 01, 2023



Diffusion-based Generative Models (DGMs) have achieved unparalleled performance in synthesizing high-quality visual content, opening up the opportunity to improve image super-resolution (SR) tasks. Recent solutions for these tasks often train architecture-specific DGMs from scratch, or require iterative fine-tuning and distillation on pre-trained DGMs, both of which take considerable time and hardware investments. More seriously, since the DGMs are established with a discrete pre-defined upsampling scale, they cannot well match the emerging requirements of arbitrary-scale super-resolution (ASSR), where a unified model adapts to arbitrary upsampling scales, instead of preparing a series of distinct models for each case. These limitations beg an intriguing question: can we identify the ASSR capability of existing pre-trained DGMs without the need for distillation or fine-tuning? In this paper, we take a step towards resolving this matter by proposing Diff-SR, a first ASSR attempt based solely on pre-trained DGMs, without additional training efforts. It is motivated by an exciting finding that a simple methodology, which first injects a specific amount of noise into the low-resolution images before invoking a DGM's backward diffusion process, outperforms current leading solutions. The key insight is determining a suitable amount of noise to inject, i.e., small amounts lead to poor low-level fidelity, while over-large amounts degrade the high-level signature. Through a finely-grained theoretical analysis, we propose the Perceptual Recoverable Field (PRF), a metric that achieves the optimal trade-off between these two factors. Extensive experiments verify the effectiveness, flexibility, and adaptability of Diff-SR, demonstrating superior performance to state-of-the-art solutions under diverse ASSR environments.
CaDM: Codec-aware Diffusion Modeling for Neural-enhanced Video Streaming
Nov 15, 2022Recent years have witnessed the dramatic growth of Internet video traffic, where the video bitstreams are often compressed and delivered in low quality to fit the streamer's uplink bandwidth. To alleviate the quality degradation, it comes the rise of Neural-enhanced Video Streaming (NVS), which shows great prospects to recover low-quality videos by mostly deploying neural super-resolution (SR) on the media server. Despite its benefit, we reveal that current mainstream works with SR enhancement have not achieved the desired rate-distortion trade-off between bitrate saving and quality restoration, due to: (1) overemphasizing the enhancement on the decoder side while omitting the co-design of encoder, (2) inherent limited restoration capacity to generate high-fidelity perceptual details, and (3) optimizing the compression-and-restoration pipeline from the resolution perspective solely, without considering color bit-depth. Aiming at overcoming these limitations, we are the first to conduct the encoder-decoder (i.e., codec) synergy by leveraging the visual-synthesis genius of diffusion models. Specifically, we present the Codec-aware Diffusion Modeling (CaDM), a novel NVS paradigm to significantly reduce streaming delivery bitrate while holding pretty higher restoration capacity over existing methods. First, CaDM improves the encoder's compression efficiency by simultaneously reducing resolution and color bit-depth of video frames. Second, CaDM provides the decoder with perfect quality enhancement by making the denoising diffusion restoration aware of encoder's resolution-color conditions. Evaluation on public cloud services with OpenMMLab benchmarks shows that CaDM significantly saves streaming bitrate by a nearly 100 times reduction over vanilla H.264 and achieves much better recovery quality (e.g., FID of 0.61) over state-of-the-art neural-enhancing methods.
Feature Correlation-guided Knowledge Transfer for Federated Self-supervised Learning
Nov 14, 2022To eliminate the requirement of fully-labeled data for supervised model training in traditional Federated Learning (FL), extensive attention has been paid to the application of Self-supervised Learning (SSL) approaches on FL to tackle the label scarcity problem. Previous works on Federated SSL generally fall into two categories: parameter-based model aggregation (i.e., FedAvg, applicable to homogeneous cases) or data-based feature sharing (i.e., knowledge distillation, applicable to heterogeneous cases) to achieve knowledge transfer among multiple unlabeled clients. Despite the progress, all of them inevitably rely on some assumptions, such as homogeneous models or the existence of an additional public dataset, which hinder the universality of the training frameworks for more general scenarios. Therefore, in this paper, we propose a novel and general method named Federated Self-supervised Learning with Feature-correlation based Aggregation (FedFoA) to tackle the above limitations in a communication-efficient and privacy-preserving manner. Our insight is to utilize feature correlation to align the feature mappings and calibrate the local model updates across clients during their local training process. More specifically, we design a factorization-based method to extract the cross-feature relation matrix from the local representations. Then, the relation matrix can be regarded as a carrier of semantic information to perform the aggregation phase. We prove that FedFoA is a model-agnostic training framework and can be easily compatible with state-of-the-art unsupervised FL methods. Extensive empirical experiments demonstrate that our proposed approach outperforms the state-of-the-art methods by a significant margin.